Procedural Memory Distillation: Online Reflection for Self-Improving Language Models
Pith reviewed 2026-07-03 20:10 UTC · model grok-4.3
The pith
Language models improve by turning cross-episode rollout patterns into reusable memory that supervises and updates the policy itself.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Procedural Memory Distillation converts cross-episode signals from model rollouts into reusable procedural memory organized at three levels of abstraction—raw trajectories, self-reflected strategies and lessons, and higher-level behavioral patterns—and distills this memory into the policy via a memory-conditioned self-teacher that supervises the student on its own rollouts, enabling the policy to progressively internalize the procedural knowledge and producing a memory-free model at inference.
What carries the argument
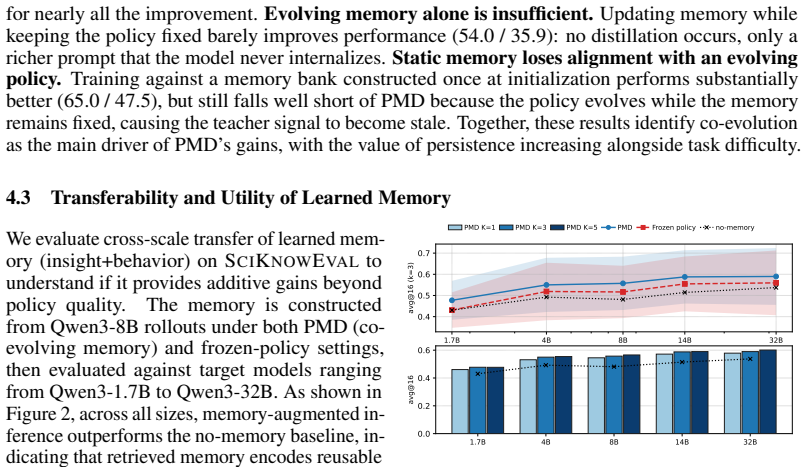
The co-evolution loop in which the policy generates rollouts that update the procedural memory and the memory then supplies supervision that updates the policy.
If this is right
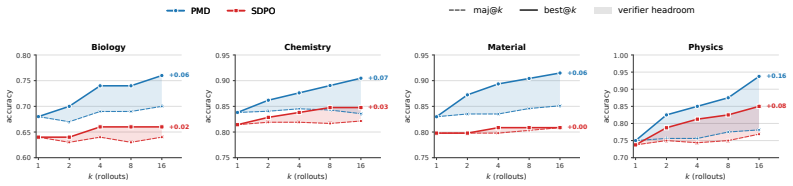
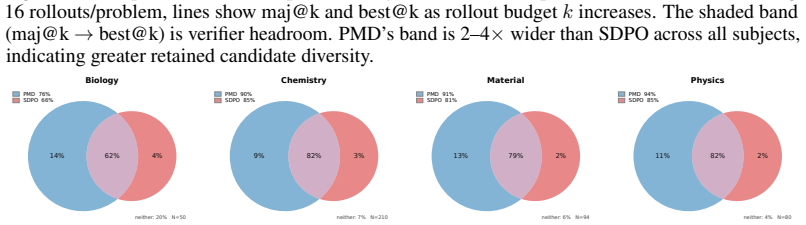
- Across Qwen3-8B and OLMo3-Instruct-7B, the method improves over SDPO by 3.8-5.5 percent on SCIKNOWEVAL and 7.9-13.6 percent on LIVECODEBENCH.
- Freezing either the memory or the policy during training reduces gains by more than 10 percent across SCIKNOWEVAL domains.
- The final trained policy operates without external memory at inference time.
- Co-evolution between policy and memory is required for the observed improvements rather than either component alone.
Where Pith is reading between the lines
- The three-level memory structure might allow selective transfer of only the higher-level patterns to smaller models without retraining the full memory.
- The online extraction process could be applied to other verifiable-reward settings such as theorem proving or tool-use sequences where recurring failure modes appear across episodes.
- If the self-teacher supervision proves robust, it may reduce reliance on curated offline datasets for continued self-improvement after initial training.
