World-Ego Modeling for Long-Horizon Evolution in Hybrid Embodied Tasks
Pith reviewed 2026-05-20 06:32 UTC · model grok-4.3
The pith
Decomposing future embodied predictions into separate world and ego streams improves long-horizon hybrid task performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
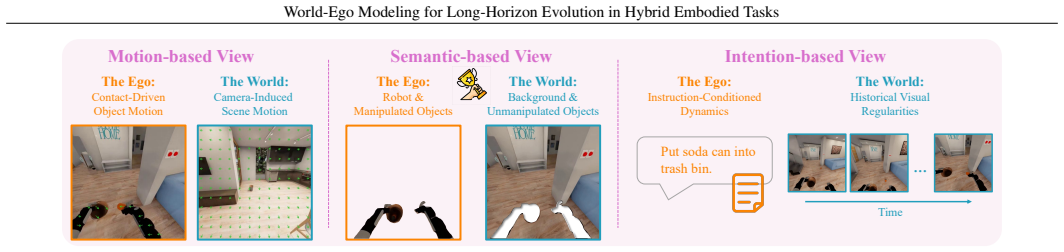
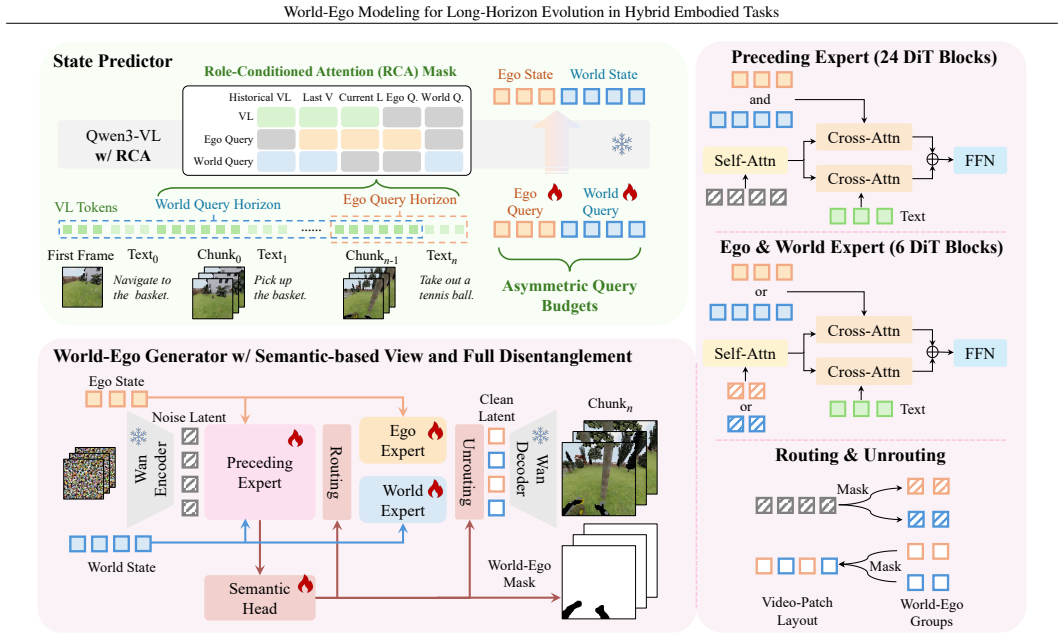
World-Ego Modeling decomposes future evolution into distinct world and ego components by defining their boundary from motion-, semantic-, and intention-based views and by analyzing post-, pre-, and full disentanglement. The paradigm is realized as the World-Ego Model, which couples an implicit separate world-ego planner with a cascade-parallel mixture-of-experts diffusion generator. On the introduced HTEWorld benchmark of long-horizon hybrid navigation-manipulation tasks the resulting model outperforms prior world models while remaining competitive on manipulation-only benchmarks.
What carries the argument
The world-ego boundary, defined from motion-, semantic-, and intention-based views, which enables post-, pre-, and full disentanglement of future evolutions inside the World-Ego Model architecture.
If this is right
- WEM reaches state-of-the-art results on the HTEWorld benchmark of 300 multi-turn hybrid trajectories.
- The same model remains competitive with prior methods on existing manipulation-only benchmarks.
