UCOB: Learning to Utilize and Evolve Agentic Skills via Credit-Aware On-Policy Bidirectional Self-Distillation
Pith reviewed 2026-06-30 07:12 UTC · model grok-4.3
The pith
UCOB treats skill and no-skill prompts as paired on-policy views and lets the higher-return view teach the other within the same task and state.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UCOB replaces the privileged-teacher assumption with credit-aware on-policy bidirectional self-distillation: skill-conditioned and no-skill prompts are treated as two context views of the same policy; their return-to-go values are compared inside the identical task and anchor state; the higher-return view supplies the distillation target; and the credit difference simultaneously updates the policy, evolves the skill memory, and guides utility-aware retrieval and reflection.
What carries the argument
Credit-aware on-policy bidirectional self-distillation that selects the local teacher by direct return-to-go comparison between paired skill and no-skill rollouts from the same state.
If this is right
- Skill memory evolves to store only locally useful entries rather than globally high-reward ones.
- Retrieval becomes conditioned on predicted credit rather than surface similarity alone.
- Reflection self-training receives a grounded target derived from the same credit comparison.
- Performance scales with model size while retaining the same credit mechanism.
- The method yields measured gains on ALFWorld and WebShop that exceed prior skill-memory and self-distillation baselines.
Where Pith is reading between the lines
- The same paired-view comparison could be applied to any retrieval-augmented generation setting where retrieved context sometimes harms performance.
- On-policy credit signals may reduce the sample complexity of distillation in other partially observable RL domains.
- Skill libraries could be pruned aggressively once credit-aware updates are in place, lowering memory and retrieval cost.
- The approach suggests testing whether explicit credit comparison stabilizes other bidirectional distillation schemes that currently rely on privileged teachers.
Load-bearing premise
That the higher return-to-go view observed in the same task and anchor state supplies an unbiased teacher signal that can safely drive both policy updates and skill-memory changes without selection bias or instability.
What would settle it
A controlled run in which the skill with higher immediate return-to-go is shown to produce lower final task success rates than a fixed or random skill policy when the same credit signal is used for distillation and memory updates.
Figures

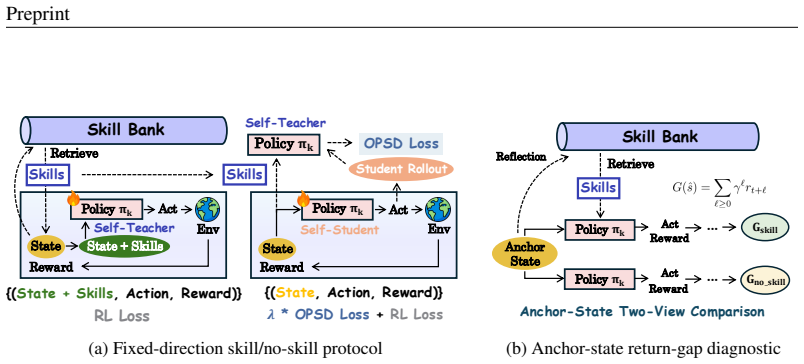
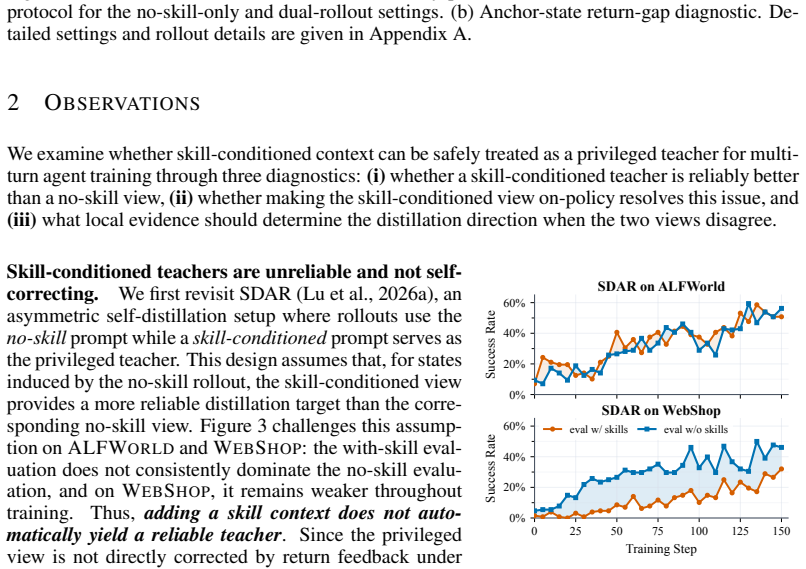








read the original abstract
Skill memories can improve agentic reinforcement learning by reusing past experience as textual guidance, but retrieved skills are not oracular: they may help in one state while misleading the same policy in another. This makes the common privileged-teacher assumption fragile, namely that a skill-conditioned prompt can be treated as a fixed teacher for the no-skill prompt. We introduce UCOB, a framework for learning to utilize and evolve agentic skills via credit-aware on-policy bidirectional self-distillation. UCOB treats skill-conditioned and no-skill prompts as two on-policy context views of the same model, compares their return-to-go within the same task and anchor state, and uses the higher-return view as