HLL: Can Agents Cross Humanity's Last Line of Verification?
Pith reviewed 2026-06-28 14:55 UTC · model grok-4.3
The pith
Current multimodal agents remain brittle at the human-substitution boundary in CAPTCHA verifications.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
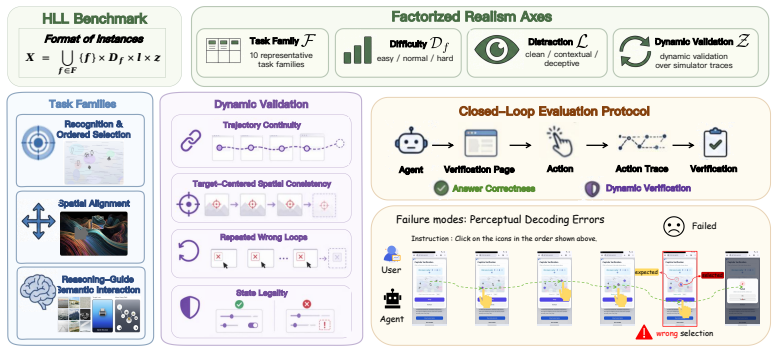
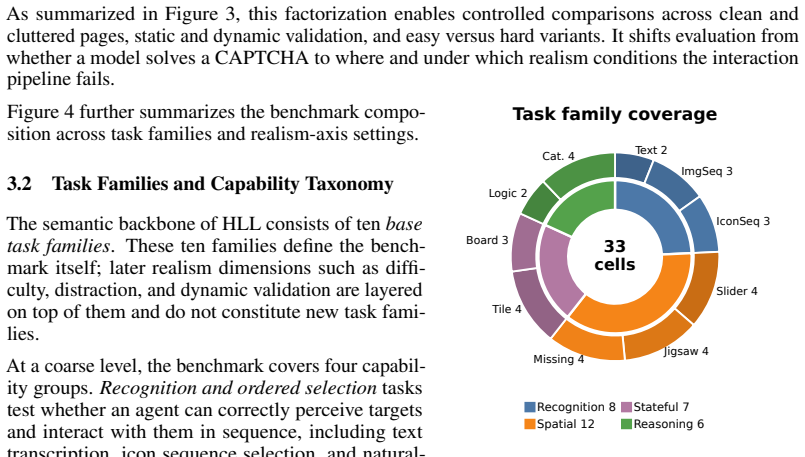
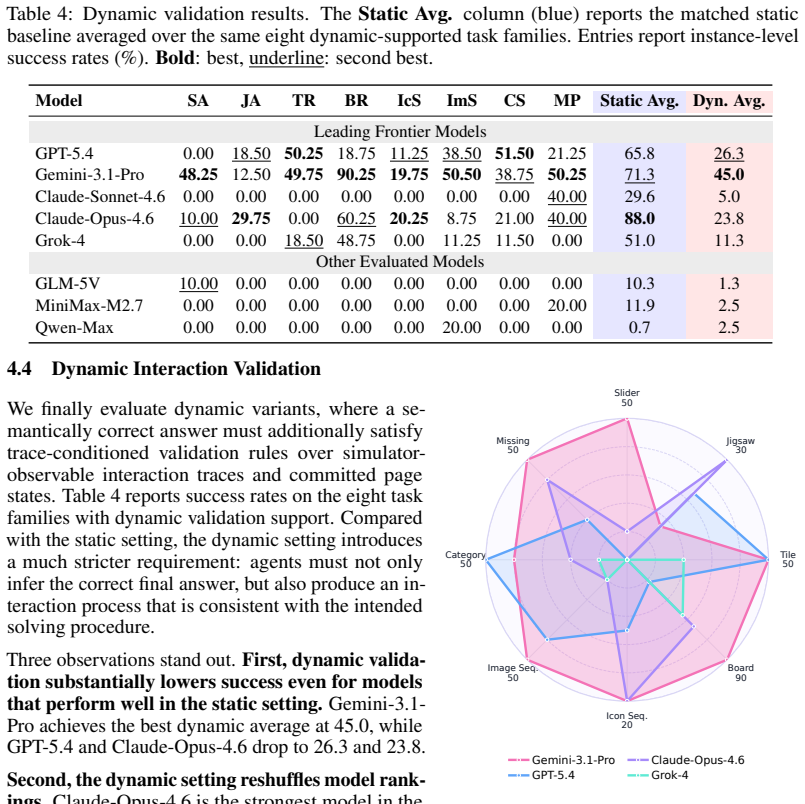
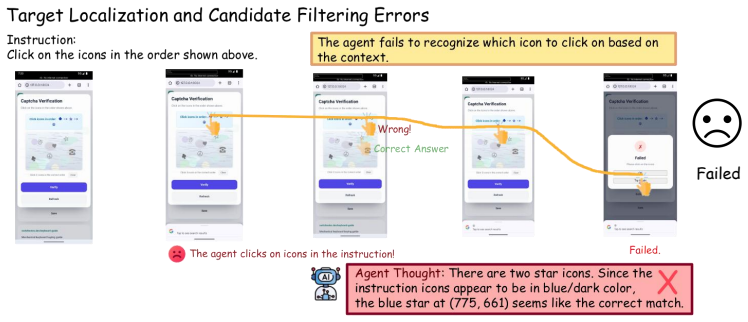
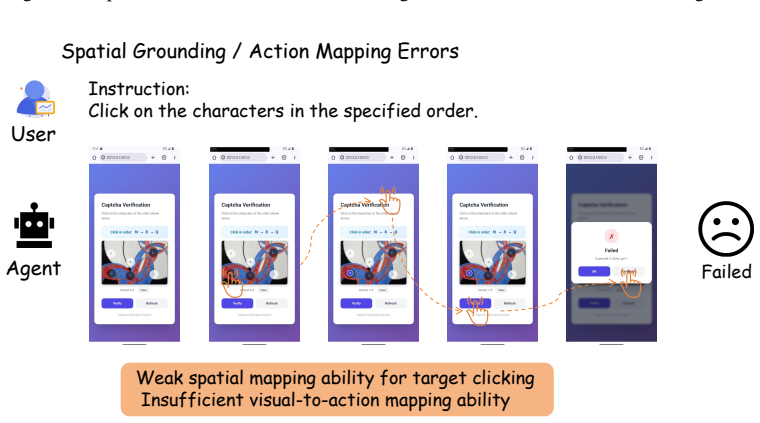
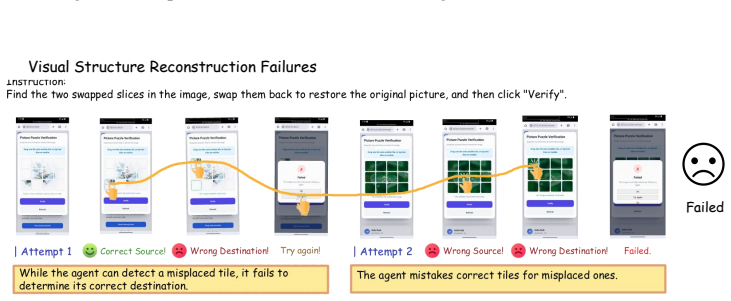
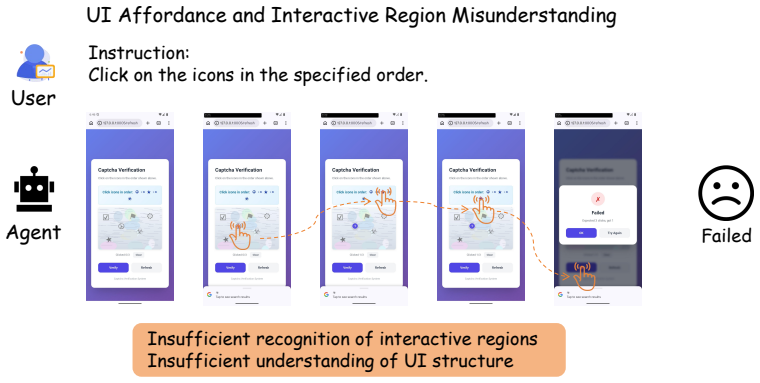
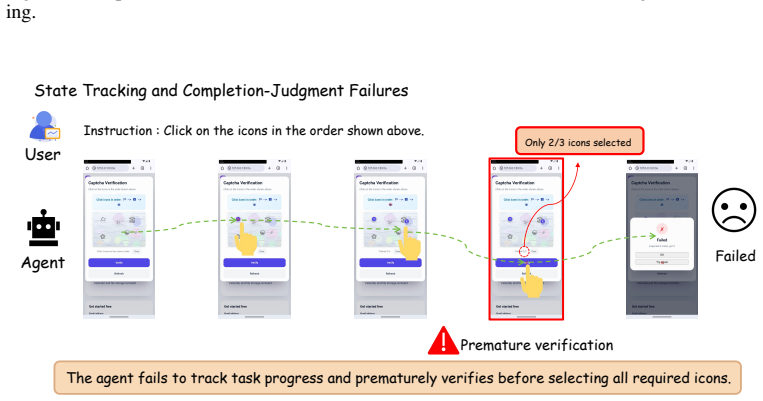
HLL is a controlled benchmark that uses interactive CAPTCHA verification to evaluate whether agents can cross the human-verification boundary through grounded, human-like interaction rather than recognition alone. When eight frontier multimodal agents are tested in a closed-loop GUI environment, performance varies sharply across verification types, degrades under realistic interface conditions such as cluttered webpages and harder task variants, and drops further when correct answers must be supported by valid action traces. The benchmark thereby exposes concrete gaps in localization, action calibration, state tracking, and process consistency.
What carries the argument
The HLL benchmark, which applies controlled realism stressors to diverse CAPTCHA interactions and requires trace-conditioned validation of the solving process.
If this is right
- Performance varies sharply across different verification types.
- Success rates degrade when agents encounter cluttered webpages or harder task variants.
- Performance drops further when agents must support correct answers with valid action traces.