- Explicit separation of persistent scene regularities from instruction-conditioned robot dynamics reduces performance degradation over long interleaved navigation-manipulation sequences.
- The three disentanglement strategies (post, pre, full) provide measurable trade-offs for modeling hybrid task evolution.
Where Pith is reading between the lines
- The same boundary definitions could be tested on purely navigation or purely manipulation datasets to check whether hybrid-task gains generalize.
- Isolating world from ego dynamics may reduce error accumulation in downstream planners that rely on multi-step rollouts.
- Real-robot experiments with sensor noise and physical dynamics would reveal whether the video-clip improvements transfer outside simulation.
Load-bearing premise
The world-ego boundary defined from motion-, semantic-, and intention-based views permits effective post-, pre-, and full disentanglement that improves long-horizon hybrid task modeling.
What would settle it
A controlled ablation on HTEWorld in which removing the motion-semantic-intention boundary definitions and the associated disentanglement strategies produces equal or higher performance on long-horizon hybrid trajectories would falsify the central claim.
Figures





read the original abstract
World models are widely explored in embodied intelligence, yet they typically predict distinct evolutions of the world and the ego within a single stream, where the world captures persistent instruction-agnostic scene regularities and the ego captures robot-centric instruction-conditioned dynamics. This world-ego entanglement leads to a degradation in long-horizon embodied scenarios, particularly in hybrid tasks with interleaved navigation and manipulation behaviors. In this paper, we introduce \emph{World-Ego Modeling}, a new conceptual paradigm that decomposes future evolution into world and ego components. We define the world-ego boundary from three perspectives, i.e., motion-, semantic-, and intention-based views, and analyze three disentanglement strategies with post-, pre-, and full disentanglement. Further, we instantiate this paradigm as the World-Ego Model (WEM), a unified embodied world model that couples an implicit separate world-ego planner with a cascade-parallel mixture-of-experts (CP-MoE) diffusion generator. To enable rigorous evaluation, we further construct HTEWorld, the first benchmark for long-horizon world modeling with hybrid navigation-manipulation tasks, providing 125K video clips (over 4.5M frames) with fine-grained action annotations and 300 multi-turn evaluation trajectories (over 2K instructions). Extensive experiments show that WEM achieves state-of-the-art performance on HTEWorld while remaining competitive on existing manipulation-only benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes World-Ego Modeling (WEM), a new paradigm that decomposes future evolution in embodied tasks into separate world (persistent, instruction-agnostic scene regularities) and ego (robot-centric, instruction-conditioned dynamics) components to mitigate entanglement in long-horizon hybrid navigation-manipulation scenarios. It defines the world-ego boundary from motion-, semantic-, and intention-based views and analyzes post-, pre-, and full disentanglement strategies. The paradigm is instantiated as the World-Ego Model coupling an implicit planner with a cascade-parallel mixture-of-experts (CP-MoE) diffusion generator. The authors also introduce the HTEWorld benchmark with 125K video clips (4.5M frames) and 300 multi-turn trajectories for rigorous evaluation. Experiments claim SOTA performance on HTEWorld and competitive results on existing manipulation-only benchmarks.
Significance. If the reported gains are causally attributable to the world-ego boundary definitions and disentanglement strategies rather than the CP-MoE generator capacity alone, the work would provide a meaningful conceptual and technical advance for long-horizon embodied world modeling in hybrid tasks. The HTEWorld benchmark addresses a clear gap in evaluating interleaved navigation-manipulation behaviors and could serve as a community resource. The three-view boundary analysis offers a structured way to separate persistent vs. dynamic elements that may generalize beyond the specific instantiation.
major comments (2)
- [Experiments] Experiments section: No ablations are described that hold the CP-MoE diffusion generator and planner architecture fixed while toggling only the disentanglement strategies (post-/pre-/full) or the boundary definitions (motion-/semantic-/intention-based). This is load-bearing for the central claim, as the abstract and paradigm definition locate the long-horizon improvements in the world-ego separation, yet the new generator's training dynamics and capacity could independently explain SOTA on the author-constructed HTEWorld benchmark.
