Gamma-World: Generative Multi-Agent World Modeling Beyond Two Players
Pith reviewed 2026-06-29 13:30 UTC · model grok-4.3
The pith
Simplex Rotary Agent Encoding and Sparse Hub Attention let world models generate consistent multi-agent videos that scale beyond two players.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
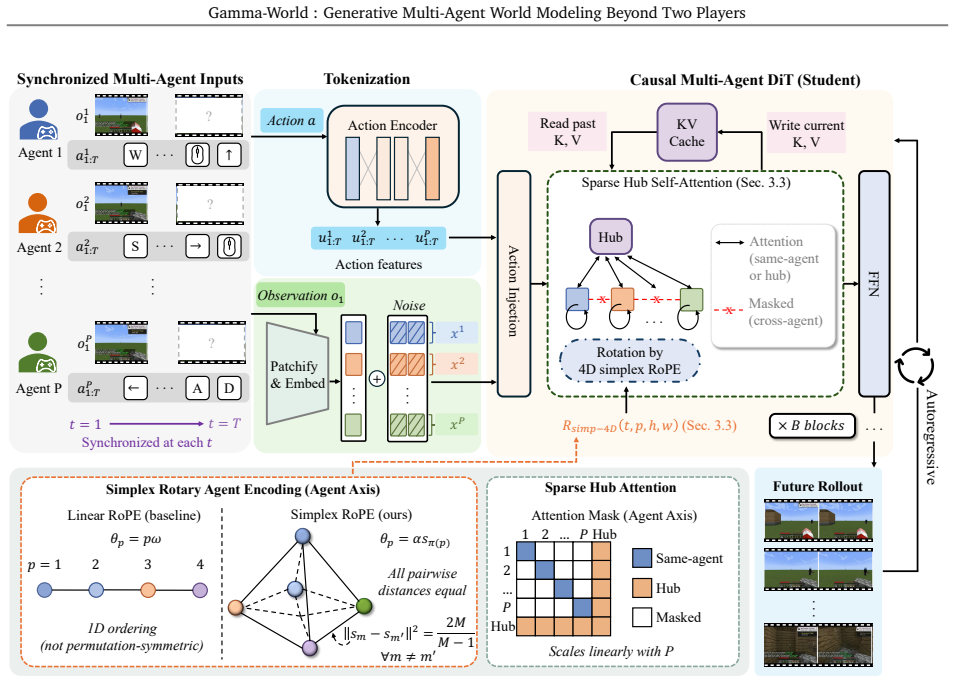
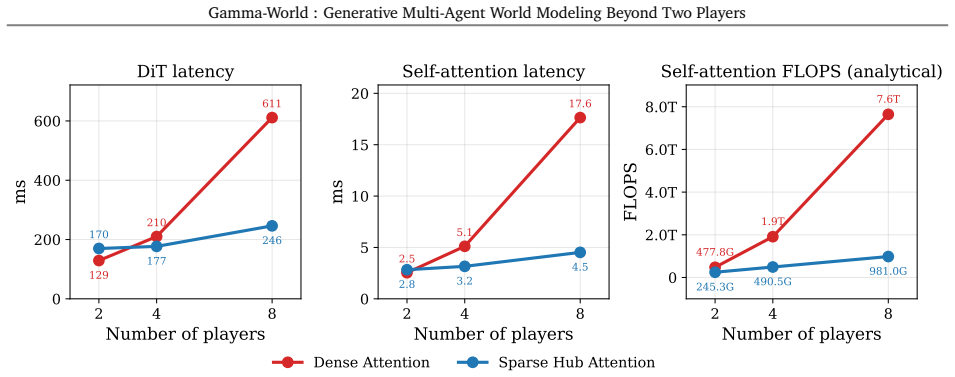
The central claim is that Simplex Rotary Agent Encoding, a parameter-free extension of 3D RoPE placing agents at vertices of a regular simplex, combined with Sparse Hub Attention that uses learnable hub tokens to mediate cross-agent communication, produces higher-fidelity, more controllable, and more consistent multi-agent video rollouts than slot-based or dense-attention baselines and generalizes from two to four players without retraining.
