Training Verifiers to Solve Math Word Problems
Pith reviewed 2026-05-24 12:59 UTC · model grok-4.3
The pith
Training a verifier to pick the best of many model-generated solutions raises accuracy on grade school math word problems and scales better with data than fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce GSM8K and show that training verifiers to judge model-generated solutions enables reliable selection of correct answers from multiple candidates at test time, yielding higher performance on the dataset than fine-tuning alone while also scaling more effectively as training data grows.
What carries the argument
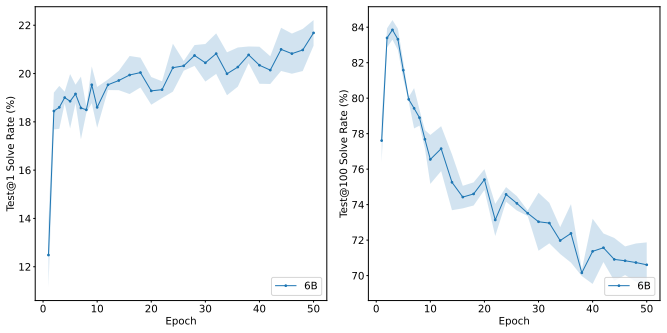
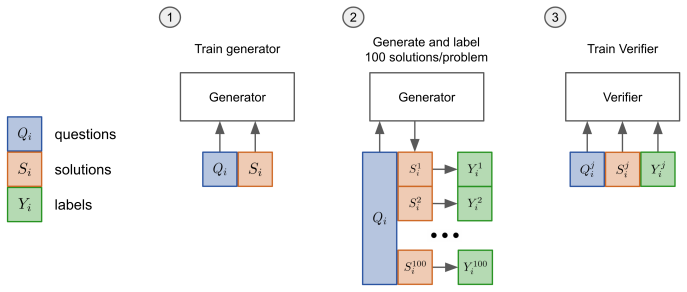
A verifier model trained to score the correctness of candidate solutions generated by the language model for each problem.
If this is right
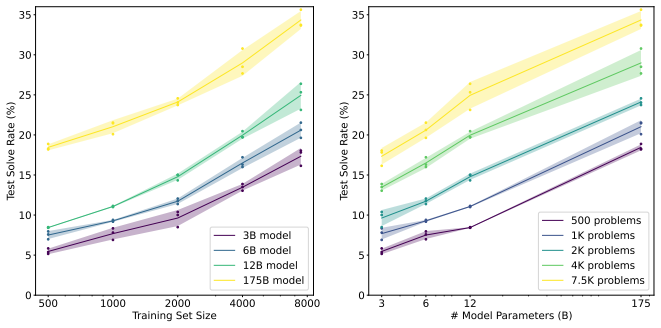
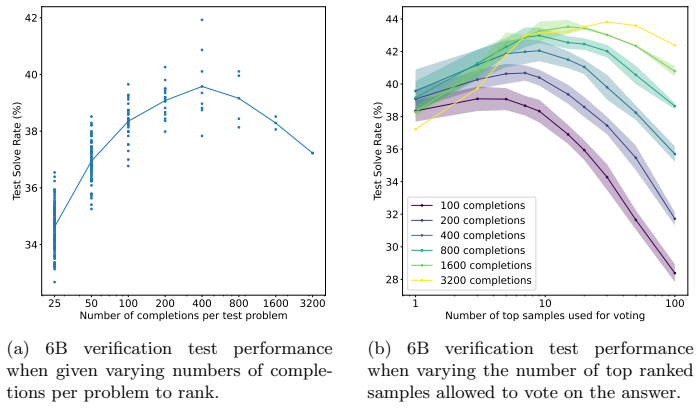
- Accuracy on GSM8K increases when the verifier is used to rank and select among many generated solutions instead of taking a single model output.