- [Method / Benchmark] §3 (Method) and HTEWorld construction: The paper does not report controls or statistics showing that the 300 multi-turn evaluation trajectories were selected independently of the proposed WEM (e.g., via held-out human demonstrations or cross-validation against baseline generators). Without this, it remains possible that benchmark construction interacts with the model design, weakening the claim that WEM's disentanglement drives the hybrid-task gains.
minor comments (2)
- [Abstract] Abstract: The phrase 'fine-grained action annotations' is used without specifying the action vocabulary size, annotation protocol, or inter-annotator agreement for the 125K clips; adding one sentence would improve reproducibility.
- [Method] Notation: The three boundary views and the mapping from disentanglement strategy to the implicit planner outputs are introduced conceptually but lack a compact equation or diagram reference early in the method; a small table summarizing the three strategies would aid clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for acknowledging the potential value of the world-ego paradigm and HTEWorld benchmark. We address each major comment below.
read point-by-point responses
-
Referee: [Experiments] Experiments section: No ablations are described that hold the CP-MoE diffusion generator and planner architecture fixed while toggling only the disentanglement strategies (post-/pre-/full) or the boundary definitions (motion-/semantic-/intention-based). This is load-bearing for the central claim, as the abstract and paradigm definition locate the long-horizon improvements in the world-ego separation, yet the new generator's training dynamics and capacity could independently explain SOTA on the author-constructed HTEWorld benchmark.
Authors: We agree that stronger isolation of the disentanglement strategies is needed to support the central claim. The current manuscript reports performance across post-, pre-, and full disentanglement as well as the three boundary definitions, but these comparisons do not hold the CP-MoE generator and planner completely fixed across all variants. We will add dedicated ablation experiments in the revision that fix the generator architecture and planner while varying only the disentanglement strategies and boundary views. This will more directly attribute gains to the world-ego separation. revision: yes
-
Referee: [Method / Benchmark] §3 (Method) and HTEWorld construction: The paper does not report controls or statistics showing that the 300 multi-turn evaluation trajectories were selected independently of the proposed WEM (e.g., via held-out human demonstrations or cross-validation against baseline generators). Without this, it remains possible that benchmark construction interacts with the model design, weakening the claim that WEM's disentanglement drives the hybrid-task gains.
Authors: The 300 multi-turn trajectories were drawn from a held-out portion of the HTEWorld data that was not used to train WEM or any baseline models. However, the original manuscript does not include explicit statistics, cross-validation details, or controls demonstrating independence from the WEM design. We will revise the benchmark construction section to add these details, including data splits and selection criteria. revision: yes
Circularity Check
No circularity: paradigm, disentanglement strategies, and HTEWorld benchmark introduced as independent contributions with external evaluation.
full rationale
The paper defines a new World-Ego Modeling paradigm by decomposing future evolution into world and ego components using motion-, semantic-, and intention-based boundary views, then analyzes post-/pre-/full disentanglement strategies before instantiating WEM as an implicit planner coupled to a CP-MoE diffusion generator. It further constructs the HTEWorld benchmark with 125K clips and 300 trajectories for evaluation. No step reduces a claimed prediction or first-principles result to its own inputs by construction; the performance claims rest on empirical results on the new benchmark and existing manipulation suites rather than self-referential fitting or self-citation chains. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Future evolution in embodied tasks can be usefully decomposed into instruction-agnostic world regularities and instruction-conditioned ego dynamics.