the local teacher. This local credit signal internalizes useful skill-conditioned behavior, corrects misleading skill usage, and guides task/state skill memory updates, utility-aware retrieval, and reflection self-training. Experiments on agentic tasks, including ALFWorld, WebShop, and Search-QA, show that UCOB outperforms skill-free RL, skill-memory baselines, and self-distillation methods across model scales, with up to 23.5 and 18.0 point gains over SOTA baselines on ALFWorld and WebShop. Ablations and analyses further validate its core mechanisms and efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UCOB, a framework for learning to utilize and evolve agentic skills via credit-aware on-policy bidirectional self-distillation. It treats skill-conditioned and no-skill prompts as two on-policy context views of the same model, compares their return-to-go within the same task and anchor state, and uses the higher-return view as the local teacher. This local credit signal is used to internalize useful skill-conditioned behavior, correct misleading skill usage, and guide task/state skill memory updates, utility-aware retrieval, and reflection self-training. Experiments on agentic tasks including ALFWorld, WebShop, and Search-QA show that UCOB outperforms skill-free RL, skill-memory baselines, and self-distillation methods across model scales, with up to 23.5 and 18.0 point gains over SOTA baselines on ALFWorld and WebShop.
Significance. If the local credit signal is unbiased, the approach could advance agentic RL by providing a mechanism to handle imperfect retrieved skills without a privileged-teacher assumption, enabling better utilization and evolution of skill memories. The reported performance gains are large and consistent across tasks and scales; if reproducible with the claimed ablations, this would represent a meaningful empirical contribution to self-distilling agent policies.
major comments (1)
- [Abstract (mechanism description)] The core mechanism (abstract) treats the higher return-to-go view as an unbiased local teacher for on-policy updates and skill-memory evolution. However, the skill prompt alters the policy from the anchor state onward, so the two views induce different trajectory distributions; returns therefore conflate skill utility with differential exploration. No derivation is given showing the comparison remains an unbiased estimator of the value of skill usage conditional on the anchor, nor any analysis of resulting effects on policy-gradient variance or convergence. This assumption is load-bearing for all claimed gains and skill-evolution claims.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the load-bearing assumption in the core mechanism. We address the concern point-by-point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract (mechanism description)] The core mechanism (abstract) treats the higher return-to-go view as an unbiased local teacher for on-policy updates and skill-memory evolution. However, the skill prompt alters the policy from the anchor state onward, so the two views induce different trajectory distributions; returns therefore conflate skill utility with differential exploration. No derivation is given showing the comparison remains an unbiased estimator of the value of skill usage conditional on the anchor, nor any analysis of resulting effects on policy-gradient variance or convergence. This assumption is load-bearing for all claimed gains and skill-evolution claims.