Load-bearing premise
The self-reflected strategies, lessons, and patterns extracted online from the model's trajectories are accurate and non-noisy enough to serve as effective supervision signals.
What would settle it
An ablation that replaces the extracted memory contents with random or inverted reflections and measures whether performance on SCIKNOWEVAL and LIVECODEBENCH still exceeds the SDPO baseline by the reported margins.
Figures

read the original abstract
Reinforcement learning with verifiable rewards (RLVR), along with recent selfdistillation variants such as SDPO, evaluates each rollout against a verifier and updates the policy from that episode-level signal. However, the richer procedural information in the rollout is rarely retained or reused. Across episodes and epochs, the model repeatedly encounters related problems under a changing policy, producing cross-episode signals that episode-local updates cannot capture: which strategies consistently pass verification, which failure modes persist, which patterns recur. We propose Procedural Memory Distillation (PMD), which converts these crossepisode signals into reusable procedural memory and distills it into the policy's weights during training. This memory functions as a training scaffold, absorbed into the policy itself, yielding a memory-free model at inference. PMD organizes the memory at three levels of abstraction: raw trajectories, self-reflected strategies and lessons, and higher-level behavioral patterns that recur across problems, all extracted online from the model's own trajectories. A memory-conditioned self-teacher draws on the accumulated experience to supervise the student on its own rollouts, enabling student to progressively internalize procedural knowledge within its parameters. The central design principle is co-evolution: the policy generates rollouts that update the memory, and memory shapes the supervision that updates the policy. Empirically, across Qwen3-8B and OLMo3-Instruct-7B, PMD improves over SDPO by 3.8-5.5% on SCIKNOWEVAL and 7.9-13.6% on LIVECODEBENCH. Co-evolution powers these gains: freezing either the memory or the policy trails PMD by more than 10% across SCIKNOWEVAL domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Procedural Memory Distillation (PMD) to address the limitation of episode-local updates in RLVR and SDPO by extracting cross-episode procedural memory at three levels (raw trajectories, self-reflected strategies/lessons, higher-level behavioral patterns) from the model's own rollouts. A memory-conditioned self-teacher then supervises the student policy in a co-evolution loop where the policy updates the memory and the memory shapes policy updates, with the goal of internalizing the knowledge into model weights for a memory-free inference model. Empirically, PMD outperforms SDPO by 3.8-5.5% on SCIKNOWEVAL and 7.9-13.6% on LIVECODEBENCH across Qwen3-8B and OLMo3-Instruct-7B, with ablations showing >10% drops when freezing either memory or policy.
Significance. If the results and the accuracy of the self-reflections hold, the work could meaningfully advance online self-improvement methods for LLMs by converting transient rollout signals into reusable, internalized procedural knowledge. The explicit co-evolution principle and multi-level memory organization provide a concrete design pattern that, if validated with full implementation details, would be a useful contribution to the self-distillation literature.
major comments (3)
- [Abstract] Abstract and methods description: no mechanism is described for verifying the accuracy of self-reflected strategies/lessons or filtering noise from model-generated reflections before they are used as supervision signals. This is load-bearing for the central claim, as inaccurate reflections would be distilled and amplified through the co-evolution loop, directly undermining the reported gains over SDPO.
- [Empirical results] Empirical results: the manuscript supplies no statistical tests, run-to-run variance, or detailed ablation breakdowns (beyond the high-level freezing experiment) to support the 3.8-5.5% and 7.9-13.6% improvements or to isolate the contribution of the three-level memory organization.
- [Abstract] Abstract: the co-evolution loop is described only at a high level with no equations, update rules, or pseudocode for memory extraction, memory-conditioned supervision, or the interaction between policy and memory. This prevents assessment of whether performance gains are independent of the extraction process or partly circular.
minor comments (2)
- [Abstract] Abstract contains several missing hyphens in compound terms ("selfdistillation", "crossepisode", "self-teacher").