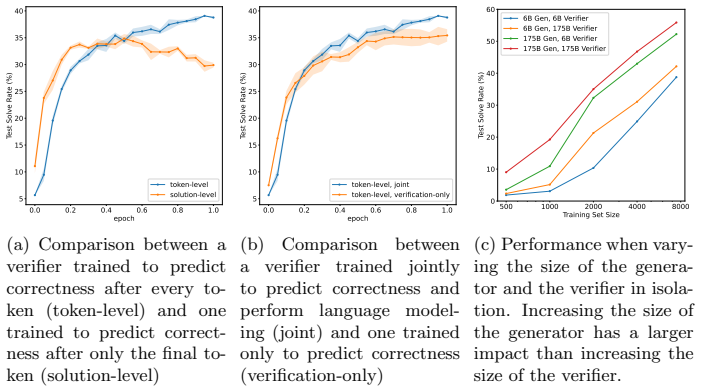
- The performance gain from the verifier grows more rapidly with additional training data than the gain from fine-tuning the solution-generating model.
- Even after fine-tuning, the largest transformer models reach only modest accuracy on the GSM8K test set without the verifier step.
Where Pith is reading between the lines
- The same generate-and-verify loop could be applied to other tasks that require chaining several reasoning steps where producing extra candidates is inexpensive.
- If the verifier generalizes across problem distributions, increasing the number of candidates tried at test time might unlock higher reliability without changing the base model.
- The results point to recognition of correct reasoning as a distinct and trainable capability separate from generation.
Load-bearing premise
A verifier trained on the model's own generated solutions can correctly identify which solutions are right on new problems where no ground-truth answer is provided.
What would settle it
On the GSM8K test set, the solution chosen by the verifier is no more often correct than a randomly chosen solution from the same set of candidates.
Figures






read the original abstract
State-of-the-art language models can match human performance on many tasks, but they still struggle to robustly perform multi-step mathematical reasoning. To diagnose the failures of current models and support research, we introduce GSM8K, a dataset of 8.5K high quality linguistically diverse grade school math word problems. We find that even the largest transformer models fail to achieve high test performance, despite the conceptual simplicity of this problem distribution. To increase performance, we propose training verifiers to judge the correctness of model completions. At test time, we generate many candidate solutions and select the one ranked highest by the verifier. We demonstrate that verification significantly improves performance on GSM8K, and we provide strong empirical evidence that verification scales more effectively with increased data than a finetuning baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the GSM8K dataset of 8.5K grade-school math word problems and proposes training a verifier on model-generated solutions (labeled correct/incorrect via ground truth) to rank and select the best completion from multiple candidates at test time. It reports that this verification procedure yields significant accuracy gains on GSM8K over a fine-tuning baseline and provides empirical evidence that verification improves more rapidly with additional training data.
Significance. If the reported gains are attributable to genuine generalization of the verifier rather than problem-specific artifacts, the work offers a practical and scalable method for improving multi-step reasoning in language models. The introduction of GSM8K as a challenging benchmark is a clear contribution, and the scaling comparison between verification and direct fine-tuning, if robust, would be a useful empirical finding for the field.
major comments (3)
- [Experiments / Verifier training procedure] The central empirical claim depends on the verifier generalizing a notion of solution correctness to the 1K unseen test problems. The manuscript trains the verifier exclusively on generations for the 7.5K training problems and does not report an analysis (e.g., verifier accuracy on held-out solutions from training problems vs. test problems, or correlation of verifier scores with correctness after controlling for problem identity) that would confirm the selection step is not exploiting training-problem-specific patterns or generation artifacts.
- [Scaling experiments / Figure on data scaling] The scaling claim (verification improves more effectively with data than fine-tuning) is presented as strong empirical evidence, yet the manuscript provides no details on the number of independent runs, error bars, or statistical tests for the curves comparing the two methods at different data scales. Without these, the differential scaling result cannot be assessed for reliability.
