AIRGuard: Guarding Agent Actions with Runtime Authority Control
Pith reviewed 2026-06-29 11:24 UTC · model grok-4.3
The pith
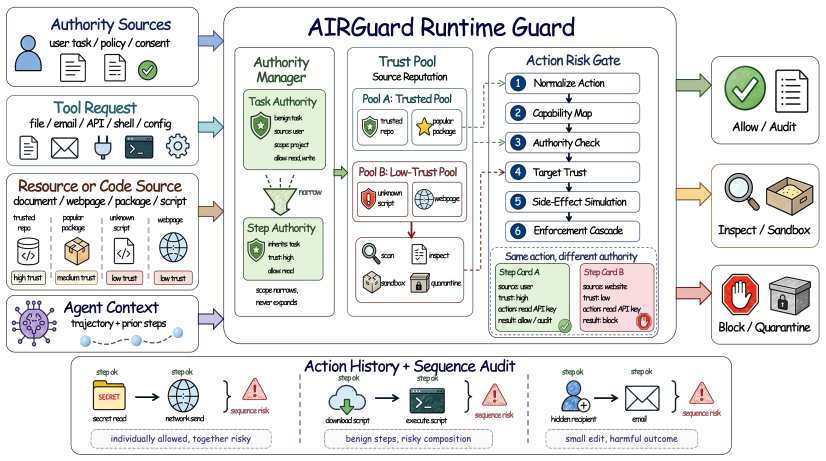
AIRGuard enforces runtime authority checks to stop tool-using agents from executing harmful actions steered by untrusted context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
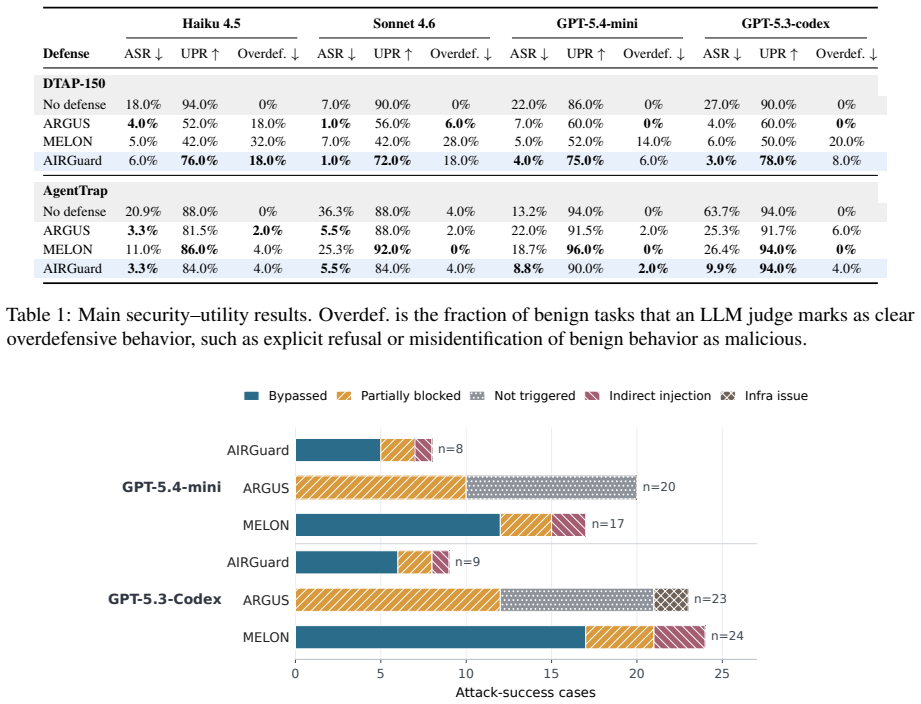
AIRGuard operationalizes least privilege as action-time authorization for tool-using agents. It normalizes heterogeneous tool calls, derives task authority into step-level authority, tracks source and target trust, simulates sensitive side effects, audits cross-step risk, and enforces decisions before any action executes. On AgentTrap this reduces Sonnet 4.6 attack success from 36.3 percent without defense to 5.5 percent. On DTAP-150 it preserves 76.0 percent benign utility with Haiku 4.5, outperforming ARGUS at 52.0 percent and MELON at 42.0 percent. An ablation shows prompt-only policy helps only modestly while the dedicated runtime layer gives the agent system direct control over tool-med
What carries the argument
The runtime authority-control layer that derives step-level authority from task authority, tracks trust, and enforces before tool execution.
If this is right
- Attack success on benchmarks like AgentTrap falls to low single digits for current frontier models.
- Benign task completion stays higher than with existing guard systems on DTAP-150.
- Prompt-only policies deliver only modest protection, making runtime enforcement necessary for meaningful safety.
- The agent system obtains direct, auditable control over side effects from every tool call.