- The paper would benefit from a diagram illustrating the three memory levels and the co-evolution flow between policy and memory.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The three major comments identify important gaps in methodological detail, empirical rigor, and clarity of the co-evolution process. We address each point below and will revise the manuscript to incorporate the requested clarifications and additions.
read point-by-point responses
-
Referee: [Abstract] Abstract and methods description: no mechanism is described for verifying the accuracy of self-reflected strategies/lessons or filtering noise from model-generated reflections before they are used as supervision signals. This is load-bearing for the central claim, as inaccurate reflections would be distilled and amplified through the co-evolution loop, directly undermining the reported gains over SDPO.
Authors: We agree that the absence of an explicit verification or filtering mechanism for self-reflections is a substantive omission. The current manuscript relies on the fact that only trajectories passing the external verifier are used to seed reflections, but does not describe additional consistency or cross-episode validation steps. In the revision we will add a new subsection (Methods 3.3) that specifies (1) outcome-based filtering that retains only reflections associated with verified successes and (2) a lightweight consistency check that discards reflections whose implied strategy contradicts the verifier outcome on the same trajectory. These additions will be accompanied by an ablation measuring the effect of the filter. revision: yes
-
Referee: [Empirical results] Empirical results: the manuscript supplies no statistical tests, run-to-run variance, or detailed ablation breakdowns (beyond the high-level freezing experiment) to support the 3.8-5.5% and 7.9-13.6% improvements or to isolate the contribution of the three-level memory organization.
Authors: The referee is correct that the reported improvements lack statistical support and fine-grained ablations. We will revise the Experiments section to include: (a) results from five independent random seeds with mean and standard deviation, (b) paired t-tests or Wilcoxon tests with p-values for all headline comparisons against SDPO, and (c) an expanded ablation table that isolates the incremental contribution of each memory level (raw trajectories, self-reflected strategies, behavioral patterns) as well as the interaction between levels. These changes will be added before resubmission. revision: yes
-
Referee: [Abstract] Abstract: the co-evolution loop is described only at a high level with no equations, update rules, or pseudocode for memory extraction, memory-conditioned supervision, or the interaction between policy and memory. This prevents assessment of whether performance gains are independent of the extraction process or partly circular.
Authors: The full manuscript already contains pseudocode (Algorithm 1) and the memory-conditioned loss (Equation 4) in Section 3, but the abstract and high-level overview remain purely descriptive. We will revise the abstract to include a concise statement of the alternating update rule and will move the existing pseudocode and equations into a more prominent position in the main text with an explicit non-circularity argument: memory is updated only from verified rollouts, while the policy is trained on a mixture of memory-conditioned and standard RLVR objectives. This should make the independence of the two processes clearer. revision: partial
Circularity Check
No significant circularity; empirical claims rest on external benchmarks and ablations
full rationale
The paper proposes an empirical training procedure (PMD) that extracts procedural memory from model trajectories and uses a memory-conditioned self-teacher for supervision, with co-evolution as the design principle. Claims of improvement (3.8-5.5% on SCIKNOWEVAL, 7.9-13.6% on LIVECODEBENCH over SDPO) are supported by direct comparisons to baselines and ablations (freezing memory or policy drops performance >10%). No equations, parameter fits, or derivations are described that reduce the reported gains to the method inputs by construction. The evaluation uses held-out benchmarks and external verifiers, rendering results falsifiable outside the training loop itself. No self-citations, uniqueness theorems, or ansatzes are invoked in the provided text to justify core choices.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The richer procedural information in the rollout is rarely retained or reused across episodes and epochs in RLVR and SDPO.
- ad hoc to paper Self-reflected strategies and lessons extracted from the model's trajectories can be reliably used to supervise the student.