Authors: We agree that the manuscript provides no formal derivation establishing that the return-to-go comparison is an unbiased estimator of skill utility conditional on the anchor state. Because the skill prompt changes the policy distribution from the anchor onward, the two views generate different trajectory distributions, and the return comparison necessarily mixes skill utility with differences in exploration. The current text relies on the empirical utility of the resulting local credit signal for bidirectional self-distillation and memory updates, supported by the reported ablations and gains, but does not analyze bias, policy-gradient variance, or convergence properties. In the revision we will (1) explicitly acknowledge this limitation in the mechanism description, (2) add a discussion section examining the implications for bias and variance under the on-policy bidirectional setup, and (3) include additional analysis or controlled experiments that quantify the practical impact of differential exploration on the credit signal. These changes will make the justification for the approach more transparent while preserving the empirical contributions. revision: yes
Circularity Check
No significant circularity; on-policy self-distillation is standard RL structure, not a definitional reduction.
full rationale
The paper defines UCOB as comparing return-to-go between two on-policy context views (skill-conditioned vs. no-skill) of the same model from a shared anchor state, then using the higher-return view as local teacher for updates and skill-memory evolution. This is an explicit design choice for bidirectional self-distillation in agentic RL; the resulting credit signal and policy updates are not shown to equal the input data or a fitted parameter by construction. No equations, self-citations, or uniqueness theorems are invoked in the abstract or description that would make the claimed gains tautological. Experiments on ALFWorld, WebShop, and Search-QA serve as external benchmarks. The derivation chain remains self-contained as an algorithmic proposal rather than a closed logical loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Higher return-to-go view between two prompts is a reliable local teacher
Reference graph
Works this paper leans on
-
[2]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Alfworld: Aligning text and embodied environments for interactive learning , author=. arXiv preprint arXiv:2010.03768 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[3]
Reflexion: Language Agents with Verbal Reinforcement Learning
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. arXiv preprint arXiv:2303.11366 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
ReAct: Synergizing Reasoning and Acting in Language Models
ReAct: Synergizing Reasoning and Acting in Language Models , author=. arXiv preprint arXiv:2210.03629 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Policy Distillation , author=. arXiv preprint arXiv:1511.06295 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Proximal Policy Optimization Algorithms
Proximal Policy Optimization Algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author=. arXiv preprint arXiv:2005.11401 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[8]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. arXiv preprint arXiv:2305.16291 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
arXiv preprint arXiv:2308.10144 , year=
ExpeL: LLM Agents Are Experiential Learners , author=. arXiv preprint arXiv:2308.10144 , year=
-
[10]
A Survey on the Memory Mechanism of Large Language Model based Agents
A Survey on the Memory Mechanism of Large Language Model based Agents , author=. arXiv preprint arXiv:2404.13501 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Group-in-Group Policy Optimization for LLM Agent Training
Group-in-Group Policy Optimization for LLM Agent Training , author=. arXiv preprint arXiv:2505.10978 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning , author=. arXiv preprint arXiv:2504.20073 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
arXiv preprint arXiv:2505.11821 , year=
Reinforcing Multi-Turn Reasoning in LLM Agents via Turn-Level Reward Design , author=. arXiv preprint arXiv:2505.11821 , year=
-
[14]
GAGPO: Generalized Advantage Grouped Policy Optimization
GAGPO: Generalized Advantage Grouped Policy Optimization , author=. arXiv preprint arXiv:2605.13217 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Distilling the Knowledge in a Neural Network
Distilling the Knowledge in a Neural Network , author=. arXiv preprint arXiv:1503.02531 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Self-Distilled Agentic Reinforcement Learning
Self-Distilled Agentic Reinforcement Learning , author=. arXiv preprint arXiv:2605.15155 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Skill-SD: Skill-Conditioned Self-Distillation for Multi-turn LLM Agents
Skill-SD: Skill-Conditioned Self-Distillation for Multi-turn LLM Agents , author=. arXiv preprint arXiv:2604.10674 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Self-Distilled RLVR , author=. arXiv preprint arXiv:2604.03128 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning , author=. arXiv preprint arXiv:2602.08234 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Skill-Pro: Learning Reusable Skills from Experience via Non-Parametric PPO for LLM Agents