invented entities (1)
-
World-Ego Model (WEM) with CP-MoE diffusion generator
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We define the world-ego boundary from three perspectives, i.e., motion-, semantic-, and intention-based views, and analyze three disentanglement strategies with post-, pre-, and full disentanglement.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
WEM ... couples an implicit separate world-ego planner with a cascade-parallel mixture-of-experts (CP-MoE) diffusion generator
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Recurrent world models facilitate policy evolution
David Ha and J ¨urgen Schmidhuber. Recurrent world models facilitate policy evolution. InNeurIPS, 2018
work page 2018
-
[2]
Mastering diverse control tasks through world models.Nature, 2025
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse control tasks through world models.Nature, 2025
work page 2025
-
[3]
Causal World Modeling for Robot Control
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, Yujun Shen, and Yinghao Xu. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[4]
Dreamgen: Unlocking generalization in robot learning through video world models
Joel Jang, Seonghyeon Ye, Zongyu Lin, Jiannan Xiang, Johan Bjorck, Yu Fang, Fengyuan Hu, Spencer Huang, Kaushil Kundalia, Yen-Chen Lin, et al. Dreamgen: Unlocking generalization in robot learning through video world models. In CoRL, 2025
work page 2025
-
[5]
Learning interactive real-world simulators
Mengjiao Yang, Yilun Du, Seyed Kamyar Seyed Ghasemipour, Jonathan Tompson, Leslie Pack Kaelbling, Dale Schuurmans, and Pieter Abbeel. Learning interactive real-world simulators. InICLR, 2024
work page 2024
-
[6]
Daydreamer: World models for physical robot learning
Philipp Wu, Alejandro Escontrela, Danijar Hafner, Pieter Abbeel, and Ken Goldberg. Daydreamer: World models for physical robot learning. InCoRL, 2023
work page 2023
-
[7]
FLARE: Robot learning with implicit world modeling
Ruijie Zheng, Jing Wang, Scott Reed, Johan Bjorck, Yu Fang, Fengyuan Hu, Joel Jang, Kaushil Kundalia, Zongyu Lin, Lo¨ıc Magne, Avnish Narayan, You Liang Tan, Guanzhi Wang, Qi Wang, Jiannan Xiang, Yinzhen Xu, Seonghyeon Ye, Jan Kautz, Furong Huang, Yuke Zhu, and Linxi Fan. FLARE: Robot learning with implicit world modeling. InCoRL, 2025
work page 2025
-
[8]
Cosmos policy: Fine-tuning video models for visuomotor control and planning
Moo Jin Kim, Yihuai Gao, Tsung-Yi Lin, Yen-Chen Lin, Yunhao Ge, Grace Lam, Percy Liang, Shuran Song, Ming-Yu Liu, Chelsea Finn, and Jinwei Gu. Cosmos policy: Fine-tuning video models for visuomotor control and planning. In ICLR, 2026
work page 2026
-
[9]
World Action Models are Zero-shot Policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, Ayaan Malik, Kyungmin Lee, William Liang, Nadun Ranawaka, Jiasheng Gu, Yinzhen Xu, Guanzhi Wang, Fengyuan Hu, Avnish Narayan, Johan Bjorck, et al. World action models are zero-shot policies. arXiv preprint arXiv:2602...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
Any-point trajectory modeling for policy learning
Chuan Wen, Xingyu Lin, John So, Kai Chen, Qi Dou, Yang Gao, and Pieter Abbeel. Any-point trajectory modeling for policy learning. InRSS, 2024. 11 World-Ego Modeling for Long-Horizon Evolution in Hybrid Embodied Tasks
work page 2024
-
[11]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
World Simulation with Video Foundation Models for Physical AI
Arslan Ali, Junjie Bai, Maciej Bala, Yogesh Balaji, Aaron Blakeman, Tiffany Cai, Jiaxin Cao, Tianshi Cao, Elizabeth Cha, Yu-Wei Chao, et al. World simulation with video foundation models for physical AI.arXiv preprint arXiv:2511.00062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Owl-1: Omni world model for consistent long video generation.arXiv preprint arXiv:2412.09600, 2024
Yuanhui Huang, Wenzhao Zheng, Yuan Gao, Xin Tao, Pengfei Wan, Di Zhang, Jie Zhou, and Jiwen Lu. Owl-1: Omni world model for consistent long video generation.arXiv preprint arXiv:2412.09600, 2024