invented entities (1)
-
Procedural memory organized at three levels of abstraction (raw trajectories, self-reflected strategies/lessons, higher-level behavioral patterns)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sergio Ramos Garea, Matthieu Geist, and Olivier Bachem. “On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes”. In:International Conference on Learning Representations. 2024
2024
-
[2]
X-KD: General Experiential Knowledge Distillation for Large Language Models
Yuang Cai and Yuyu Yuan. “X-KD: General Experiential Knowledge Distillation for Large Language Models”. In:arXiv preprint arXiv:2602.12674(2026)
-
[3]
Zihao Cheng, Zeming Liu, Yingyu Shan, Xinyi Wang, Xiangrong Zhu, Yunpu Ma, Hongru Wang, Yuhang Guo, Wei Lin, and Yunhong Wang. “Mem2Evolve: Towards Self-Evolving Agents via Co-Evolutionary Capability Expansion and Experience Distillation”. In:arXiv preprint arXiv:2604.10923(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
SciKnowEval: Evaluating Multi-level Scientific Knowledge of Large Language Models
Kehua Feng, Keyan Ding, Weijie Wang, Xiang Zhuang, Zeyuan Wang, Ming Qin, Yu Zhao, Jianhua Yao, Qiang Zhang, and Huajun Chen. “SciKnowEval: Evaluating Multi-level Scientific Knowledge of Large Language Models”. In:arXiv preprint arXiv:2406.09098(2024)
-
[5]
MiniLLM: Knowledge Distillation of Large Language Models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. “MiniLLM: Knowledge Distillation of Large Language Models”. In:International Conference on Learning Representations. 2024
2024
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, and Xiao Bi. “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning”. In:arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Self-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
Yinghui He, Simran Kaur, Adithya Bhaskar, Yongjin Yang, Jiarui Liu, Narutatsu Ri, Liam Fowl, Abhishek Panigrahi, Danqi Chen, and Sanjeev Arora. “Self-Distillation Zero: Self- Revision Turns Binary Rewards into Dense Supervision”. In:arXiv preprint arXiv:2604.12002 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. “Distilling the Knowledge in a Neural Network”. In:NeurIPS Deep Learning and Representation Learning Workshop. 2015
2015
-
[9]
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu. “R-Zero: Self-Evolving Reasoning LLM from Zero Data”. In:arXiv preprint arXiv:2508.05004(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Reinforcement Learning via Self-Distillation
Jonas Hübotter, Frederike Lübeck, Lejs Behric, Anton Baumann, Marco Bagatella, Daniel Marta, Ido Hakimi, Idan Shenfeld, Thomas Kleine Buening, Carlos Guestrin, and Andreas Krause. “Reinforcement learning via self-distillation”. In:arXiv preprint arXiv:2601.20802 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. “LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code”. In:arXiv preprint arXiv:2403.07974(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?
Jeonghye Kim, Xufang Luo, Minbeom Kim, Sangmook Lee, Dohyung Kim, Jiwon Jeon, Dongsheng Li, and Yuqing Yang. “Why Does Self-Distillation (Sometimes) Degrade the Reasoning Capability of LLMs?” In:arXiv preprint arXiv:2603.24472(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
uttler, Mike Lewis, Wen-tau Yih, Tim Rockt
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K"uttler, Mike Lewis, Wen-tau Yih, Tim Rockt"aschel, Sebastian Riedel, and Douwe Kiela. “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”. In: Advances in Neural Information Processing Systems. 2020
2020
-
[14]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan-ang Gao, Wenkai Yang, Zhiyuan Liu, and Ning Ding. “Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe”. In:arXiv preprint arXiv:2604.13016(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Thinking Machines Lab: Con- nectionism
Kevin Lu and Thinking Machines Lab.On-Policy Distillation. Thinking Machines Lab: Con- nectionism. 2025.URL: https://thinkingmachines.ai/blog/on-policy- distillation/
