Tailoring Teaching to Aptitude: Direction-Adaptive Self-Distillation for LLM Reasoning
Pith reviewed 2026-05-22 08:02 UTC · model grok-4.3
The pith
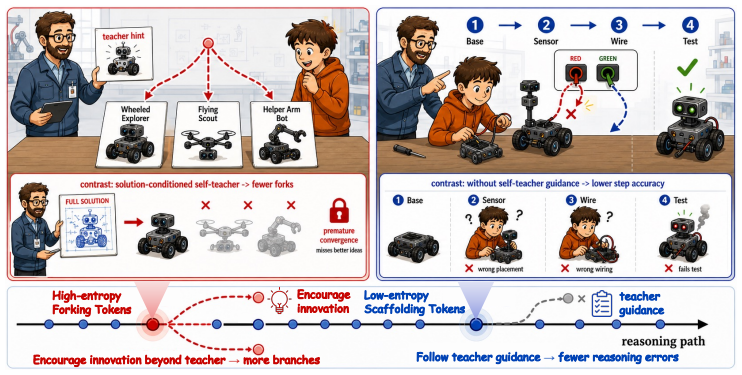
Entropy-routed directional supervision improves LLM math reasoning by pushing models away from the teacher on uncertain tokens and toward it on confident ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On-policy self-distillation degrades reasoning by applying uniform directional supervision that suppresses predictive uncertainty on high-entropy tokens and reduces step accuracy on low-entropy tokens. Direction-Adaptive Self-Distillation reframes privileged self-distillation as entropy-routed directional supervision: high-entropy tokens receive signals that push the policy away from the privileged teacher to preserve exploration, while low-entropy tokens receive signals that pull the policy toward the teacher to stabilize execution.
What carries the argument
Entropy-routed directional supervision that decides whether to imitate or diverge from the self-teacher on each token according to its uncertainty level.
If this is right
- Achieves the highest macro Avg@16 across six mathematical reasoning benchmarks compared with strong RLVR and self-distillation baselines.
- The performance lift comes from higher exploration measured by Pass@k and reasoning-health metrics without loss of step-level execution quality.
- Generalization improves because the method maintains diverse reasoning paths while keeping individual steps reliable.
- The gains are tied directly to adaptive direction rather than uniform imitation of the privileged self-teacher.
Where Pith is reading between the lines
- Similar entropy-based routing might help other self-improvement loops where models need to balance following known paths with trying new ones.
- The technique could extend to code generation or scientific reasoning tasks that also require both accuracy and hypothesis revision.
- Treating tokens differently by model confidence may become a standard principle in post-training methods that avoid external teachers.
- Because the change uses only quantities already computed during rollout, it may add little extra cost while retaining more solution diversity.
Load-bearing premise
Token entropy levels correctly mark where the model needs to explore versus conform, and routing supervision this way during training introduces no new instabilities or undisclosed factors that explain the gains.
What would settle it
If models trained with the method show no rise in Pass@k on difficult problems or lose step accuracy on low-entropy tokens relative to uniform self-distillation baselines, the claimed mechanism would not hold.