Skill-Pro: Learning Reusable Skills from Experience via Non-Parametric PPO for LLM Agents , author=. arXiv preprint arXiv:2602.01869 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Dynamic Dual-Granularity Skill Bank for Agentic RL
Dynamic Dual-Granularity Skill Bank for Agentic RL , author=. arXiv preprint arXiv:2603.28716 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
RetroAgent: From Solving to Evolving via Retrospective Dual Intrinsic Feedback
RetroAgent: From Solving to Evolving via Retrospective Dual Intrinsic Feedback , author=. arXiv preprint arXiv:2603.08561 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning
Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning , author=. arXiv preprint arXiv:2605.06130 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Skill-R1: Agent Skill Evolution via Reinforcement Learning
Skill-R1: Agent Skill Evolution via Reinforcement Learning , author=. arXiv preprint arXiv:2605.09359 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
SkillOS: Learning Skill Curation for Self-Evolving Agents
SkillOS: Learning Skill Curation for Self-Evolving Agents , author=. arXiv preprint arXiv:2605.06614 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
What and When to Distill: Selective Hindsight Distillation for Multi-Turn Agents
What and When to Distill: Selective Hindsight Distillation for Multi-Turn Agents , author=. arXiv preprint arXiv:2605.19447 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes , author=. arXiv preprint arXiv:2603.25562 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
A Survey of On-Policy Distillation for Large Language Models
A Survey of On-Policy Distillation for Large Language Models , author=. arXiv preprint arXiv:2604.00626 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe , author=. arXiv preprint arXiv:2604.13016 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models , author=. arXiv preprint arXiv:2601.18734 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
ROSD: Reflective On-Policy Self-Distillation for Language Model Reasoning across Domains
ROSD: Reflective On-Policy Self-Distillation for Language Model Reasoning across Domains , author=. arXiv preprint arXiv:2605.28014 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Rebellious Student: Reversing Teacher Signals for Reasoning Exploration with Self-Distilled RLVR
Rebellious Student: Reversing Teacher Signals for Reasoning Exploration with Self-Distilled RLVR , author=. arXiv preprint arXiv:2605.10781 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
2026 , url=
Zhang, Yaocheng and Zhu, Yuanheng and Chong, Wenyue and Tu, Songjun and Zhang, Qichao and Chai, Jiajun and Wang, Xiaohan and Lin, Wei and Yin, Guojun and Zhao, Dongbin , journal=. 2026 , url=
2026
-
[35]
SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization
SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization , author=. arXiv preprint arXiv:2604.02268 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
SIRI: Self-Internalizing Reinforcement Learning with Intrinsic Skills for LLM Agent Training
SIRI: Self-Internalizing Reinforcement Learning with Intrinsic Skills for LLM Agent Training , author=. arXiv preprint arXiv:2606.02355 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Qwen2.5 Technical Report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Qwen3 Technical Report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
SKILLC: Learning Autonomous Skill Internalization in LLM Agents via Contrastive Credit Assignment
SKILLC: Learning Autonomous Skill Internalization in LLM Agents via Contrastive Credit Assignment , author=. arXiv preprint arXiv:2605.27899 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Co-Evolving Skill Generation and Policy Optimization
Co-Evolving Skill Generation and Policy Optimization , author=. arXiv preprint arXiv:2606.08755 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
StepOPSD: Step-Aware Online Preference Distillation for Agent Reinforcement Learning
StepOPSD: Step-Aware Online Preference Distillation for Agent Reinforcement Learning , author=. arXiv preprint arXiv:2605.27140 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Are Full Rollouts Necessary for On-Policy Distillation?
Are Full Rollouts Necessary for On-Policy Distillation? , author=. arXiv preprint arXiv:2605.31490 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
Advances in Neural Information Processing Systems , volume=
Webshop: Towards scalable real-world web interaction with grounded language agents , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
Trust Region Policy Optimization
Trust Region Policy Optimization , author=. arXiv preprint arXiv:1502.05477 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning , author=. arXiv preprint arXiv:1910.00177 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[46]
Proceedings of the Nineteenth International Conference on Machine Learning , pages=
Approximately Optimal Approximate Reinforcement Learning , author=. Proceedings of the Nineteenth International Conference on Machine Learning , pages=
-
[47]
International Conference on Learning Representations , year=
Mirror Descent Policy Optimization , author=. International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.