- Gaps appear specifically in localization, action calibration, state tracking, and process consistency.
Where Pith is reading between the lines
- Agents that close these gaps could automate additional protected online actions that currently require human presence.
- Service providers may need to layer new verification methods on top of current CAPTCHAs if agent performance improves.
- The benchmark offers a repeatable testbed for measuring progress toward grounded GUI interaction beyond recognition tasks.
Load-bearing premise
The controlled CAPTCHA interactions and realism stressors in HLL sufficiently represent the actual human-verification boundaries that services place before protected actions in real deployments.
What would settle it
A trial in which one or more agents achieve consistently high success rates on every HLL verification type under all listed realism stressors while also generating action traces that correctly document the solving process.
Figures






read the original abstract
Multimodal agents are increasingly expected to operate interfaces on behalf of users, raising a central deployment question: can they truly substitute for humans in workflows that services deliberately protect against automation? CAPTCHA verification makes this question concrete. It is not merely a visual puzzle, but a human-verification boundary placed before account creation, content access, form submission, and other protected actions. We introduce \textbf{Humanity's Last Line of Verification (HLL)}, a controlled benchmark that uses interactive CAPTCHA verification to evaluate whether agents can cross this boundary through grounded, human-like interaction rather than recognition alone. HLL covers diverse CAPTCHA interactions and exposes agents to controlled realism stressors, including cluttered webpages, harder task variants, and trace-conditioned validation of the solving process. We evaluate eight frontier multimodal agents in a closed-loop GUI environment. The results show that current agents remain brittle at this human-substitution boundary: performance varies sharply across verification types, degrades under realistic interface conditions, and drops further when correct answers must be supported by valid action traces. By exposing gaps in localization, action calibration, state tracking, and process consistency, HLL provides a concrete testbed for measuring how close multimodal agents are to acting as human substitutes in protected real-world workflows. Our code is available at https://github.com/XinhaoS0101/HLL
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Humanity's Last Line of Verification (HLL), a controlled benchmark using interactive CAPTCHA tasks in a closed-loop GUI environment to test whether multimodal agents can substitute for humans at service-protected verification boundaries. It evaluates eight frontier agents, reporting sharp performance variation across verification types, degradation under realism stressors (cluttered pages, harder variants), and further drops when correct answers must be supported by valid action traces. The work claims this exposes gaps in localization, action calibration, state tracking, and process consistency, positioning HLL as a testbed for measuring progress toward human-like substitution in protected workflows. Code is released at the provided GitHub link.