-
[14]
WORLDMEM: Long-term consistent world simulation with memory
Zeqi Xiao, Yushi Lan, Yifan Zhou, Wenqi Ouyang, Shuai Yang, Yanhong Zeng, and Xingang Pan. WORLDMEM: Long-term consistent world simulation with memory. InNeurIPS, 2025
work page 2025
-
[15]
Ying Yang, Zhengyao Lv, Tianlin Pan, Haofan Wang, Binxin Yang, Hubery Yin, Chen Li, Ziwei Liu, and Chenyang Si. StableWorld: Towards stable and consistent long interactive video generation.arXiv preprint arXiv:2601.15281, 2026
-
[16]
Matrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory
Zile Wang, Zexiang Liu, Jaixing Li, Kaichen Huang, Baixin Xu, Fei Kang, Mengyin An, Peiyu Wang, Biao Jiang, Yichen Wei, et al. Matrix-game 3.0: Real-time and streaming interactive world model with long-horizon memory.arXiv preprint arXiv:2604.08995, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InICML, 2024
work page 2024
-
[18]
Robodreamer: Learning composi- tional world models for robot imagination
Siyuan Zhou, Yilun Du, Jiaben Chen, Yandong Li, Dit-Yan Yeung, and Chuang Gan. Robodreamer: Learning composi- tional world models for robot imagination. InICML, 2024
work page 2024
-
[19]
Jiannan Xiang, Yi Gu, Zihan Liu, Zeyu Feng, Qiyue Gao, Yiyan Hu, Benhao Huang, Guangyi Liu, Yichi Yang, Kun Zhou, et al. PAN: A world model for general, interactable, and long-horizon world simulation.arXiv preprint arXiv:2511.09057, 2025
-
[20]
Tesseract: Learning 4d embodied world models
Haoyu Zhen, Qiao Sun, Hongxin Zhang, Junyan Li, Siyuan Zhou, Yilun Du, and Chuang Gan. Tesseract: Learning 4d embodied world models. InICCV, 2025
work page 2025
-
[21]
Learning world models for interactive video generation
Taiye Chen, Xun Hu, Zihan Ding, and Chi Jin. Learning world models for interactive video generation. InNeurIPS, 2025
work page 2025
-
[22]
VideoREPA: Learning physics for video generation through relational alignment with foundation models
Xiangdong Zhang, Jiaqi Liao, Shaofeng Zhang, Fanqing Meng, Xiangpeng Wan, Junchi Yan, and Yu Cheng. VideoREPA: Learning physics for video generation through relational alignment with foundation models. InNeurIPS, 2025
work page 2025
-
[23]
A path towards autonomous machine intelligence, 2022
Yann LeCun. A path towards autonomous machine intelligence, 2022. URL https://openreview.net/forum? id=BZ5a1r-kVsf. OpenReview position paper, version 0.9.2
work page 2022
-
[24]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-JEPA 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Mariam Hassan, Sebastian Stapf, Ahmad Rahimi, Pedro Rezende, Yasaman Haghighi, David Br ¨uggemann, Isinsu Katircioglu, Lin Zhang, Xiaoran Chen, Suman Saha, et al. Gem: A generalizable ego-vision multimodal world model for fine-grained ego-motion, object dynamics, and scene composition control. InCVPR, 2025
work page 2025
-
[26]
Yu Shang, Lei Jin, Yiding Ma, Xin Zhang, Chen Gao, Wei Wu, and Yong Li. Longscape: Advancing long-horizon embodied world models with context-aware moe.arXiv preprint arXiv:2509.21790, 2025
-
[27]
Byungjun Kim, Taeksoo Kim, Junyoung Lee, and Hanbyul Joo. Dexterous world models. InCVPR, 2026. 12 World-Ego Modeling for Long-Horizon Evolution in Hybrid Embodied Tasks
work page 2026
-
[28]
Towards long-horizon vision- language navigation: Platform, benchmark and method
Xinshuai Song, Weixing Chen, Yang Liu, Vincent Chan, Guanbin Li, and Liang Lin. Towards long-horizon vision- language navigation: Platform, benchmark and method. InCVPR, 2025
work page 2025
-
[29]
Mobility VLA: Multimodal instruction navigation with long-context VLMs and topological graphs
Zhuo Xu, Hao-Tien Lewis Chiang, Zipeng Fu, Mithun George Jacob, Tingnan Zhang, Tsang-Wei Edward Lee, Wenhao Yu, Connor Schenck, David Rendleman, Dhruv Shah, Fei Xia, Jasmine Hsu, Jonathan Hoech, Pete Florence, Sean Kirmani, Sumeet Singh, Vikas Sindhwani, Carolina Parada, Chelsea Finn, Peng Xu, Sergey Levine, and Jie Tan. Mobility VLA: Multimodal instructi...