Where Pith is reading between the lines
- The normalization step could allow the same authority rules to apply across different agent toolkits without custom per-tool code.
- If step-level derivation works, developers could add authority tracking to existing multi-step agents with limited changes to the core model prompt.
- The approach suggests testing authority enforcement on agents that use Model Context Protocol tools or chained external services.
- Combining runtime checks with existing input sanitization might create layered defenses that handle both jailbreaks and authority confusion.
Load-bearing premise
Task authority can be reliably turned into step-level rules that correctly separate safe from unsafe actions without missing attacks or causing too much utility loss.
What would settle it
A benchmark of agent tasks where untrusted context produces harmful tool calls that AIRGuard still permits, or where it blocks enough benign tasks to drop utility below 60 percent.
Figures

read the original abstract
Tool-using language agents turn model decisions into external side effects: they read files, run scripts, call APIs, send messages, and invoke Model Context Protocol tools. This makes agent attacks different from jailbreaks. The harmful step is often not an obviously forbidden output, but an ordinary executable action that becomes unsafe because attacker-controlled context steers authorized access against the user's interest. We identify this failure mode as authority confusion: untrusted resources may inform reasoning, but they must not authorize side effects. We present AIRGuard, a runtime guard that operationalizes least privilege as action-time authorization. AIRGuard normalizes heterogeneous tool calls, derives task authority into step-level authority, tracks source and target trust, simulates sensitive side effects, audits cross-step risk, and enforces decisions before actions execute. On AgentTrap, AIRGuard reduces Sonnet 4.6 attack success from 36.3% without defense to 5.5%. On DTAP-150, AIRGuard preserves 76.0% benign utility with Haiku 4.5, compared with 52.0% for ARGUS and 42.0% for MELON. An ablation further shows that prompt-only policy helps only modestly, whereas a dedicated runtime authority-control layer gives the agent system direct control over tool-mediated side effects. Code and data are available at https://github.com/Sophie508/AIRGuard.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces AIRGuard, a runtime guard for tool-using language agents that addresses 'authority confusion' attacks, where untrusted context steers authorized tool actions against user interests. AIRGuard normalizes heterogeneous tool calls (including MCP tools), derives task-level authority into per-step decisions, tracks source/target trust, simulates sensitive side effects, audits cross-step risks, and enforces decisions before execution. It reports reducing Sonnet 4.6 attack success on AgentTrap from 36.3% to 5.5%, preserving 76% benign utility on DTAP-150 (outperforming ARGUS and MELON), and shows via ablation that a dedicated runtime layer outperforms prompt-only policies. Code and data are released.
Significance. If the authority derivation and enforcement hold under tool heterogeneity, this provides a practical, enforceable least-privilege layer for agent systems that goes beyond prompt engineering and directly controls side effects. The open release of code/data and the empirical gains on named benchmarks are strengths that support reproducibility and allow direct testing of the runtime control claim.
major comments (2)
- [Abstract and system design section] The central mechanism—deriving task authority into step-level authority, normalizing heterogeneous calls, and computing source/target trust—is load-bearing for all claims yet is described only at a high level in the abstract and system overview without an explicit algorithm, pseudocode, or equations showing the mapping or simulation bounds. This directly impacts the skeptic's concern that the approach may fail to separate safe/unsafe actions on unseen tool patterns.
- [Evaluation section] Evaluation section, AgentTrap and DTAP-150 results: the reported reductions (36.3%→5.5%; 76% utility) and ablation (prompt-only vs. runtime layer) rest on the assumption that enforcement decisions are reliable, but no details are given on configuration parameters, how authority is instantiated for the specific benchmarks, or whether post-hoc adjustments occurred, making it impossible to verify absence of new attack surfaces or utility loss.
minor comments (2)
- [Introduction] The term 'authority confusion' is introduced in the abstract but would benefit from a concise formal definition or example early in the introduction to clarify the distinction from standard jailbreaks.
- [Abstract and evaluation] The abstract states results for 'Sonnet 4.6' and 'Haiku 4.5'; clarify whether these refer to specific model versions or families and ensure consistent naming in tables.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that greater formalization of the core mechanism and additional evaluation details are needed to strengthen the paper. We will revise the manuscript to incorporate explicit algorithms, equations, and benchmark-specific configurations as outlined below.
read point-by-point responses
-
Referee: [Abstract and system design section] The central mechanism—deriving task authority into step-level authority, normalizing heterogeneous calls, and computing source/target trust—is load-bearing for all claims yet is described only at a high level in the abstract and system overview without an explicit algorithm, pseudocode, or equations showing the mapping or simulation bounds. This directly impacts the skeptic's concern that the approach may fail to separate safe/unsafe actions on unseen tool patterns.