What carries the argument
Simplex Rotary Agent Encoding, a parameter-free extension of 3D RoPE that places each agent at a vertex of a regular simplex in rotary angle space to assign distinct phases while preserving permutation equivalence.
If this is right
- Video fidelity, action controllability, and inter-agent consistency all increase relative to slot-based and dense-attention baselines.
- The model generalizes from two-player training to four-player inference without additional training.
- Distillation into a causal student with KV caching yields real-time 24 FPS generation that remains responsive to new actions.
- Cross-agent attention cost drops from quadratic to linear in the number of agents.
Where Pith is reading between the lines
- The permutation symmetry could let the same model accept an arbitrary number of agents at inference time as long as memory permits.
- The hub-token pattern might transfer to other multi-object generative settings such as multi-character animation or scene layout prediction.
- If the encoding works, similar simplex constructions could replace learned embeddings in other symmetric multi-instance tasks.
Load-bearing premise
The simplex encoding and hub attention preserve temporal and perspective consistency across agents without any learned per-agent parameters or fixed agent ordering.
What would settle it
A controlled four-player rollout experiment that measures whether individual agent actions remain independently controllable and whether inter-agent visual consistency holds when the number of agents increases beyond the training distribution.
Figures




read the original abstract
World models for interactive video generation have largely focused on single-agent settings, where future observations are generated from a single control signal. However, many generated environments require multi-agent interaction: multiple players, robots, or embodied agents act simultaneously within a shared space. Scaling world models to such settings requires a principled multi-agent design: agents should remain independently controllable, permutation-symmetric, and support efficient inference while maintaining consistency across time and perspectives. In this paper, we present our generative multi-agent world model for interactive simulation. It introduces Simplex Rotary Agent Encoding, a parameter-free extension of 3D RoPE that represents agents as vertices of a regular simplex in rotary angle space. This gives each agent a distinct phase while making all agents permutation-equivalent, enabling scalable agent identity without learned per-slot identities or a fixed agent ordering. To avoid dense all-to-all attention across agents, we further propose Sparse Hub Attention, where learnable hub tokens mediate token interaction across agents, reducing cross-agent attention cost from quadratic to linear in the number of agents. For real-time rollout, we distill a full-context diffusion teacher into a causal student that generates temporal blocks sequentially with KV caching, enabling action-responsive generation at 24 FPS. Experiments in multiplayer virtual environments show that our model improves video fidelity, action controllability, and inter-agent consistency over slot-based and dense-attention baselines, while generalizing from two to four players without additional training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Gamma-World, a generative multi-agent world model for interactive video generation. It proposes Simplex Rotary Agent Encoding, a parameter-free extension of 3D RoPE that places agents at vertices of a regular simplex in rotary angle space to achieve permutation symmetry and distinct identities without learned per-agent parameters or fixed ordering. It also introduces Sparse Hub Attention to reduce cross-agent attention from quadratic to linear cost via learnable hub tokens, and a distillation method for causal real-time rollout at 24 FPS. The central empirical claim is that the model improves video fidelity, action controllability, and inter-agent consistency over slot-based and dense-attention baselines while generalizing from two-player to four-player settings without additional training.
Significance. If the generalization result holds with the claimed parameter-free properties, the work would meaningfully advance scalable multi-agent world models for interactive environments by addressing permutation symmetry and efficiency without per-agent learned components. The distillation to causal student for real-time generation is a practical contribution if supported by reproducible metrics.
major comments (2)
- [Abstract] Abstract: The claim that Simplex Rotary Agent Encoding enables generalization from two to four players without additional training or per-agent parameters is load-bearing for the central result, but the encoding dimension scales as (n-1) (1D simplex for n=2, 3D for n=4). If the underlying rotary embedding dimension is fixed (standard in transformer backbones), this requires either zero-padding, projection, or reconfiguration that is not shown to be invariant; the manuscript must explicitly demonstrate in §3 or the experiments how the same trained weights handle the changed subspace dimension without violating the 'parameter-free' and 'without additional training' conditions.