work page 2025
-
[30]
MoManipVLA: Transferring vision-language- action models for general mobile manipulation
Zhenyu Wu, Yuheng Zhou, Xiuwei Xu, Ziwei Wang, and Haibin Yan. MoManipVLA: Transferring vision-language- action models for general mobile manipulation. InCVPR, 2025
work page 2025
-
[31]
MAGI-1: Autoregressive Video Generation at Scale
Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, WQ Zhang, Weifeng Luo, et al. Magi-1: Autoregressive video generation at scale.arXiv preprint arXiv:2505.13211, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Diffusion forcing: Next-token prediction meets full-sequence diffusion
Boyuan Chen, Diego Mart´ı Mons´o, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion. InNeurIPS, 2024
work page 2024
-
[33]
Rolling forcing: Autoregressive long video diffusion in real time
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. Rolling forcing: Autoregressive long video diffusion in real time. InICLR, 2026
work page 2026
-
[34]
Haodong Li, Shaoteng Liu, Zhe Lin, and Manmohan Chandraker. Rolling sink: Bridging limited-horizon training and open-ended testing in autoregressive video diffusion.arXiv preprint arXiv:2602.07775, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Hidir Yesiltepe, Tuna Han Salih Meral, Adil Kaan Akan, Kaan Oktay, and Pinar Yanardag. Infinity-RoPE: Action- controllable infinite video generation emerges from autoregressive self-rollout.arXiv preprint arXiv:2511.20649, 2025
-
[36]
VBench++: Comprehensive and versatile benchmark suite for video generative models.IEEE TPAMI, 2025
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, et al. VBench++: Comprehensive and versatile benchmark suite for video generative models.IEEE TPAMI, 2025
work page 2025
-
[37]
Worldmodelbench: Judging video generation models as world models
Dacheng Li, Yunhao Fang, Yukang Chen, Shuo Yang, Shiyi Cao, Justin Wong, Michael Luo, Xiaolong Wang, Hongxu Yin, Joseph E Gonzalez, et al. Worldmodelbench: Judging video generation models as world models. InNeurIPS, 2025
work page 2025
-
[38]
Rethinking video generation model for the embodied world
Yufan Deng, Zilin Pan, Hongyu Zhang, Xiaojie Li, Ruoqing Hu, Yufei Ding, Yiming Zou, Yan Zeng, and Daquan Zhou. Rethinking video generation model for the embodied world. InICML, 2026
work page 2026
-
[39]
Yu Shang, Zhuohang Li, Yiding Ma, Weikang Su, Xin Jin, Ziyou Wang, Lei Jin, Xin Zhang, Yinzhou Tang, Haisheng Su, et al. Worldarena: A unified benchmark for evaluating perception and functional utility of embodied world models. arXiv preprint arXiv:2602.08971, 2026
-
[40]
BEHA VIOR-1K: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation
Chengshu Li, Ruohan Zhang, Josiah Wong, Cem Gokmen, Sanjana Srivastava, Roberto Mart´ın-Mart´ın, Chen Wang, Gabrael Levine, Michael Lingelbach, Jiankai Sun, et al. BEHA VIOR-1K: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation. InCoRL, 2023
work page 2023
-
[41]
Dream to control: Learning behaviors by latent imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination. InICLR, 2020
work page 2020
-
[42]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InNeurIPS, 2020
work page 2020
-
[43]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, 2022
work page 2022
-
[44]
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jianfeng Gao, Lifang He, and Lichao Sun. Sora: A review on background, technology, limitations, and opportunities of large vision models.arXiv preprint arXiv:2402.17177, 2024. 13 World-Ego Modeling for Long-Horizon Evolution in Hybrid Embodied Tasks
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
CogVideoX: Text-to-video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. CogVideoX: Text-to-video diffusion models with an expert transformer. InICLR, 2025
work page 2025
-
[47]
Genie 2: A large-scale foundation world model, 2024
Jack Parker-Holder, Philip Ball, Jake Bruce, Vibhavari Dasagi, Kristian Holsheimer, Christos Kaplanis, Alexandre Mou- farek, Guy Scully, Jeremy Shar, Jimmy Shi, et al. Genie 2: A large-scale foundation world model, 2024. URL https: //deepmind.google/blog/genie-2-a-large-scale-foundation-world-model/ . Google Deep- Mind blog
work page 2024
-
[48]
Open-Sora: Democratizing Efficient Video Production for All
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-Sora: Democratizing efficient video production for all.arXiv preprint arXiv:2412.20404, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Vid2World: Crafting video diffusion models to interactive world models