2025
-
[16]
SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization
Zhengxi Lu, Zhiyuan Yao, Jinyang Wu, Chengcheng Han, Qi Gu, Xunliang Cai, Weiming Lu, Jun Xiao, Yueting Zhuang, and Yongliang Shen. “SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization”. In:arXiv preprint arXiv:2604.02268(2026). 10
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Self-Refine: Iterative Refinement with Self-Feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Sean Welleck, Bodhisattwa Prasad Majumder, Shashank Gupta, Amir Yazdanbakhsh, and Peter Clark. “Self-Refine: Iterative Refinement with Self-Feedback”. In:Advances in Neural Information Processing Systems. 2023
2023
-
[18]
Team Olmo, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heine- man, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, and Hamish Ivison. “Olmo 3”. In: arXiv preprint arXiv:2512.13961(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
Siru Ouyang, Jun Yan, I Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long T Le, Samira Daruki, and Xiangru Tang. “Reasoningbank: Scaling agent self-evolving with reasoning memory”. In:arXiv preprint arXiv:2509.25140(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Vivian Fang, Shishir G. Patil, Kevin Lin, Sarah Wooders, and Joseph E. Gonza- lez. “MemGPT: Towards LLMs as Operating Systems”. In:arXiv preprint arXiv:2310.08560 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Generative Agents: Interactive Simulacra of Human Behavior
Joon Sung Park, Joseph C. O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. “Generative Agents: Interactive Simulacra of Human Behavior”. In: ACM Symposium on User Interface Software and Technology. 2023
2023
-
[22]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. “Direct Preference Optimization: Your Language Model is Secretly a Reward Model”. In:Advances in Neural Information Processing Systems. 2023
2023
-
[23]
A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning
Stephane Ross, Geoffrey Gordon, and Drew Bagnell. “A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning”. In:International Conference on Artificial Intelligence and Statistics. 2011
2011
-
[24]
CRISP: Compressed Reasoning via Iterative Self-Policy Distillation
Hejian Sang, Yuanda Xu, Zhengze Zhou, Ran He, Zhipeng Wang, and Jiachen Sun. “On-policy self-distillation for reasoning compression”. In:arXiv preprint arXiv:2603.05433(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. “Proximal Policy Optimization Algorithms”. In:arXiv preprint arXiv:1707.06347(2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[26]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. “DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models”. In:arXiv preprint arXiv:2402.03300 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Self-Distillation Enables Continual Learning
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. “Self-distillation enables continual learning”. In:arXiv preprint arXiv:2601.19897(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[28]
Experiential reinforcement learning
Taiwei Shi, Sihao Chen, Bowen Jiang, Linxin Song, Longqi Yang, and Jieyu Zhao. “Experien- tial reinforcement learning”. In:arXiv preprint arXiv:2602.13949(2026)
-
[29]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. “Reflexion: Language Agents with Verbal Reinforcement Learning”. In:Advances in Neural Information Processing Systems. 2023
2023
-
[30]
A Survey of On-Policy Distillation for Large Language Models
Mingyang Song and Mao Zheng. “A Survey of On-Policy Distillation for Large Language Models”. In:arXiv preprint arXiv:2604.00626(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
MemoryGraft: Persistent Compromise of LLM Agents via Poisoned Experience Retrieval
Saksham Sahai Srivastava and Haoyu He. “MemoryGraft: Persistent Compromise of LLM Agents via Poisoned Experience Retrieval”. In:arXiv preprint arXiv:2512.16962(2025)
-