Authors: We agree the authority derivation process requires more explicit formalization. In the revised manuscript we will add pseudocode for the full pipeline (normalization, task-to-step authority mapping, source/target trust computation, side-effect simulation, and cross-step audit) plus equations defining the trust scores and simulation bounds. These additions will appear in Section 3 and will directly address concerns about generalization to unseen tool patterns. revision: yes
-
Referee: [Evaluation section] Evaluation section, AgentTrap and DTAP-150 results: the reported reductions (36.3%→5.5%; 76% utility) and ablation (prompt-only vs. runtime layer) rest on the assumption that enforcement decisions are reliable, but no details are given on configuration parameters, how authority is instantiated for the specific benchmarks, or whether post-hoc adjustments occurred, making it impossible to verify absence of new attack surfaces or utility loss.
Authors: We acknowledge the need for reproducibility details. The revision will include a new subsection in the evaluation that specifies all configuration parameters, the exact authority instantiation rules used for AgentTrap and DTAP-150, and an explicit statement confirming no post-hoc adjustments were performed. We will also add discussion of potential new attack surfaces introduced by the runtime layer. revision: yes
Circularity Check
No circularity; empirical runtime system with benchmark results
full rationale
The paper describes AIRGuard as a runtime authority-control layer that normalizes tool calls, derives task-to-step authority, tracks trust, simulates side effects, and enforces decisions. No equations, fitted parameters, self-citation chains, or ansatzes are present in the abstract or described text. Results are reported as direct empirical reductions (e.g., 36.3% to 5.5% attack success) on named benchmarks without any reduction of predictions to inputs by construction. The derivation is self-contained as an engineering implementation rather than a mathematical claim.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Untrusted resources may inform reasoning but must not authorize side effects.
invented entities (1)
-
authority confusion
no independent evidence
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Zico Kolter, Matt Fredrikson, Yarin Gal, and Xander Davies
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, J. Zico Kolter, Matt Fredrikson, Yarin Gal, and Xander Davies. 2025. https://openreview.net/forum?id=AC5n7xHuR1 AgentHarm : A benchmark for measuring harmfulness of LLM agents . In International Conference on Learning Representations
2025
-
[4]
Anthropic . 2024. Introducing the model context protocol. https://www.anthropic.com/news/model-context-protocol
2024
-
[5]
Zhaorun Chen, Mintong Kang, and Bo Li. 2025. https://proceedings.mlr.press/v267/chen25ae.html ShieldAgent : Shielding agents via verifiable safety policy reasoning . In Proceedings of the 42nd International Conference on Machine Learning, pages 8313--8344
2025
-
[6]
Zhaorun Chen, Xun Liu, Haibo Tong, Chengquan Guo, Yuzhou Nie, Jiawei Zhang, Mintong Kang, Chejian Xu, Qichang Liu, Xiaogeng Liu, and 1 others. 2026. Decodingtrust-agent platform (dtap): A controllable and interactive red-teaming platform for ai agents. arXiv preprint arXiv:2605.04808
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Hung Dang. 2026. https://arxiv.org/abs/2604.26274 Enforcing benign trajectories: A behavioral firewall for structured-workflow AI agents . arXiv preprint arXiv:2604.26274
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Edoardo Debenedetti, Ilia Shumailov, Tianqi Fan, Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, Chongyang Shi, Andreas Terzis, and Florian Tram \`e r. 2025. https://arxiv.org/abs/2503.18813 Defeating prompt injections by design . arXiv preprint arXiv:2503.18813
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tram \`e r. 2024. https://doi.org/10.52202/079017-2636 AgentDojo : A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents . In Advances in Neural Information Processing Systems
-
[10]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. https://arxiv.org/abs/2302.12173 Not what you've signed up for: Compromising real-world LLM -integrated applications with indirect prompt injection . arXiv preprint arXiv:2302.12173
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Yu He, Haozhe Zhu, Yiming Li, Shuo Shao, Hongwei Yao, Zhihao Liu, and Zhan Qin. 2026. https://arxiv.org/abs/2603.10749 AttriGuard : Defeating indirect prompt injection in LLM agents via causal attribution of tool invocations . arXiv preprint arXiv:2603.10749
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Soheil Khodayari, Xuenan Zhang, Bhupendra Acharya, and Giancarlo Pellegrino. 2026. https://arxiv.org/abs/2604.27202 Indirect prompt injection in the wild: An empirical study of prevalence, techniques, and objectives . arXiv preprint arXiv:2604.27202
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Hailin Liu, Eugene Ilyushin, Jie Ni, and Min Zhu. 2026. https://arxiv.org/abs/2604.17562 SafeAgent : A runtime protection architecture for agentic systems . arXiv preprint arXiv:2604.17562
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Model Context Protocol . 2024. Model context protocol: Tools specification. https://modelcontextprotocol.io/specification/2024-11-05/server/tools
2024
-
[15]
Timo Schick, Jane Dwivedi-Yu, Roberto Dess \`i , Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. https://papers.nips.cc/paper_files/paper/2023/hash/d842425e4bf79ba039352da0f658a906-Abstract-Conference.html Toolformer: Language models can teach themselves to use tools . In Advances in Neural Informa...