Siqiao Huang, Jialong Wu, Qixing Zhou, Shangchen Miao, and Mingsheng Long. Vid2World: Crafting video diffusion models to interactive world models. InICLR, 2026
work page 2026
-
[50]
Matrix-game 2.0: An open-source real-time and streaming interactive world model
Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, Qi Cui, Fei Kang, Biao Jiang, Mengyin An, Yangyang Ren, et al. Matrix-game 2.0: An open-source, real-time, and streaming interactive world model.arXiv preprint arXiv:2508.13009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. HunyuanVideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[52]
MotionCtrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. MotionCtrl: A unified and flexible motion controller for video generation. InSIGGRAPH, 2024
work page 2024
-
[53]
FloVD: Optical flow meets video diffusion model for enhanced camera-controlled video synthesis
Wonjoon Jin, Qi Dai, Chong Luo, Seung-Hwan Baek, and Sunghyun Cho. FloVD: Optical flow meets video diffusion model for enhanced camera-controlled video synthesis. InCVPR, 2025
work page 2025
-
[54]
Rays as Pixels: Learning A Joint Distribution of Videos and Camera Trajectories
Wonbong Jang, Shikun Liu, Soubhik Sanyal, Juan Camilo Perez, Kam Woh Ng, Sanskar Agrawal, Juan-Manuel Perez- Rua, Yiannis Douratsos, and Tao Xiang. Rays as pixels: Learning a joint distribution of videos and camera trajectories. arXiv preprint arXiv:2604.09429, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[55]
Motion attribution for video generation
Xindi Wu, Despoina Paschalidou, Jun Gao, Antonio Torralba, Laura Leal-Taix´e, Olga Russakovsky, Sanja Fidler, and Jonathan Lorraine. Motion attribution for video generation. InICML, 2026
work page 2026
-
[56]
Ruili Feng, Han Zhang, Zhantao Yang, Jie Xiao, Zhilei Shu, Zhiheng Liu, Andy Zheng, Yukun Huang, Yu Liu, and Hongyang Zhang. The matrix: Infinite-horizon world generation with real-time moving control.arXiv preprint arXiv:2412.03568, 2024
-
[57]
Yume: An interactive world generation model.arXiv preprint arXiv:2507.17744, 2025
Xiaofeng Mao, Shaoheng Lin, Zhen Li, Chuanhao Li, Wenshuo Peng, Tong He, Jiangmiao Pang, Mingmin Chi, Yu Qiao, and Kaipeng Zhang. Yume: An interactive world generation model.arXiv preprint arXiv:2507.17744, 2025
-
[58]
LIVE: Long-horizon interactive video world modeling.arXiv preprint arXiv:2602.03747, 2026
Junchao Huang, Ziyang Ye, Xinting Hu, Tianyu He, Guiyu Zhang, Shaoshuai Shi, Jiang Bian, and Li Jiang. LIVE: Long-horizon interactive video world modeling.arXiv preprint arXiv:2602.03747, 2026
-
[59]
Roboscape: Physics-informed embodied world model
Yu Shang, Xin Zhang, Yinzhou Tang, Lei Jin, Chen Gao, Wei Wu, and Yong Li. Roboscape: Physics-informed embodied world model. InNeurIPS, 2025
work page 2025
-
[60]
BridgeData V2: A dataset for robot learning at scale
Homer Walke, Kevin Black, Abraham Lee, Moo Jin Kim, Max Du, Chongyi Zheng, Tony Zhao, Philippe Hansen-Estruch, Quan Vuong, Andre He, Vivek Myers, Kuan Fang, Chelsea Finn, and Sergey Levine. BridgeData V2: A dataset for robot learning at scale. InCoRL, 2023. 14 World-Ego Modeling for Long-Horizon Evolution in Hybrid Embodied Tasks
work page 2023
-
[61]
Sheng Chen, Peiyu He, Jiaxin Hu, Ziyang Liu, Yansheng Wang, Tao Xu, Chi Zhang, et al. Astra: Toward general-purpose mobile robots via hierarchical multimodal learning.arXiv preprint arXiv:2506.06205, 2025
-
[62]
Motus: A Unified Latent Action World Model
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, Hongyan Zhao, Hanyu Liu, Zhizhong Su, Lei Ma, Hang Su, and Jun Zhu. Motus: A unified latent action world model.arXiv preprint arXiv:2512.13030, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Large Video Planner Enables Generalizable Robot Control
Boyuan Chen, Tianyuan Zhang, Haoran Geng, Kiwhan Song, Caiyi Zhang, Peihao Li, William T. Freeman, Jitendra Malik, Pieter Abbeel, Russ Tedrake, Vincent Sitzmann, and Yilun Du. Large video planner enables generalizable robot control.arXiv preprint arXiv:2512.15840, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Xiaowei Chi, Peidong Jia, Chun-Kai Fan, Xiaozhu Ju, Weishi Mi, Kevin Zhang, Zhiyuan Qin, Wanxin Tian, Kuangzhi Ge, Hao Li, Zezhong Qian, Anthony Chen, Qiang Zhou, Yueru Jia, Jiaming Liu, Yong Dai, Qingpo Wuwu, Chengyu Bai, Yu-Kai Wang, Ying Li, Lizhang Chen, Yong Bao, Zhiyuan Jiang, Jiacheng Zhu, Kai Tang, Ruichuan An, Yulin Luo, Qiuxuan Feng, Siyuan Zhou...