Significance. If the experimental results are reproducible and the benchmark stressors adequately capture real deployment boundaries, the work provides a concrete, reproducible empirical testbed for a practically relevant capability gap in multimodal agents. The public code release is a clear strength that supports verification and extension by others. The contribution is primarily evaluative rather than theoretical, with no parameter-free derivations or machine-checked proofs.
major comments (2)
- [Abstract and §1] Abstract and §1: The central claim that HLL performance indicates closeness to human substitution in 'protected real-world workflows' is load-bearing on the untested assumption that the controlled CAPTCHA interactions, cluttered pages, harder variants, and trace-conditioned validation form a sufficient proxy. No correlation with live service outcomes, behavioral signals, device fingerprinting, or adaptive challenges is reported, leaving the extrapolation from benchmark brittleness to deployment boundaries unsupported.
- [§4 (Evaluation) and methods] §4 (Evaluation) and methods: The reported degradation patterns and trace-conditioned validation results rest on an experimental setup whose implementation details (GUI environment closure, action trace logging, and stressor application) are not described at a level that allows independent verification of the soundness 5.0 rating. This directly affects whether the observed brittleness can be taken as evidence for the human-substitution boundary claim.
minor comments (2)
- [Methods] Notation for 'trace-conditioned validation' is introduced without a formal definition or pseudocode; a short methods subsection would improve clarity.
- [Figures and Tables] Figure captions and table headers should explicitly state the number of trials per agent and per condition to allow readers to assess statistical reliability of the degradation patterns.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment point by point below, indicating where revisions will be made to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [Abstract and §1] Abstract and §1: The central claim that HLL performance indicates closeness to human substitution in 'protected real-world workflows' is load-bearing on the untested assumption that the controlled CAPTCHA interactions, cluttered pages, harder variants, and trace-conditioned validation form a sufficient proxy. No correlation with live service outcomes, behavioral signals, device fingerprinting, or adaptive challenges is reported, leaving the extrapolation from benchmark brittleness to deployment boundaries unsupported.
Authors: We agree that the manuscript reports no direct correlation between HLL results and live service outcomes or other real-world signals such as device fingerprinting. HLL is presented as a controlled proxy benchmark to isolate capabilities like localization and state tracking under verifiable conditions. To address the concern, we will revise the abstract and §1 to frame the contribution more narrowly as a testbed exposing specific gaps rather than a direct indicator of substitution readiness in production workflows. A new limitations subsection will explicitly note the absence of live-service validation and the scope of the proxy. revision: partial
-
Referee: [§4 (Evaluation) and methods] §4 (Evaluation) and methods: The reported degradation patterns and trace-conditioned validation results rest on an experimental setup whose implementation details (GUI environment closure, action trace logging, and stressor application) are not described at a level that allows independent verification of the soundness 5.0 rating. This directly affects whether the observed brittleness can be taken as evidence for the human-substitution boundary claim.
Authors: We acknowledge that the current methods description is insufficient for independent verification of the experimental setup. Although the full implementation is released at the provided GitHub repository, we will expand §4 and the methods section in the revision to include precise specifications of GUI environment closure, action trace logging format and validation procedure, and the exact mechanisms for applying each realism stressor. Additional pseudocode and environment configuration details will be added to support reproducibility. revision: yes
Circularity Check
Empirical benchmark evaluation with no derivation chain
full rationale
The paper presents HLL as an empirical benchmark for testing multimodal agents on interactive CAPTCHA tasks in a closed-loop GUI setting. It evaluates eight agents under controlled stressors and reports observed performance patterns without any equations, fitted parameters, predictions derived from prior results, or mathematical derivations. Claims rest on direct measurement of agent behavior rather than reduction to self-referential inputs or self-citations. No load-bearing steps match the enumerated circularity patterns; the work is self-contained as a benchmark study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption CAPTCHA verification constitutes a human-verification boundary that services deliberately protect against automation.