- [Experiments] Experiments section (referenced in abstract): No quantitative metrics, error bars, dataset details, ablation results, or baseline comparisons are supplied in the abstract or visible summary; the reported improvements in fidelity, controllability, and consistency cannot be assessed for statistical significance or effect size without these, weakening verification of the generalization claim.
minor comments (2)
- [Abstract] Abstract: The description of Sparse Hub Attention as reducing cost to linear in number of agents should include a brief complexity statement or reference to the relevant equation for clarity.
- Notation: The term 'Simplex Rotary Agent Encoding' is introduced without an immediate equation or diagram reference; adding a short formal definition early would aid readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. We address each major comment below and clarify the relevant sections of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that Simplex Rotary Agent Encoding enables generalization from two to four players without additional training or per-agent parameters is load-bearing for the central result, but the encoding dimension scales as (n-1) (1D simplex for n=2, 3D for n=4). If the underlying rotary embedding dimension is fixed (standard in transformer backbones), this requires either zero-padding, projection, or reconfiguration that is not shown to be invariant; the manuscript must explicitly demonstrate in §3 or the experiments how the same trained weights handle the changed subspace dimension without violating the 'parameter-free' and 'without additional training' conditions.
Authors: We appreciate the referee pointing out the need for explicit clarification on dimension handling. Section 3 defines Simplex Rotary Agent Encoding as an extension of 3D RoPE with the rotary dimension fixed at 3 to support up to 4 agents. For the 2-player case the 1D simplex is realized by using only the first rotary dimension while setting the other two to zero rotation; this embedding is performed identically at inference time with no additional parameters, projections, or retraining. The rotational invariance and permutation symmetry are preserved because the relative angles depend only on the active dimensions. We will add a formal statement and diagram in the revised §3 demonstrating that the same weights apply without reconfiguration. revision: yes
-
Referee: [Experiments] Experiments section (referenced in abstract): No quantitative metrics, error bars, dataset details, ablation results, or baseline comparisons are supplied in the abstract or visible summary; the reported improvements in fidelity, controllability, and consistency cannot be assessed for statistical significance or effect size without these, weakening verification of the generalization claim.
Authors: The full experiments section reports quantitative results (FID, PSNR/SSIM for fidelity; action accuracy and consistency scores with standard deviations over 5 random seeds), dataset statistics (100k multi-player trajectories), and ablations against slot-based and dense-attention baselines. The abstract summarizes these outcomes at a high level. To improve verifiability we will add a compact table of the primary metrics and the 2-to-4 player generalization numbers to the abstract or as a footnote in the revision. revision: partial
Circularity Check
No significant circularity; claims are empirically grounded architectural descriptions
full rationale