- [Experimental setup] The abstract and experimental sections lack explicit description of the train/validation/test splits, exact training hyperparameters for both generator and verifier, and the precise procedure for generating the candidate solutions at test time. These omissions make it difficult to reproduce or evaluate the strength of the reported performance improvements.
minor comments (2)
- [Methods] Notation for the verifier score and the selection procedure could be clarified with a short equation or pseudocode in the methods section.
- [Figures] Some figures would benefit from larger axis labels and explicit indication of which curve corresponds to verification versus the fine-tuning baseline.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on generalization, scaling reliability, and reproducibility. We address each major comment below.
read point-by-point responses
-
Referee: [Experiments / Verifier training procedure] The central empirical claim depends on the verifier generalizing a notion of solution correctness to the 1K unseen test problems. The manuscript trains the verifier exclusively on generations for the 7.5K training problems and does not report an analysis (e.g., verifier accuracy on held-out solutions from training problems vs. test problems, or correlation of verifier scores with correctness after controlling for problem identity) that would confirm the selection step is not exploiting training-problem-specific patterns or generation artifacts.
Authors: The verifier receives only solution text (no problem identifier) and is applied to entirely unseen test problems whose solutions were never seen during verifier training. Successful selection on the test set therefore requires learning general properties of correct multi-step reasoning. We agree that an explicit comparison of verifier accuracy on held-out training solutions versus test solutions would strengthen the argument and will add this analysis in the revision. revision: partial
-
Referee: [Scaling experiments / Figure on data scaling] The scaling claim (verification improves more effectively with data than fine-tuning) is presented as strong empirical evidence, yet the manuscript provides no details on the number of independent runs, error bars, or statistical tests for the curves comparing the two methods at different data scales. Without these, the differential scaling result cannot be assessed for reliability.
Authors: We will revise the scaling section to report the number of independent runs and include error bars on the data-scaling figure so that the reliability of the observed differential trend can be directly evaluated. revision: yes
-
Referee: [Experimental setup] The abstract and experimental sections lack explicit description of the train/validation/test splits, exact training hyperparameters for both generator and verifier, and the precise procedure for generating the candidate solutions at test time. These omissions make it difficult to reproduce or evaluate the strength of the reported performance improvements.
Authors: We will expand the experimental setup to state the exact splits (7.5K train / 1K test), list the training hyperparameters for both models, and detail the candidate-generation procedure (number of samples, sampling temperature, etc.). revision: yes
Circularity Check
Purely empirical study; no derivation reduces to fitted input by construction
full rationale
The paper introduces the GSM8K dataset and reports experimental results on training verifiers to rank model-generated solutions for math word problems. Performance gains are shown via test-time selection of highest-scoring candidates, with scaling comparisons to finetuning. No equations, uniqueness theorems, ansatzes, or predictions are claimed; all results are direct empirical measurements on held-out test problems. No self-citation chains or self-definitional reductions appear in the described method. The verifier training uses ground-truth labels only on training generations, and test-time selection is evaluated on unseen problems, keeping the central claim externally falsifiable rather than tautological.
Axiom & Free-Parameter Ledger
free parameters (1)
- verifier and generator training hyperparameters
axioms (1)
- domain assumption Language models can be prompted or sampled to produce multiple diverse candidate solutions
Forward citations
Cited by 60 Pith papers
-
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Chain-of-thought prompting, by including intermediate reasoning steps in few-shot examples, elicits strong reasoning abilities in large language models on arithmetic, commonsense, and symbolic tasks.
-
Behavior Cloning is Not All You Need: The Optimality of On-Policy Distillation for Noisy Expert Feedback
Noisy expert imitation learning requires exponential samples for offline methods but polynomial for a variant of on-policy distillation under a noise condition.
-
Analyzing the Narration Gap in LLM-Solver Loops
The narration step in LLM-solver loops is vulnerable to prompt injection that inverts verified solver conclusions, and hardened prompts reduce but do not eliminate the risk under adaptive attacks.