Reference graph
Works this paper leans on
-
[1]
Sensor-based continuous authentication of smartphones’ users using behavioral biometrics: A contemporary survey.IEEE Internet of Things Journal, 8(1):65–84, 2020
Mohammed Abuhamad, Ahmed Abusnaina, DaeHun Nyang, and David Mohaisen. Sensor-based continuous authentication of smartphones’ users using behavioral biometrics: A contemporary survey.IEEE Internet of Things Journal, 8(1):65–84, 2020
2020
-
[2]
Becaptcha: Detecting human behavior in smartphone interaction using multiple inbuilt sensors
Alejandro Acien, Aythami Morales, Julian Fierrez, Ruben Vera-Rodriguez, and Ivan Bartolome. Becaptcha: Detecting human behavior in smartphone interaction using multiple inbuilt sensors. arXiv preprint arXiv:2002.00918, 2020
-
[3]
Becaptcha: Behavioral bot detection using touchscreen and mobile sensors bench- marked on humidb.Engineering Applications of Artificial Intelligence, 98:104058, 2021
Alejandro Acien, Aythami Morales, Julian Fierrez, Ruben Vera-Rodriguez, and Oscar Delgado- Mohatar. Becaptcha: Behavioral bot detection using touchscreen and mobile sensors bench- marked on humidb.Engineering Applications of Artificial Intelligence, 98:104058, 2021
2021
-
[4]
A survey on captcha: Origin, applications and classification
Abdalnaser Muhammad Algwil. A survey on captcha: Origin, applications and classification. Journal of Basic Sciences, 36(1):1–37, 2023
2023
-
[5]
Claude opus 4.6 system card
Anthropic. Claude opus 4.6 system card. https://www-cdn.anthropic.com/ 14e4fb01875d2a69f646fa5e574dea2b1c0ff7b5.pdf, 2025
2025
-
[6]
Claude sonnet 4.6 system card
Anthropic. Claude sonnet 4.6 system card. https://www-cdn.anthropic.com/ bbd8ef16d70b7a1665f14f306ee88b53f686aa75.pdf, 2026
2026
-
[7]
Eugene Bagdasaryan, Tsung-Yin Hsieh, Ben Nassi, and Vitaly Shmatikov. Abusing images and sounds for indirect instruction injection in multi-modal llms.arXiv preprint arXiv:2307.10490, 2023
-
[8]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond.arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Text-based captcha strengths and weak- nesses
Elie Bursztein, Matthieu Martin, and John Mitchell. Text-based captcha strengths and weak- nesses. InProceedings of the 18th ACM conference on Computer and communications security, pages 125–138, 2011
2011
-
[10]
Building segmen- tation based human-friendly human interaction proofs (hips)
Kumar Chellapilla, Kevin Larson, Patrice Y Simard, and Mary Czerwinski. Building segmen- tation based human-friendly human interaction proofs (hips). InInternational Workshop on Human Interactive Proofs, pages 1–26. Springer, 2005
2005
-
[11]
Evaluating the robustness of multimodal agents against active environmental injection attacks
Yurun Chen, Xueyu Hu, Keting Yin, Juncheng Li, and Shengyu Zhang. Evaluating the robustness of multimodal agents against active environmental injection attacks. InProceedings of the 33rd ACM International Conference on Multimedia, pages 11648–11656, 2025
2025
-
[12]
Os-kairos: Adaptive interaction for mllm-powered gui agents
Pengzhou Cheng, Zheng Wu, Zongru Wu, Tianjie Ju, Aston Zhang, Zhuosheng Zhang, and Gongshen Liu. Os-kairos: Adaptive interaction for mllm-powered gui agents. InFindings of the Association for Computational Linguistics: ACL 2025, pages 6701–6725, 2025
2025
-
[13]
On the Measure of Intelligence
François Chollet. On the measure of intelligence.arXiv preprint arXiv:1911.01547, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[14]
Oedipus: Llm- enchanced reasoning captcha solver
Gelei Deng, Haoran Ou, Yi Liu, Jie Zhang, Tianwei Zhang, and Yang Liu. Oedipus: Llm- enchanced reasoning captcha solver. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, pages 6–20, 2025
2025
-
[15]