Figures









read the original abstract
On-policy self-distillation (OPSD) is an emerging LLM post-training paradigm in which the model serves as its own teacher: conditioned on privileged information such as a reference trace or hint, the same policy provides dense token-level supervision on its own rollouts. However, recent studies show that OPSD degrades complex reasoning by suppressing predictive uncertainty, which supports exploration and hypothesis revision. Our token-level analysis shows that this failure arises from applying a uniform direction of teacher supervision across tokens with different uncertainty levels: conformity to the privileged self-teacher suppresses exploration at high entropy, while deviation from the teacher degrades step accuracy at low entropy. Accordingly, we propose \textbf{Direction-Adaptive Self-Distillation} (\textbf{DASD}), which reframes privileged self-distillation from uniform teacher imitation into entropy-routed directional supervision: high-entropy tokens are pushed away from the privileged teacher to preserve exploration, while low-entropy tokens are pulled toward the teacher to stabilize step-level execution. Across six mathematical reasoning benchmarks, DASD achieves the best macro Avg@16 over strong RLVR and self-distillation baselines. Pass@$k$, reasoning-health, and generalization analyses show that these average gains come from preserving exploration without sacrificing step-level execution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that on-policy self-distillation (OPSD) degrades LLM reasoning by applying uniform directional supervision, which suppresses exploration at high-entropy tokens and harms accuracy at low-entropy ones. It proposes Direction-Adaptive Self-Distillation (DASD) that routes supervision by token entropy—pushing high-entropy tokens away from the privileged teacher to preserve exploration while pulling low-entropy tokens toward it for step stability. Across six mathematical reasoning benchmarks, DASD reports the highest macro Avg@16 versus RLVR and self-distillation baselines, with Pass@k, reasoning-health, and generalization analyses attributing gains to maintained exploration without execution loss.
Significance. If the empirical results and mechanism hold, the work offers a concrete, entropy-based intervention that directly addresses a documented limitation of self-distillation in complex reasoning. The multi-benchmark evaluation together with exploration-focused metrics provides a falsifiable test of the directional-adaptation hypothesis and could inform more robust post-training recipes for LLMs.
major comments (2)
- [§3.2] §3.2 (Entropy-Routed Supervision): The routing rule is presented as 'high-entropy tokens are pushed away... low-entropy tokens are pulled toward,' yet the manuscript does not specify (a) whether entropy is computed from the student policy, teacher logits, or a temperature-scaled distribution, (b) the exact threshold or functional form that decides 'high' versus 'low,' or (c) whether these choices are fixed across benchmarks or tuned per task. Because the central claim is that adaptive direction (rather than any particular hyper-parameter) drives the Avg@16 gains, this omission makes it impossible to verify that the reported advantage is not an artifact of undisclosed routing parameters.
- [§4.3] §4.3 (Ablation and Sensitivity): No ablation table or sensitivity plot varies the entropy threshold, entropy source, or routing temperature while holding other factors fixed. Without such controls, the token-level analysis correctly identifies uniform direction as problematic, but the manuscript cannot yet demonstrate that the entropy-based fix is stable or that performance is insensitive to small changes in the routing implementation—the precise requirement for the causal interpretation offered in the abstract.
minor comments (2)
- [Table 1] Table 1 caption and §4.1: 'macro Avg@16' is used without an explicit definition or reference to how the 16 samples are drawn and aggregated; a one-sentence clarification would aid reproducibility.
- [Figure 3] Figure 3 (reasoning-health curves): The y-axis scale and error-band convention are not stated in the caption, making it difficult to judge whether the separation between DASD and OPSD is statistically reliable.
Simulated Author's Rebuttal
We thank the referee for their constructive review and positive assessment of the significance of our work. We address each major comment below and have revised the manuscript to incorporate the requested clarifications and additional analyses.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Entropy-Routed Supervision): The routing rule is presented as 'high-entropy tokens are pushed away... low-entropy tokens are pulled toward,' yet the manuscript does not specify (a) whether entropy is computed from the student policy, teacher logits, or a temperature-scaled distribution, (b) the exact threshold or functional form that decides 'high' versus 'low,' or (c) whether these choices are fixed across benchmarks or tuned per task. Because the central claim is that adaptive direction (rather than any particular hyper-parameter) drives the Avg@16 gains, this omission makes it impossible to verify that the reported advantage is not an artifact of undisclosed routing parameters.