-
Sumi: Open Uniform Diffusion Language Model from Scratch
Sumi is an openly released 7B parameter uniform diffusion language model pretrained from scratch on 1.5T tokens that matches autoregressive models on several benchmarks.
-
DeFAb: A Verifiable Benchmark for Defeasible Abduction in Foundation Models
DeFAb is a large-scale, formally verifiable benchmark for defeasible abduction derived from 18 knowledge bases, demonstrating that frontier LLMs achieve 7.8-65% accuracy versus 100% for a rule-based solver with polyno...
-
Entropy-Gated Latent Recursion
EGLR adds a deterministic layer-recursion axis gated by entropy that is complementary to temperature sampling, raising joint oracle accuracy on MATH-500 from 83.4% to 91.6% for a 3B model.
-
Fully Open Meditron: An Auditable Pipeline for Clinical LLMs
Presents the first fully open pipeline for clinical LLMs by unifying eight public QA datasets with three clinician-vetted synthetic extensions and applying it to five base models to achieve benchmark gains while maint...
-
DualKV: Shared-Prompt Flash Attention for Efficient RL Training with Large Rollouts and Long Contexts
DualKV is a new FlashAttention variant that shares prompt KV across multiple rollouts in RL training, delivering 1.63-3.82x speedups on 8B-30B models while remaining mathematically identical to standard attention.
-
Mistletoe: Stealthy Acceleration-Collapse Attacks on Speculative Decoding
Mistletoe introduces a stealthy attack on speculative decoding that collapses acceleration by reducing average accepted length while preserving output semantics.
-
HodgeCover: Higher-Order Topological Coverage Drives Compression of Sparse Mixture-of-Experts
HodgeCover isolates the harmonic kernel of a simplicial Laplacian on an expert 2-complex to identify irreducible merge cycles and selects experts for aggressive compression, matching or exceeding baselines on open-wei...
-
FlowCompile: An Optimizing Compiler for Structured LLM Workflows
FlowCompile performs compile-time design space exploration on structured LLM workflows to produce reusable high-quality configuration sets that outperform routing baselines with up to 6.4x speedup.
-
Grid Games: The Power of Multiple Grids for Quantizing Large Language Models
Allowing each quantization group to select among multiple 4-bit grids improves accuracy over single-grid FP4 for both post-training and pre-training of LLMs.
-
The Last Word Often Wins: A Format Confound in Chain-of-Thought Corruption Studies
Corruption studies of CoT faithfulness largely measure explicit answer placement in prompt format rather than computational importance of reasoning steps.
-
Soohak: A Mathematician-Curated Benchmark for Evaluating Research-level Math Capabilities of LLMs
Soohak is a 439-problem mathematician-curated benchmark where frontier LLMs reach at most 30.4% on research math challenges and no model exceeds 50% on refusal for ill-posed problems.
-
Soohak: A Mathematician-Curated Benchmark for Evaluating Research-level Math Capabilities of LLMs
Soohak is a new 439-problem mathematician-authored benchmark showing frontier LLMs reach only 30% on research math and fail to exceed 50% on refusing ill-posed questions.
-
MathConstraint: Automated Generation of Verified Combinatorial Reasoning Instances for LLMs
MathConstraint generates scalable, automatically verifiable combinatorial problems where LLMs achieve 18.5-66.9% accuracy without tools but roughly double that with solver access.
-
The Coupling Tax: How Shared Token Budgets Undermine Visible Chain-of-Thought Under Fixed Output Limits
Shared token budgets between visible chain-of-thought and answers create a coupling tax that makes non-thinking competitive on math benchmarks, with a truncation decomposition predicting the crossover and split budget...
-
From Context to Skills: Can Language Models Learn from Context Skillfully?
Ctx2Skill lets language models autonomously evolve context-specific skills via multi-agent self-play, improving performance on context learning tasks without human supervision.