Mind2web: Towards a generalist agent for the web
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[16]
Illusioncaptcha: A captcha based on visual illusion
Ziqi Ding, Gelei Deng, Yi Liu, Junchen Ding, Jieshan Chen, Yulei Sui, and Yuekang Li. Illusioncaptcha: A captcha based on visual illusion. InProceedings of the ACM on Web Conference 2025, pages 3683–3691, 2025
2025
-
[17]
Touchalytics: On the applicability of touchscreen input as a behavioral biometric for continuous authentication
Mario Frank, Ralf Biedert, Eugene Ma, Ivan Martinovic, and Dawn Song. Touchalytics: On the applicability of touchscreen input as a behavioral biometric for continuous authentication. IEEE transactions on information forensics and security, 8(1):136–148, 2012. 11
2012
-
[18]
Research on the security of visual reasoning CAPTCHA
Yipeng Gao, Haichang Gao, Sainan Luo, Yang Zi, Shudong Zhang, Wenjie Mao, Ping Wang, Yulong Shen, and Jeff Yan. Research on the security of visual reasoning CAPTCHA. In30th USENIX Security Symposium (USENIX Security 21), pages 3291–3308, 2021
2021
-
[19]
Gemini 3.1 pro model card
Google DeepMind. Gemini 3.1 pro model card. https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-3-1-Pro-Model-Card.pdf, 2026
2026
-
[20]
Making the v in vqa matter: Elevating the role of image understanding in visual question answering
Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6904–6913, 2017
2017
-
[21]
Capture the bot: Using adversarial examples to improve captcha robustness to bot attacks.IEEE Intelligent Systems, 36(5):104–112, 2020
Dorjan Hitaj, Briland Hitaj, Sushil Jajodia, and Luigi V Mancini. Capture the bot: Using adversarial examples to improve captcha robustness to bot attacks.IEEE Intelligent Systems, 36(5):104–112, 2020
2020
-
[22]
GLM-5V-Turbo: Toward a Native Foundation Model for Multimodal Agents
Wenyi Hong, Xiaotao Gu, Ziyang Pan, Zhen Yang, Yuting Wang, Yue Wang, Yuanchang Yue, Yu Wang, Yanling Wang, Yan Wang, et al. Glm-5v-turbo: Toward a native foundation model for multimodal agents.arXiv preprint arXiv:2604.26752, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Cogagent: A visual language model for gui agents
Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. Cogagent: A visual language model for gui agents. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14281–14290, 2024
2024
-
[24]
Clevr: A diagnostic dataset for compositional language and elementary visual reasoning
Justin Johnson, Bharath Hariharan, Laurens Van Der Maaten, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. Clevr: A diagnostic dataset for compositional language and elementary visual reasoning. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2901–2910, 2017
2017
-
[25]
Mouse dynamics behavioral biometrics: A survey.ACM Computing Surveys, 56(6):1–33, 2024
Simon Khan, Charles Devlen, Michael Manno, and Daqing Hou. Mouse dynamics behavioral biometrics: A survey.ACM Computing Surveys, 56(6):1–33, 2024
2024
-
[26]
Visualwebarena: Evaluating multimodal agents on realistic visual web tasks
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Russ Salakhutdinov, and Daniel Fried. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 881–905, 2024
2024
-
[27]
Zeyi Liao, Lingbo Mo, Chejian Xu, Mintong Kang, Jiawei Zhang, Chaowei Xiao, Yuan Tian, Bo Li, and Huan Sun. Eia: Environmental injection attack on generalist web agents for privacy leakage.arXiv preprint arXiv:2409.11295, 2024
-
[28]
Visual spatial reasoning.Transactions of the Association for Computational Linguistics, 11:635–651, 2023
Fangyu Liu, Guy Emerson, and Nigel Collier. Visual spatial reasoning.Transactions of the Association for Computational Linguistics, 11:635–651, 2023
2023
-