[32]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. “V oyager: An Open-Ended Embodied Agent with Large Language Models”. In:arXiv preprint arXiv:2305.16291(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Skill-SD: Skill-Conditioned Self-Distillation for Multi-turn LLM Agents
Hao Wang, Guozhi Wang, Han Xiao, Yufeng Zhou, Yue Pan, Jichao Wang, Ke Xu, Yafei Wen, Xiaohu Ruan, Xiaoxin Chen, and Honggang Qi. “Skill-SD: Skill-Conditioned Self-Distillation for Multi-turn LLM Agents”. In:arXiv preprint arXiv:2604.10674(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
Skil- lOrchestra: Learning to route agents via skill transfer
Jiayu Wang, Yifei Ming, Zixuan Ke, Shafiq Joty, Aws Albarghouthi, and Frederic Sala. “Skil- lOrchestra: Learning to route agents via skill transfer”. In:arXiv preprint arXiv:2602.19672 (2026)
-
[35]
Mem-{\alpha}: Learning Memory Construction via Reinforcement Learning
Yu Wang, Ryuichi Takanobu, Zhiqi Liang, Yuzhen Mao, Yuanzhe Hu, Julian McAuley, and Xiaojian Wu. “Mem-α: Learning memory construction via reinforcement learning”. In:arXiv preprint arXiv:2509.25911(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Q-learning
Christopher JCH Watkins and Peter Dayan. “Q-learning”. In:Machine learning8.3 (1992), pp. 279–292. 11
1992
-
[37]
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle
Rui Wu, Yifei Li, Yuchen Zhang, Yiming Wang, Xiaodong Li, Lichang Chen, Jinyang Chen, Lei Li, and Xipeng Qiu. “Self-Evolving LLM Agents through an Experience-Driven Lifecycle”. In:arXiv preprint arXiv:2510.16079(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
TokMem: One-token procedural memory for large language models
Zijun Wu, Yongchang Hao, and Lili Mou. “TokMem: One-token procedural memory for large language models”. In:arXiv preprint arXiv:2510.00444(2025)
-
[39]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, Zeyu Zheng, Cihang Xie, and Huaxiu Yao. “SkillRL: Evolving agents via recursive skill-augmented reinforcement learning”. In:arXiv preprint arXiv:2602.08234(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[40]
Meta-Reinforcement Learning with Self-Reflection for Agentic Search
Teng Xiao, Yige Yuan, Hamish Ivison, Huaisheng Zhu, Faeze Brahman, Nathan Lambert, Pradeep Dasigi, Noah A. Smith, and Hannaneh Hajishirzi. “Meta-Reinforcement Learning with Self-Reflection for Agentic Search”. In:arXiv preprint arXiv:2603.11327(2026)
-
[41]
A-mem: Agentic memory for llm agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. “A-mem: Agentic memory for llm agents”. In:Advances in Neural Information Processing Systems38 (2026), pp. 17577–17604
2026
-
[42]
Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Jinhe Bi, Kristian Kersting, Jeff Z. Pan, Hinrich Schütze, V olker Tresp, and Yunpu Ma. “Memory-R1: Enhancing large language model agents to manage and utilize memories via reinforcement learning”. In:arXiv preprint arXiv:2508.19828(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, and Chenxu Lv. “Qwen3 technical report”. In:arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Chenxu Yang, Chuanyu Qin, Qingyi Si, Minghui Chen, Naibin Gu, Dingyu Yao, Zheng Lin, Weiping Wang, Jiaqi Wang, and Nan Duan. “Self-Distilled RLVR”. In:arXiv preprint arXiv:2604.03128(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[45]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. “ReAct: Synergizing Reasoning and Acting in Language Models”. In:International Conference on Learning Representations. 2023
2023
-
[46]
Online Experiential Learning for Language Models
Tianzhu Ye, Li Dong, Qingxiu Dong, Xun Wu, Shaohan Huang, and Furu Wei. “Online experiential learning for language models”. In:arXiv preprint arXiv:2603.16856(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[47]
On-Policy Context Distillation for Language Models
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. “On-policy context distillation for language models”. In:arXiv preprint arXiv:2602.12275(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