The provided abstract and context present Simplex Rotary Agent Encoding as a parameter-free extension of 3D RoPE representing agents as simplex vertices, Sparse Hub Attention as a linear-cost mediation mechanism, and the 2-to-4 player generalization as an experimental outcome from training on two-player data. No equations, self-definitional reductions, fitted-input predictions, or load-bearing self-citations are exhibited that would make any central claim equivalent to its inputs by construction. The architecture is described independently of the reported metrics (video fidelity, controllability, consistency), consistent with self-contained evaluation against baselines. This matches the default expectation for non-circular papers.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Rotary position embeddings can be extended from 1D/2D to 3D simplex angle space while preserving permutation symmetry
invented entities (2)
-
Simplex Rotary Agent Encoding
no independent evidence
-
Sparse Hub Attention
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
N. Agarwal, A. Ali, M. Bala, Y. Balaji, E. Barker, T. Cai, P. Chattopadhyay, Y. Chen, Y. Cui, Y. Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
A. Ali, J. Bai, M. Bala, Y. Balaji, A. Blakeman, T. Cai, J. Cao, T. Cao, E. Cha, Y.-W. Chao, et al. World simulation with video foundation models for physical ai.arXiv preprint arXiv:2511.00062, 2025. 2, 15
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Alonso, A
E. Alonso, A. Jelley, V. Micheli, A. Kanervisto, A. Storkey, T. Pearce, and F. Fleuret. Diffusion for world modeling: Visual details matter in atari.NeurIPS, 37:58757–58791, 2024. 2, 3
2024
-
[4]
A. Bar, G. Zhou, D. Tran, T. Darrell, and Y. LeCun. Navigation world models. InCVPR, pages 15791–15801, 2025. 3
2025
-
[5]
Bruce, M
J. Bruce, M. D. Dennis, A. Edwards, J. Parker-Holder, Y. Shi, E. Hughes, M. Lai, A. Mavalankar, R. Steigerwald, C. Apps, et al. Genie: Generative interactive environments. InForty-first International Conference on Machine Learning, 2024. 2
2024
-
[6]
B. Chen, D. Martí Monsó, Y. Du, M. Simchowitz, R. Tedrake, and V. Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024. 3, 5, 7
2024
-
[7]
H. Chen, Y. Zhang, X. Cun, M. Xia, X. Wang, C. Weng, and Y. Shan. Videocrafter2: Overcoming data limitations for high-quality video diffusion models. InCVPR, pages 7310–7320, 2024. 3
2024
-
[8]
Deepmind
G. Deepmind. Veo3 video model, 2025.https://deepmind.google/models/veo/. 3
2025
-
[9]
Introducing Multiverse: The first AI multiplayer world model
Enigma-team. Introducing Multiverse: The first AI multiplayer world model. Enigma Blog, 2025. 8, 9
2025
-
[10]
L. Fan, G. Wang, Y. Jiang, A. Mandlekar, Y. Yang, H. Zhu, A. Tang, D.-A. Huang, Y. Zhu, and A. Anandkumar. Minedojo: Building open-ended embodied agents with internet-scale knowledge.Advances in Neural Information Processing Systems, 35:18343–18362, 2022. 3
2022
-
[11]
Z. Feng, R. Xue, L. Yuan, Y. Yu, N. Ding, M. Liu, B. Gao, J. Sun, X. Zheng, and G. Wang. Multi-agent embodied ai: Advances and future directions.Science China Information Sciences, 69(5):151202, 2026. 2
2026
-
[12]
One Step Diffusion via Shortcut Models
K. Frans, D. Hafner, S. Levine, and P. Abbeel. One step diffusion via shortcut models.arXiv preprint arXiv:2410.12557,
work page internal anchor Pith review Pith/arXiv arXiv
- [13]
-
[14]
S. Gao, W. Liang, K. Zheng, A. Malik, S. Ye, S. Yu, W.-C. Tseng, Y. Dong, K. Mo, C.-H. Lin, et al. Dreamdojo: A generalist robot world model from large-scale human videos.arXiv preprint arXiv:2602.06949, 2026. 3
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Y. Gao, H. Guo, T. Hoang, W. Huang, L. Jiang, F. Kong, H. Li, J. Li, L. Li, X. Li, et al. Seedance 1.0: Exploring the boundaries of video generation models.arXiv preprint arXiv:2506.09113, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