[29]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents.arXiv preprint arXiv:2308.03688, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233. Springer, 2024
2024
-
[31]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Yaxin Luo, Zhaoyi Li, Jiacheng Liu, Jiacheng Cui, Xiaohan Zhao, and Zhiqiang Shen. Open captchaworld: A comprehensive web-based platform for testing and benchmarking multimodal llm agents.arXiv preprint arXiv:2505.24878, 2025
-
[33]
3dsrbench: A comprehensive 3d spatial reasoning benchmark
Wufei Ma, Haoyu Chen, Guofeng Zhang, Yu-Cheng Chou, Jieneng Chen, Celso de Melo, and Alan Yuille. 3dsrbench: A comprehensive 3d spatial reasoning benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6924–6934, 2025. 12
2025
-
[34]
Xinbei Ma, Yiting Wang, Yao Yao, Tongxin Yuan, Aston Zhang, Zhuosheng Zhang, and Hai Zhao. Caution for the environment: Multimodal llm agents are susceptible to environmental distractions.arXiv preprint arXiv:2408.02544, 2024
-
[35]
Minimax m2.7: Early echoes of self-evolution
MiniMax. Minimax m2.7: Early echoes of self-evolution. https://www.minimax.io/news/ minimax-m27-en, 2026. Accessed: 2026-04-30
2026
-
[36]
Zahra Noury and Mahdi Rezaei. Deep-captcha: a deep learning based captcha solver for vulnerability assessment.arXiv preprint arXiv:2006.08296, 2020
-
[37]
Gpt-5.4 thinking system card
OpenAI. Gpt-5.4 thinking system card. https://openai.com/index/ gpt-5-4-thinking-system-card/, 2026. Accessed: 2026-04-30
2026
-
[38]
WebCanvas: Benchmarking Web Agents in Online Environments
Yichen Pan, Dehan Kong, Sida Zhou, Cheng Cui, Yifei Leng, Bing Jiang, Hangyu Liu, Yanyi Shang, Shuyan Zhou, Tongshuang Wu, et al. Webcanvas: Benchmarking web agents in online environments.arXiv preprint arXiv:2406.12373, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Breaking recaptchav2
Andreas Plesner, Tobias V ontobel, and Roger Wattenhofer. Breaking recaptchav2. In2024 IEEE 48th Annual Computers, Software, and Applications Conference (COMPSAC), pages 1047–1056. IEEE, 2024
2024
-
[40]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. Ui-tars: Pioneering automated gui interaction with native agents.arXiv preprint arXiv:2501.12326, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
An empirical study & evaluation of modern {CAPTCHAs}
Andrew Searles, Yoshimichi Nakatsuka, Ercan Ozturk, Andrew Paverd, Gene Tsudik, and Ai Enkoji. An empirical study & evaluation of modern {CAPTCHAs}. In32nd usenix security symposium (usenix security 23), pages 3081–3097, 2023
2023
-
[42]
Adversarial captchas.IEEE transactions on cybernetics, 52(7):6095–6108, 2021
Chenghui Shi, Xiaogang Xu, Shouling Ji, Kai Bu, Jianhai Chen, Raheem Beyah, and Ting Wang. Adversarial captchas.IEEE transactions on cybernetics, 52(7):6095–6108, 2021
2021
-
[43]
I am robot:(deep) learning to break semantic image captchas
Suphannee Sivakorn, Iasonas Polakis, and Angelos D Keromytis. I am robot:(deep) learning to break semantic image captchas. In2016 IEEE European Symposium on Security and Privacy (EuroS&P), pages 388–403. IEEE, 2016
2016
-
[44]
Are {CAPTCHAs} still bot-hard? generalized visual {CAPTCHA} solving with agentic vision language model
Xiwen Teoh, Yun Lin, Siqi Li, Ruofan Liu, Avi Sollomoni, Yaniv Harel, and Jin Song Dong. Are {CAPTCHAs} still bot-hard? generalized visual {CAPTCHA} solving with agentic vision language model. In34th USENIX Security Symposium (USENIX Security 25), pages 3747–3766, 2025
2025
-
[45]
Webgames: Challenging general-purpose web-browsing ai agents.arXiv preprint arXiv:2502.18356, 2025
George Thomas, Alex J Chan, Jikun Kang, Wenqi Wu, Filippos Christianos, Fraser Greenlee, Andy Toulis, and Marvin Purtorab. Webgames: Challenging general-purpose web-browsing ai agents.arXiv preprint arXiv:2502.18356, 2025