Yi Yu, Liuyi Yao, Yuexiang Xie, Qingquan Tan, Jiaqi Feng, Yaliang Li, and Libing Wu. “Agentic memory: Learning unified long-term and short-term memory management for large language model agents”. In:arXiv preprint arXiv:2601.01885(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
arXiv preprint arXiv:2509.24704 , year=
Guibin Zhang, Muxin Fu, and Shuicheng Yan. “MemGen: Weaving generative latent memory for self-evolving agents”. In:arXiv preprint arXiv:2509.24704(2025)
-
[50]
Embarrassingly Simple Self-Distillation Improves Code Generation
Ruixiang Zhang, Richard He Bai, Huangjie Zheng, Navdeep Jaitly, Ronan Collobert, and Yizhe Zhang. “Embarrassingly Simple Self-Distillation Improves Code Generation”. In:arXiv preprint arXiv:2604.01193(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, and Junyang Lin. “Qwen3 embedding: Advancing text embedding and reranking through foundation models”. In:arXiv preprint arXiv:2506.05176(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
MemFly: On-the-Fly Memory Optimization via Information Bottleneck
Zhenyuan Zhang, Xianzhang Jia, Zhiqin Yang, Zhenbo Song, Wei Xue, Sirui Han, and Yike Guo. “MemFly: On-the-Fly Memory Optimization via Information Bottleneck”. In:arXiv preprint arXiv:2602.07885(2026)
-
[53]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. “Self-distilled reasoner: On-policy self-distillation for large language models”. In: arXiv preprint arXiv:2601.18734(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
Memorybank: Enhancing large language models with long-term memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. “Memorybank: Enhancing large language models with long-term memory”. In:Proceedings of the AAAI conference on artificial intelligence. V ol. 38. 17. 2024, pp. 19724–19731
2024
-
[55]
Memento: Fine-tuning llm agents without fine-tuning llms.arXiv preprint arXiv:2508.16153, 2025
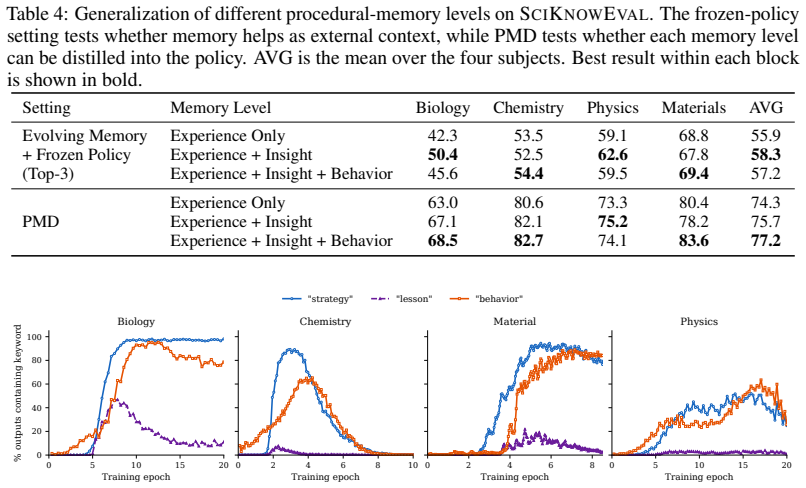
Huichi Zhou, Yihang Chen, Siyuan Guo, Xue Yan, Kin Hei Lee, Zihan Wang, Ka Yiu Lee, Guchun Zhang, Kun Shao, Linyi Yang, and Jun Wang. “Memento: Fine-tuning LLM agents without fine-tuning LLMs”. In:arXiv preprint arXiv:2508.16153(2025). 12 Table 4: Generalization of different procedural-memory levels on SCIKNOWEVAL. The frozen-policy setting tests whether ...
-
[56]
{behavior_1_name}: {behavior_1_instruction}
-
[57]
strategies
{behavior_2_name}: {behavior_2_instruction} ... K. {behavior_K_name}: {behavior_K_instruction} Correct solution: {successful_previous_attempt} The following is feedback from your unsuccessful earlier attempt: {feedback_raw} Correctly solve the original question. Here, {problem_text} is the original question. The fields {strategies} and {lessons} are probl...
-
[58]
Identify recurring patterns across these related problems
-
[59]
Extract 3--8 reusable behaviors, each with a name and instruction
-
[60]
Focus on high-level, transferable guidance
-
[61]
Include both positive behaviors and mistakes to avoid
-
[62]
behaviors
Avoid problem-specific wording, option-letter shortcuts, and references to individual attempts. Respond ONLY with valid JSON: {"behaviors": [{"name": "behavior_...", "instruction": "..."}, ...]} Evolution prompt.Once the bank contains existing behaviors, the extractor switches to an evolution prompt. It is shown the current semantic-cluster summaries and ...
-
[63]
Review existing behaviors against the new cluster evidence
-
[64]
Identify gaps not covered by existing behaviors
-
[65]
Decide on actions: new, update, or remove
-
[66]
actions": [ {
Keep behaviors reusable, concise, and independent of any single problem. Respond ONLY with valid JSON: {"actions": [ {"action": "new", "name": "behavior_...", "instruction": "..."}, {"action": "update", "name": "behavior_existing_name", "instruction": "..."}, {"action": "remove", "name": "behavior_bad_one"}]} This retrieve-then-decide pattern prevents the...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.