10kh-realomin-opendata, 2025
Gen Robot. 10kh-realomin-opendata, 2025. 10
2025
-
[17]
Z. Geng, M. Deng, X. Bai, J. Z. Kolter, and K. He. Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Y. Guo, C. Yang, A. Rao, Z. Liang, Y. Wang, Y. Qiao, M. Agrawala, D. Lin, and B. Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. InICLR, 2024. 3
2024
-
[19]
X. He, C. Peng, Z. Liu, B. Wang, Y. Zhang, Q. Cui, F. Kang, B. Jiang, M. An, Y. Ren, et al. Matrix-game 2.0: An open-source real-time and streaming interactive world model.arXiv preprint arXiv:2508.13009, 2025. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Henschel, L
R. Henschel, L. Khachatryan, H. Poghosyan, D. Hayrapetyan, V. Tadevosyan, Z. Wang, S. Navasardyan, and H. Shi. Streamingt2v: Consistent, dynamic, and extendable long video generation from text. InCVPR, pages 2568–2577,
-
[21]
3 18 Gamma-World : Generative Multi-Agent World Modeling Beyond Two Players
-
[22]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 3
2020
-
[23]
A. Hu, L. Russell, H. Yeo, Z. Murez, G. Fedoseev, A. Kendall, J. Shotton, and G. Corrado. Gaia-1: A generative world model for autonomous driving.arXiv preprint arXiv:2309.17080, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
X. Huang, Z. Li, G. He, M. Zhou, and E. Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025. 3, 5, 7, 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
HunyuanWorld
T. HunyuanWorld. Hy-world 1.5: A systematic framework for interactive world modeling with real-time latency and geometric consistency.arXiv preprint, 2025. 2, 3
2025
-
[26]
M. Kang, R. Zhang, C. Barnes, S. Paris, S. Kwak, J. Park, E. Shechtman, J.-Y. Zhu, and T. Park. Distilling diffusion models into conditional gans. InECCV, pages 428–447, 2024. 3
2024
-
[27]
J. Kim, J. Kang, J. Choi, and B. Han. Fifo-diffusion: Generating infinite videos from text without training.Advances in Neural Information Processing Systems, 37:89834–89868, 2024. 3
2024
-
[28]
W. Kong, Q. Tian, Z. Zhang, R. Min, Z. Dai, J. Zhou, J. Xiong, X. Li, B. Wu, J. Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Kling video model, 2024.https://klingai.com/global/
Kuaishou. Kling video model, 2024.https://klingai.com/global/. 3
2024
- [30]
- [31]
-
[32]
L. Li, Q. Zhang, Y. Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhu, et al. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026. 3
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
S. Li, Y. Gao, D. Sadigh, and S. Song. Unified video action model.arXiv preprint arXiv:2503.00200, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [34]
-
[35]
S. Lin, A. Wang, and X. Yang. Sdxl-lightning: Progressive adversarial diffusion distillation.arXiv preprint arXiv:2402.13929, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
S. Lin, X. Xia, Y. Ren, C. Yang, X. Xiao, and L. Jiang. Diffusion adversarial post-training for one-step video generation. InICML, 2025. 3
2025
- [37]
-
[38]
Lipman, R
Y. Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InICLR, 2023. 3, 4
2023
-
[39]
Y. Lu, Y. Ren, X. Xia, S. Lin, X. Wang, X. Xiao, A. J. Ma, X. Xie, and J.-H. Lai. Adversarial distribution matching for diffusion distillation towards efficient image and video synthesis. InICCV, pages 16818–16829, 2025. 3
2025
- [40]
-
[41]
Sora video model, 2024.https://sora.chatgpt.com/
OpenAI. Sora video model, 2024.https://sora.chatgpt.com/. 3
2024
-
[42]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InICCV, pages 4195–4205, 2023. 3, 4
2023
-
[43]