-
[46]
Hopper, and John Langford
Luis von Ahn, Manuel Blum, Nicholas J. Hopper, and John Langford. Captcha: Using hard ai problems for security. InAdvances in Cryptology—EUROCRYPT 2003, volume 2656 of Lecture Notes in Computer Science, pages 294–311. Springer, 2003
2003
-
[47]
A captcha design based on visual reasoning
Haipeng Wang, Feng Zheng, Zhuoming Chen, Yi Lu, Jing Gao, and Renjia Wei. A captcha design based on visual reasoning. In2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1967–1971. IEEE, 2018
1967
-
[48]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents.arXiv preprint arXiv:2504.12516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Dissecting adversarial robustness of multimodal lm agents.arXiv preprint arXiv:2406.12814, 2024
Chen Henry Wu, Rishi Shah, Jing Yu Koh, Ruslan Salakhutdinov, Daniel Fried, and Aditi Raghunathan. Dissecting adversarial robustness of multimodal lm agents.arXiv preprint arXiv:2406.12814, 2024
-
[50]
Mca-bench: A multi- modal benchmark for evaluating captcha robustness against vlm-based attacks
Zonglin Wu, Yule Xue, Yaoyao Feng, Xiaolong Wang, and Yiren Song. Mca-bench: A multi- modal benchmark for evaluating captcha robustness against vlm-based attacks. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 38039–38047, 2026. 13
2026
-
[51]
Grok-4 model card
xAI. Grok-4 model card. https://data.x.ai/2025-08-20-grok-4-model-card.pdf , 2025
2025
-
[52]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
2024
-
[53]
Advagent: Controllable blackbox red-teaming on web agents.arXiv preprint arXiv:2410.17401, 2024
Chejian Xu, Mintong Kang, Jiawei Zhang, Zeyi Liao, Lingbo Mo, Mengqi Yuan, Huan Sun, and Bo Li. Advagent: Controllable blackbox red-teaming on web agents.arXiv preprint arXiv:2410.17401, 2024
-
[54]
Tianci Xue, Weijian Qi, Tianneng Shi, Chan Hee Song, Boyu Gou, Dawn Song, Huan Sun, and Yu Su. An illusion of progress? assessing the current state of web agents.arXiv preprint arXiv:2504.01382, 2025
-
[55]
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities. arXiv preprint arXiv:2308.02490, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[56]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9556–9567, 2024
2024
-
[57]
Touch-based continuous mobile device authentication: State-of-the-art, challenges and opportu- nities.Journal of Network and Computer Applications, 191:103162, 2021
Ahmad Zairi Zaidi, Chun Yong Chong, Zhe Jin, Rajendran Parthiban, and Ali Safaa Sadiq. Touch-based continuous mobile device authentication: State-of-the-art, challenges and opportu- nities.Journal of Network and Computer Applications, 191:103162, 2021
2021
-
[58]
Appagent: Multimodal agents as smartphone users
Chi Zhang, Zhao Yang, Jiaxuan Liu, Yanda Li, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Yu. Appagent: Multimodal agents as smartphone users. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1–20, 2025
2025
-
[59]
Attacking vision-language computer agents via pop-ups
Yanzhe Zhang, Tao Yu, and Diyi Yang. Attacking vision-language computer agents via pop-ups. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8387–8401, 2025
2025
-
[60]
Egotextvqa: Towards egocentric scene-text aware video question answering
Sheng Zhou, Junbin Xiao, Qingyun Li, Yicong Li, Xun Yang, Dan Guo, Meng Wang, Tat-Seng Chua, and Angela Yao. Egotextvqa: Towards egocentric scene-text aware video question answering. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 3363–3373, 2025
2025
-
[61]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023. 14 A Detailed Benchmark Specification This appendix provides detailed benchmark information complementary to Secti...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.