Authors: We agree that these implementation details require explicit specification for reproducibility and to support the claim that adaptive direction (rather than hyperparameter choice) drives the gains. In the revised manuscript we have expanded §3.2 to state that entropy is computed directly from the student policy's output distribution (logits from the current forward pass, temperature 1.0, no additional scaling). We use a fixed threshold of 1.8 nats, selected on a single held-out validation split and applied uniformly across all six benchmarks without per-task retuning. The revised section also provides the exact loss equations for the push-away and pull-toward terms, allowing readers to confirm that the directional routing itself—not undisclosed parameters—underpins the reported Avg@16 improvements. revision: yes
-
Referee: [§4.3] §4.3 (Ablation and Sensitivity): No ablation table or sensitivity plot varies the entropy threshold, entropy source, or routing temperature while holding other factors fixed. Without such controls, the token-level analysis correctly identifies uniform direction as problematic, but the manuscript cannot yet demonstrate that the entropy-based fix is stable or that performance is insensitive to small changes in the routing implementation—the precise requirement for the causal interpretation offered in the abstract.
Authors: We accept that sensitivity controls are needed to demonstrate stability and support the causal interpretation. The revised §4.3 now includes an ablation table and accompanying sensitivity plots that vary the entropy threshold over the range [1.0, 2.5] nats, compare student-policy entropy against teacher-logit entropy as the routing source, and test routing temperatures of 0.8, 1.0, and 1.2. Results show that DASD retains its advantage over baselines across these settings, with the originally reported configuration near-optimal but not uniquely so. These controls confirm that performance is not brittle to modest changes in the routing implementation and that the directional-adaptation principle accounts for the gains. revision: yes
Circularity Check
No circularity: empirical intervention derived from token analysis
full rationale
The paper's central contribution is an empirical intervention: token-level analysis identifies uniform directional supervision as harmful in OPSD, leading to the proposal of entropy-routed directional supervision in DASD. No equations, derivations, or self-citations are shown that reduce the method or reported gains to fitted parameters or prior results by construction. The performance claims rest on benchmark comparisons and analyses (Pass@k, reasoning-health) that are externally falsifiable, rendering the derivation self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
high-entropy tokens are pushed away from the privileged teacher to preserve exploration, while low-entropy tokens are pulled toward the teacher to stabilize step-level execution
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ω(i)_t = tanh(τ_ρ − H_t / σ̂_H) · σ(|δ̄_t| − 1)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network.NeurIPS Deep Learning Workshop, arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[2]
Yoon Kim and Alexander M. Rush. Sequence-level knowledge distillation. InProceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2016
work page 2016
-
[3]
Lipton, Michael Tschannen, Laurent Itti, and Anima Anandkumar
Tommaso Furlanello, Zachary C. Lipton, Michael Tschannen, Laurent Itti, and Anima Anandkumar. Born-again neural networks. InProceedings of the 35th International Conference on Machine Learning (ICML), 2018
work page 2018
-
[4]
A Survey on Knowledge Distillation of Large Language Models
Xiaohan Xu, Ming Li, Chongyang Tao, Tao Shen, Reynold Cheng, Jinyang Li, Can Xu, Dacheng Tao, and Tianyi Zhou. A survey on knowledge distillation of large language models.arXiv preprint arXiv:2402.13116, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Learning by distilling context.arXiv preprint arXiv:2209.15189, 2022
Charlie Snell, Dan Klein, and Ruiqi Zhong. Learning by distilling context.arXiv preprint arXiv:2209.15189, 2022
-
[6]
A Survey of On-Policy Distillation for Large Language Models
Mingyang Song and Mao Zheng. A survey of on-policy distillation for large language models.arXiv preprint arXiv:2604.00626, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[8]
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. Deep reinforce- ment learning from human preferences. InAdvances in Neural Information Processing Systems (NeurIPS), 2017
work page 2017
-
[9]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedba...
work page 2022
-
[10]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
-
[12]
DAPO: An open-source LLM reinforcement learning system at scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Juncai Liu, LingJun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Ru Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao...