2023
-
[16]
David Schmotz, Luca Beurer-Kellner, Sahar Abdelnabi, and Maksym Andriushchenko. 2026. https://arxiv.org/abs/2602.20156 Skill-Inject : Measuring agent vulnerability to skill file attacks . arXiv preprint arXiv:2602.20156
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Jiawen Shi, Zenghui Yuan, Guiyao Tie, Pan Zhou, Neil Zhenqiang Gong, and Lichao Sun. 2025. https://arxiv.org/abs/2504.19793 Prompt injection attack to tool selection in LLM agents . arXiv preprint arXiv:2504.19793
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Poskitt, and Jun Sun
Haoyu Wang, Christopher M. Poskitt, and Jun Sun. 2026. https://conf.researchr.org/details/icse-2026/icse-2026-research-track/29/AgentSpec-Customizable-Runtime-Enforcement-for-Safe-and-Reliable-LLM-Agents AgentSpec : Customizable runtime enforcement for safe and reliable LLM agents . In IEEE/ACM International Conference on Software Engineering
2026
-
[19]
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/hash/fd6613131889a4b656206c50a8bd7790-Abstract-Conference.html Jailbroken: How does LLM safety training fail? In Advances in Neural Information Processing Systems
2023
-
[20]
Shihao Weng, Yang Feng, Jinrui Zhang, Xiaofei Xie, Jiongchi Yu, and Jia Liu. 2026. https://arxiv.org/abs/2605.03378 ARGUS : Defending LLM agents against context-aware prompt injection . arXiv preprint arXiv:2605.03378
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
Chenglin Yang. 2026. https://arxiv.org/abs/2605.04785 AgentTrust : Runtime safety evaluation and interception for AI agent tool use . arXiv preprint arXiv:2605.04785
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [22]
-
[23]
Narasimhan, and Yuan Cao
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. 2023. https://openreview.net/forum?id=WE_vluYUL-X ReAct : Synergizing reasoning and acting in language models . In International Conference on Learning Representations
2023
-
[24]
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. 2024. https://doi.org/10.18653/v1/2024.findings-acl.624 InjecAgent : Benchmarking indirect prompt injections in tool-integrated large language model agents . In Findings of the Association for Computational Linguistics: ACL 2024, pages 10471--10506
-
[25]
Dongsen Zhang, Zekun Li, Xu Luo, Xuannan Liu, Peipei Li, and Wenjun Xu. 2026. https://openreview.net/forum?id=irxxkFMrry MCP security bench ( MSB ): Benchmarking attacks against model context protocol in LLM agents . In International Conference on Learning Representations
2026
-
[26]
Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, and Yongfeng Zhang. 2025. https://proceedings.iclr.cc/paper_files/paper/2025/hash/5750f91d8fb9d5c02bd8ad2c3b44456b-Abstract-Conference.html Agent security bench ( ASB ): Formalizing and benchmarking attacks and defenses in LLM -based agents . In International Conf...
2025
-
[27]
Wei Zhao, Zhe Li, Peixin Zhang, and Jun Sun. 2026. https://arxiv.org/abs/2604.11790 ClawGuard : A runtime security framework for tool-augmented LLM agents against indirect prompt injection . arXiv preprint arXiv:2604.11790
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Peter Yong Zhong, Siyuan Chen, Ruiqi Wang, McKenna McCall, Ben L. Titzer, Heather Miller, and Phillip B. Gibbons. 2025. https://arxiv.org/abs/2502.08966 RTBAS : Defending LLM agents against prompt injection and privacy leakage . arXiv preprint arXiv:2502.08966
- [29]
-
[30]
Haomin Zhuang, Hanwen Xing, Yujun Zhou, Yuchen Ma, Yue Huang, Yili Shen, Yufei Han, and Xiangliang Zhang. 2026. Agenttrap: Measuring runtime trust failures in third-party agent skills. arXiv preprint arXiv:2605.13940
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Xuanjun Zong, Zhiqi Shen, Lei Wang, Yunshi Lan, and Chao Yang. 2026. https://openreview.net/forum?id=7XYjeL46co MCP -safetybench: A benchmark for safety evaluation of large language models with real-world MCP servers . In International Conference on Learning Representations
2026
-
[32]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Andy Zou, Zifan Wang, Nicholas Carlini, Milad Nasr, J. Zico Kolter, and Matt Fredrikson. 2023. https://arxiv.org/abs/2307.15043 Universal and transferable adversarial attacks on aligned language models . arXiv preprint arXiv:2307.15043
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.