X. Ren, Y. Lu, T. Cao, R. Gao, S. Huang, A. Sabour, T. Shen, T. Pfaff, J. Z. Wu, R. Chen, et al. Cosmos-drive-dreams: Scalable synthetic driving data generation with world foundation models.arXiv preprint arXiv:2506.09042, 2025. 2 19 Gamma-World : Generative Multi-Agent World Modeling Beyond Two Players
-
[44]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022. 3
2022
-
[45]
Progressive Distillation for Fast Sampling of Diffusion Models
T. Salimans and J. Ho. Progressive distillation for fast sampling of diffusion models.arXiv preprint arXiv:2202.00512,
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Sauer, F
A. Sauer, F. Boesel, T. Dockhorn, A. Blattmann, P. Esser, and R. Rombach. Fast high-resolution image synthesis with latent adversarial diffusion distillation. InSIGGRAPH Asia, pages 1–11, 2024. 3
2024
-
[47]
Sauer, D
A. Sauer, D. Lorenz, A. Blattmann, and R. Rombach. Adversarial diffusion distillation. InECCV, pages 87–103, 2024. 3
2024
- [48]
-
[49]
Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations. InICLR, 2021. 3
2021
-
[50]
J. Su, M. Ahmed, Y. Lu, S. Pan, W. Bo, and Y. Liu. Roformer: Enhanced transformer with rotary position embedding. Neurocomputing, 568:127063, 2024. 5
2024
-
[51]
W. Sun, H. Zhang, H. Wang, J. Wu, Z. Wang, Z. Wang, Y. Wang, J. Zhang, T. Wang, and C. Guo. Worldplay: Towards long-term geometric consistency for real-time interactive world model.arXiv preprint, 2025. 2, 3
2025
-
[52]
Diffusion Models Are Real-Time Game Engines
D. Valevski, Y. Leviathan, M. Arar, and S. Fruchter. Diffusion models are real-time game engines.arXiv preprint arXiv:2408.14837, 2024. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
Z. Wang, C. Lu, Y. Wang, F. Bao, C. Li, H. Su, and J. Zhu. Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation.NeurIPS, 36:8406–8441, 2023. 3
2023
-
[55]
Video models are zero-shot learners and reasoners
T. Wiedemer, Y. Li, P. Vicol, S. S. Gu, N. Matarese, K. Swersky, B. Kim, P. Jaini, and R. Geirhos. Video models are zero-shot learners and reasoners.arXiv preprint arXiv:2509.20328, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [56]
-
[57]
Learning Interactive Real-World Simulators
M.Yang, Y.Du, K.Ghasemipour, J.Tompson, D.Schuurmans, andP.Abbeel. Learninginteractivereal-worldsimulators. arXiv preprint arXiv:2310.06114, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
Z. Yang, Y. Chen, J. Wang, S. Manivasagam, W.-C. Ma, A. J. Yang, and R. Urtasun. Unisim: A neural closed-loop sensor simulator. InCVPR, pages 1389–1399, 2023. 3
2023
-
[59]
Z. Yang, J. Teng, W. Zheng, M. Ding, S. Huang, J. Xu, Y. Yang, W. Hong, X. Zhang, G. Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer. InICLR, 2024. 3
2024
-
[60]
S. Ye, Y. Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y. L. Tan, C. Zhu, J. Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026. 3
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[61]
T. Yin, M. Gharbi, T. Park, R. Zhang, E. Shechtman, F. Durand, and B. Freeman. Improved distribution matching distillation for fast image synthesis.NeurIPS, 37:47455–47487, 2024. 3
2024
-
[62]
T. Yin, M. Gharbi, R. Zhang, E. Shechtman, F. Durand, W. T. Freeman, and T. Park. One-step diffusion with distribution matching distillation. InCVPR, pages 6613–6623, 2024. 3, 8, 16
2024
-
[63]
T. Yin, Q. Zhang, R. Zhang, W. T. Freeman, F. Durand, E. Shechtman, and X. Huang. From slow bidirectional to fast autoregressive video diffusion models. InCVPR, pages 22963–22974, 2025. 3, 7 20 Gamma-World : Generative Multi-Agent World Modeling Beyond Two Players
2025
- [64]
- [65]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.