work page 2025
-
[13]
A Survey of Reinforcement Learning for Large Reasoning Models
Kaiyan Zhang, Yuxin Zuo, Bingxiang He, Youbang Sun, Runze Liu, Che Jiang, Yuchen Fan, Kai Tian, Guoli Jia, Pengfei Li, Yu Fu, Xingtai Lv, Yuchen Zhang, Sihang Zeng, Shang Qu, Haozhan Li, Shijie Wang, Yuru Wang, Xinwei Long, Fangfu Liu, Xiang Xu, Jiaze Ma, Xuekai Zhu, Ermo Hua, Yihao Liu, Zonglin Li, Huayu Chen, Xiaoye Qu, Yafu Li, Weize Chen, Zhenzhao Yua...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Keliang Liu, Dingkang Yang, Ziyun Qian, Weijie Yin, Yuchi Wang, Hongsheng Li, Jun Liu, Peng Zhai, Yang Liu, and Lihua Zhang. Reinforcement learning meets large language models: A survey of advancements and applications across the LLM lifecycle.arXiv preprint arXiv:2509.16679, 2025
-
[15]
Towards Reasoning Era: A Survey of Long Chain-of-Thought for Reasoning Large Language Models
Qiguang Chen, Libo Qin, Jinhao Liu, Dengyun Peng, Jiannan Guan, Peng Wang, Mengkang Hu, Yuhang Zhou, Te Gao, and Wanxiang Che. Towards reasoning era: A survey of long chain-of-thought for reasoning large language models.arXiv preprint arXiv:2503.09567, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Gengsheng Li, Tianyu Yang, Junfeng Fang, Mingyang Song, Mao Zheng, Haiyun Guo, Dan Zhang, Jinqiao Wang, and Tat-Seng Chua. Unifying group-relative and self-distillation policy optimization via sample routing. arXiv preprint arXiv:2604.02288, 2026
-
[18]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and Andreas Krause. Reinforcement learning via self-distillation.arXiv preprint arXiv:2601.20802, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan. Self-distilled RLVR.arXiv preprint arXiv:2604.03128, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Self-distillation enables continual learning
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learning. InICLR 2026 Workshop on Lifelong Agents: Learning, Aligning, Evolving, 2026. URL https: //openreview.net/forum?id=HlWA3V6iKF
work page 2026
-
[21]
Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?
Jeonghye Kim, Xufang Luo, Minbeom Kim, Sangmook Lee, Dohyung Kim, Jiwon Jeon, Dongsheng Li, and Yuqing Yang. Why does self-distillation (sometimes) degrade the reasoning capability of LLMs?arXiv preprint arXiv:2603.24472, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[23]
ProcessBench: Identifying process errors in mathematical reasoning
Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. ProcessBench: Identifying process errors in mathematical reasoning. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025
work page 2025
-
[24]
Shenzhi Wang, Le Yu, Chang Gao, Chujie Zheng, Shixuan Liu, Rui Lu, Kai Dang, Xiong-Hui Chen, Jianxin Yang, Zhenru Zhang, Yuqiong Liu, An Yang, Andrew Zhao, Yang Yue, Shiji Song, Bowen Yu, Gao Huang, and Junyang Lin. Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for LLM reasoning. InThe Thirty-ninth Annual Confe...
work page 2026
-
[25]
Entropy-aware on-policy distillation of language models
Woogyeol Jin, Taywon Min, Yongjin Yang, Swanand Ravindra Kadhe, Yi Zhou, Dennis Wei, Nathalie Baracaldo, and Kimin Lee. Entropy-aware on-policy distillation of language models.arXiv preprint arXiv:2603.07079, 2026
-
[26]
An Yang, Baosong Yang, Binyuan Hui, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InAdvances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track, 2021
work page 2021
-
[28]
Solving quantitative reasoning problems with language models
Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving quantitative reasoning problems with language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[29]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, Jie Liu, Lei Qi, Zhiyuan Liu, and Maosong Sun. OlympiadBench: A challenging benchmark for promoting AGI with olympiad-level bilingual multimodal scientific problems. InProceedings of the 62nd Annual Meeting of the Association for Co...
work page 2024
-
[30]
URL http://dx.doi.org/10.1145/3689031
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. InProceedings of the Twentieth European Conference on Computer Systems, EuroSys ’25, page 1279–1297, New York, NY , USA, 2025. Association for Computing Machinery. ISBN 9798400711961. doi: ...