-
[65]
Ctrl-world: A controllable generative world model for robot manipulation
Yanjiang Guo, Lucy Xiaoyang Shi, Jianyu Chen, and Chelsea Finn. Ctrl-world: A controllable generative world model for robot manipulation. InICLR, 2026
work page 2026
-
[66]
Vla-jepa: Enhancing vision- language-action model with latent world model,
Jingwen Sun, Wenyao Zhang, Zekun Qi, Shaojie Ren, Zezhi Liu, Hanxin Zhu, Guangzhong Sun, Xin Jin, and Zhibo Chen. VLA-JEPA: Enhancing vision-language-action model with latent world model.arXiv preprint arXiv:2602.10098, 2026
-
[67]
Shuang Zeng, Dekang Qi, Xinyuan Chang, Feng Xiong, Shichao Xie, Xiaolong Wu, Shiyi Liang, Mu Xu, and Xing Wei. JanusVLN: Decoupling semantics and spatiality with dual implicit memory for vision-language navigation. InICLR, 2026
work page 2026
-
[68]
4D-VLA: Spatiotemporal vision-language-action pretraining with cross-scene calibration
Jiahui Zhang, Yurui Chen, Yueming Xu, Ze Huang, Yanpeng Zhou, Yu-Jie Yuan, Xinyue Cai, Guowei Huang, Xingyue Quan, Hang Xu, and Li Zhang. 4D-VLA: Spatiotemporal vision-language-action pretraining with cross-scene calibration. InNeurIPS, 2025
work page 2025
-
[69]
Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets
Chuning Zhu, Raymond Yu, Siyuan Feng, Benjamin Burchfiel, Paarth Shah, and Abhishek Gupta. Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets. InRSS, 2025
work page 2025
-
[70]
Iso-Dream: Isolating and leveraging noncontrollable visual dynamics in world models
Minting Pan, Xiangming Zhu, Yunbo Wang, and Xiaokang Yang. Iso-Dream: Isolating and leveraging noncontrollable visual dynamics in world models. InNeurIPS, 2022
work page 2022
-
[71]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.JMLR, 2022
work page 2022
-
[73]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Deven- dra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[74]
Vision transformers for dense prediction
Ren ´e Ranftl, Alexey Bochkovskiy, and Vladlen Koltun. Vision transformers for dense prediction. InICCV, 2021
work page 2021
-
[75]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. InICLR, 2023. 15 World-Ego Modeling for Long-Horizon Evolution in Hybrid Embodied Tasks
work page 2023
-
[76]
Dice loss for data-imbalanced NLP tasks
Xiaoya Li, Xiaofei Sun, Yuxian Meng, Junjun Liang, Fei Wu, and Jiwei Li. Dice loss for data-imbalanced NLP tasks. In ACL, 2020
work page 2020
-
[77]
VBench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. VBench: Comprehensive benchmark suite for video generative models. InCVPR, 2024
work page 2024
-
[78]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Lulu Gu, Yuanhan Zhang, Jingwen He, Wei-Shi Zheng, et al. VBench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[79]
IRASim: A fine-grained world model for robot manipulation
Fangqi Zhu, Hongtao Wu, Song Guo, Yuxiao Liu, Chilam Cheang, and Tao Kong. IRASim: A fine-grained world model for robot manipulation. InICCV, 2025
work page 2025
-
[80]
Raft: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. InECCV, 2020
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.