-
[31]
Reasoning with exploration: An entropy perspective
Daixuan Cheng, Shaohan Huang, Xuekai Zhu, Bo Dai, Xin Zhao, Zhenliang Zhang, and Furu Wei. Reasoning with exploration: An entropy perspective. In Sven Koenig, Chad Jenkins, and Matthew E. Taylor, editors, Fortieth AAAI Conference on Artificial Intelligence, Thirty-Eighth Conference on Innovative Applications of Artificial Intelligence, Sixteenth Symposium...
-
[32]
Rethinking Token-Level Credit Assignment in RLVR: A Polarity-Entropy Analysis
Yuhang He, Haodong Wu, Siyi Liu, Hongyu Ge, Hange Zhou, Keyi Wu, Zhuo Zheng, Qihong Lin, Zixin Zhong, and Yongqi Zhang. Rethinking token-level credit assignment in rlvr: A polarity-entropy analysis, 2026. URL https://arxiv.org/abs/2604.11056
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
On the direction of rlvr updates for llm reasoning: Identification and exploitation, 2026
Kexin Huang, Haoming Meng, Junkang Wu, Jinda Lu, Chiyu Ma, Ziqian Chen, Xue Wang, Bolin Ding, Jiancan Wu, Xiang Wang, Xiangnan He, Guoyin Wang, and Jingren Zhou. On the direction of rlvr updates for llm reasoning: Identification and exploitation, 2026. URLhttps://arxiv.org/abs/2603.22117
-
[34]
STAPO: Stabilizing Reinforcement Learning for LLMs by Silencing Rare Spurious Tokens
Shiqi Liu, Zeyu He, Guojian Zhan, Letian Tao, Zhilong Zheng, Jiang Wu, Yinuo Wang, Yang Guan, Kehua Sheng, Bo Zhang, Keqiang Li, Jingliang Duan, and Shengbo Eben Li. Stapo: Stabilizing reinforcement learning for llms by silencing rare spurious tokens, 2026. URLhttps://arxiv.org/abs/2602.15620
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Xinzhu Chen, Xuesheng Li, Zhongxiang Sun, and Weijie Yu. Beyond high-entropy exploration: Correctness- aware low-entropy segment-based advantage shaping for reasoning llms, 2025. URL https://arxiv.org/ abs/2512.00908
-
[36]
Privileged Information Distillation for Language Models
Emiliano Penaloza, Dheeraj Vattikonda, Nicolas Gontier, Alexandre Lacoste, Laurent Charlin, and Massimo Caccia. Privileged information distillation for language models.arXiv preprint arXiv:2602.04942, 2026
work page internal anchor Pith review arXiv 2026
-
[37]
Alex Stein, Furong Huang, and Tom Goldstein. GATES: Self-distillation under privileged context with consensus gating.arXiv preprint arXiv:2602.20574, 2026
-
[38]
$\pi$-Play: Multi-Agent Self-Play via Privileged Self-Distillation without External Data
Yaocheng Zhang, Yuanheng Zhu, Wenyue Chong, Songjun Tu, et al. π-Play: Multi-agent self-play via privileged self-distillation without external data.arXiv preprint arXiv:2604.14054, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
Yuqian Fu, Haohuan Huang, Kaiwen Jiang, Yuanheng Zhu, and Dongbin Zhao. Revisiting on-policy distillation: Empirical failure modes and simple fixes.arXiv preprint arXiv:2603.25562, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by ChatGPT really correct? rigorous evaluation of large language models for code generation. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[41]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google-proof Q&A benchmark. InConference on Language Modeling (COLM), 2024
work page 2024
-
[42]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations (ICLR), 2021
work page 2021
-
[43]
Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. The berkeley function calling leaderboard (BFCL): From tool use to agentic evaluation of large language models. InForty-second International Conference on Machine Learning, 2025. URL https: //openreview.net/forum?id=2GmDdhBdDk
work page 2025
-
[44]
Team Olmo, :, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, Pradeep Dasigi, Robert Berry, Saumya Malik, Saurabh Shah, Scott Geng, S...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
John Schulman, Philipp Moritz, Sergey Levine, Michael I. Jordan, and Pieter Abbeel. High-dimensional contin- uous control using generalized advantage estimation. InInternational Conference on Learning Representations (ICLR), 2016
work page 2016
-
[47]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[48]
Solving math word problems with process- and outcome-based feedback
Jonathan Uesato, Nate Kushman, Ramana Kumar, Francis Song, Noah Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. Solving math word problems with process- and outcome-based feedback. arXiv preprint arXiv:2211.14275, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[49]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[50]
Math-Shepherd: Verify and reinforce LLMs step-by-step without human annotations
Peiyi Wang, Lei Li, Zhihong Shao, Runxin Xu, Damai Dai, Yifei Li, Deli Chen, Yu Wu, and Zhifang Sui. Math-Shepherd: Verify and reinforce LLMs step-by-step without human annotations. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL), 2024
work page 2024
-
[51]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wenkai Yang, Zhiyuan Liu, and Ning Ding. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[52]
On-Policy Context Distillation for Language Models
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models.arXiv preprint arXiv:2602.12275, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[53]
Online experiential learning for language models.arXiv preprint arXiv:2603.16856, 2026
Tianzhu Ye, Li Dong, Qingxiu Dong, Xun Wu, Shaohan Huang, and Furu Wei. Online experiential learning for language models.arXiv preprint arXiv:2603.16856, 2026
-
[54]
Black-box on-policy distillation of large language models.arXiv preprint, arXiv:2511.10643, 2025
Tianzhu Ye, Li Dong, Zewen Chi, Xun Wu, Shaohan Huang, and Furu Wei. Black-box on-policy distillation of large language models.arXiv preprint arXiv:2511.10643, 2025
-
[55]
SODA: Semi On-Policy Black-Box Distillation for Large Language Models
Xiwen Chen, Jingjing Wang, Wenhui Zhu, Peijie Qiu, Xuanzhao Dong, Yueyue Deng, Hejian Sang, Zhipeng Wang, Alborz Geramifard, and Feng Luo. SODA: Semi on-policy black-box distillation for large language models.arXiv preprint arXiv:2604.03873, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[56]
MAD-OPD: Breaking the Ceiling in On-Policy Distillation via Multi-Agent Debate
Jianze Wang, Ying Liu, Jinlong Chen, Xuchun Hu, Qilong Zhang, Yu Cao, Jun Wang, Hua Yang, Yong Xie, and Qianglong Chen. MAD-OPD: Breaking the ceiling in on-policy distillation via multi-agent debate.arXiv preprint arXiv:2605.01347, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[57]
CRISP: Compressed Reasoning via Iterative Self-Policy Distillation
Hejian Sang, Yuanda Xu, Zhengze Zhou, Ran He, Zhipeng Wang, and Jiachen Sun. Crisp: Compressed reasoning via iterative self-policy distillation.arXiv preprint arXiv:2603.05433, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[58]
Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
Yinghui He, Simran Kaur, Adithya Bhaskar, Yongjin Yang, Jiarui Liu, Narutatsu Ri, Liam Fowl, Abhishek Panigrahi, Danqi Chen, and Sanjeev Arora. Self-distillation zero: Self-revision turns binary rewards into dense supervision.arXiv preprint arXiv:2604.12002, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[59]
Opsdl: On-policy self-distillation for long-context language models, 2026
Xinsen Zhang, Zhenkai Ding, Tianjun Pan, Run Yang, Chun Kang, Xue Xiong, and Jingnan Gu. Opsdl: On-policy self-distillation for long-context language models, 2026. URL https://arxiv.org/abs/2604. 17535
work page 2026
-
[60]
Embarrassingly simple self-distillation improves code generation.arXiv:2604.01193, 2026
Ruixiang Zhang, Richard He Bai, Huangjie Zheng, Navdeep Jaitly, Ronan Collobert, and Yizhe Zhang. Embarrassingly simple self-distillation improves code generation.arXiv preprint arXiv:2604.01193, 2026. 14
-
[61]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[62]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[63]
Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. Emergent abilities of large language models.Transactions on Machine Learning Research (TMLR), 2022
work page 2022
- [64]
-
[65]
Griffiths, Yuan Cao, and Karthik Narasimhan
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
work page 2023
-
[66]
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah D. Goodman. STaR: Bootstrapping reasoning with reasoning. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
work page 2022
-
[67]
Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J
Avi Singh, John D. Co-Reyes, Rishabh Agarwal, Ankesh Anand, Piyush Patil, Xavier Garcia, Peter J. Liu, James Harrison, Jaehoon Lee, Kelvin Xu, Aaron Parisi, Abhishek Kumar, Alex Alemi, Alex Rizkowsky, Azade Nova, Ben Adlam, Bernd Bohnet, Gamaleldin Elsayed, Hanie Sedghi, Igor Mordatch, Isabelle Simpson, Izzeddin Gur, Jasper Snoek, Jeffrey Pennington, Jiri...
work page 2024
-
[68]
Self-Refine: Iterative refinement with self-feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Her- mann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-Refine: Iterative refinement with self-feedback. InAdvances in Neural Information Processing S...
work page 2023
-
[69]
Large language models cannot self-correct reasoning yet
Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[70]
Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu
Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T. Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. MetaMath: Bootstrap your own mathematical questions for large language models. InInternational Conference on Learning Representations (ICLR), 2024
work page 2024
-
[71]
WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct
Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Jianguang Lou, Chongyang Tao, Xiubo Geng, Qingwei Lin, Shifeng Chen, Yansong Tang, and Dongmei Zhang. WizardMath: Empowering mathematical reasoning for large language models via reinforced evol-instruct.arXiv preprint arXiv:2308.09583, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[72]
ToRA: A tool-integrated reasoning agent for mathematical problem solving
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Minlie Huang, Nan Duan, and Weizhu Chen. ToRA: A tool-integrated reasoning agent for mathematical problem solving. InInternational Conference on Learning Representations (ICLR), 2024. 15 Appendix Overview and Roadmap The appendix is organized in the same order in which the main text first call...
work page 2024
-
[73]
Appendix A expands the three diagnostic probes that motivate entropy-conditioned teacher direction
-
[74]
Appendix B proves Proposition 1 and records the approximation used by the sampled token estimator
-
[75]
Appendix C gives the full DASD pseudocode aligned with Section 4
-
[76]
Appendix D reports extended Avg@16 benchmark and Pass@16 values
-
[77]
Appendix E separates the Qwen3-only cross-domain check from the math-only cross-family check across Qwen3, Olmo, and Llama
-
[78]
Appendix F details datasets, baselines, metrics, sampling, and implementation settings
-
[79]
Appendix G expands the design-space ablation; its first subsection, Appendix G.1, analyzes entropy-quantile sensitivity. It also includes appendix-only figures, including a model-scale analysis showing that the DASD−GRPO gap widens with Qwen3 scale (Figure 8)
-
[80]
Appendix H gives the longer positioning against RLVR, OPD, OPSD, RLSD, SDPO, SRPO, and entropy- aware credit methods
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.