-
MathNet: a Global Multimodal Benchmark for Mathematical Reasoning and Retrieval
MathNet delivers the largest multilingual Olympiad math dataset and benchmarks where models like Gemini-3.1-Pro reach 78% on solving but embedding models struggle on equivalent problem retrieval, with retrieval augmen...
-
Agent^2 RL-Bench: Can LLM Agents Engineer Agentic RL Post-Training?
Agent^2 RL-Bench shows LLM agents can achieve large RL gains on some tasks like ALFWorld (5.97 to 93.28) via SFT and online rollouts but only marginal progress on others, with supervised pipelines dominating under fix...
-
Beyond Accuracy: Diagnosing Algebraic Reasoning Failures in LLMs Across Nine Complexity Dimensions
A nine-dimension algebraic complexity framework shows that LLMs suffer a scale-invariant working memory bottleneck, collapsing at 20-30 parallel branches regardless of parameter count from 8B to 235B.
-
Beyond the Assistant Turn: User Turn Generation as a Probe of Interaction Awareness in Language Models
User-turn generation reveals that LLMs' interaction awareness is largely decoupled from task accuracy, remaining near zero in deterministic settings even as accuracy scales to 96.8% on GSM8K.
-
Self-Calibrating Language Models via Test-Time Discriminative Distillation
SECL reduces expected calibration error in language models by 56-78% via test-time discriminative distillation from the model's own P(True) signal, adapting on only 6-26% of inputs.
-
Reinforcement Learning for Diffusion LLMs with Entropy-Guided Step Selection and Stepwise Advantages
Derives an exact unbiased policy gradient for RL post-training of diffusion LLMs via entropy-guided step selection and one-step denoising rewards, achieving state-of-the-art results on coding and logical reasoning benchmarks.
-
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding
Molmo2 delivers state-of-the-art open-weight video VLMs with new grounding datasets and training methods that outperform prior open models and match or exceed some proprietary ones on pointing and tracking tasks.
-
DeepMath-103K: A Large-Scale, Challenging, Decontaminated, and Verifiable Mathematical Dataset for Advancing Reasoning
DeepMath-103K is a new 103K-problem mathematical dataset with high difficulty, rigorous decontamination, and verifiable answers to support RL training of language-model reasoning.
-
Why Do Multi-Agent LLM Systems Fail?
The authors create the first large-scale dataset and taxonomy of failure modes in multi-agent LLM systems to explain their limited performance gains.
-
Large Language Diffusion Models
LLaDA is a scalable diffusion-based language model that matches autoregressive LLMs like LLaMA3 8B on tasks and surpasses GPT-4o on reversal poem completion.
-
Training Software Engineering Agents and Verifiers with SWE-Gym
SWE-Gym supplies 2438 executable real-world Python tasks to train SWE agents and verifiers, yielding up to 19% gains and new open-weight SOTA of 32% on SWE-Bench Verified.
-
ErrorRadar: Benchmarking Complex Mathematical Reasoning of Multimodal Large Language Models Via Error Detection
ErrorRadar is a new benchmark of 2,500 multimodal K-12 math problems for MLLM error step identification and categorization, where GPT-4o trails human experts by ~10%.
-
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models
Molmo VLMs trained on newly collected PixMo open datasets achieve state-of-the-art performance among open-weight models and surpass multiple proprietary VLMs including Claude 3.5 Sonnet and Gemini 1.5 Pro.
-
LiveBench: A Challenging, Contamination-Limited LLM Benchmark
LiveBench is a contamination-limited LLM benchmark with auto-scored challenging tasks from recent sources across math, coding, reasoning and more, where top models score below 70%.
-
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
DSPy compiles short declarative programs into LM pipelines that self-optimize and outperform both standard few-shot prompting and expert-written chains on math, retrieval, and QA tasks.
-
PAL: Program-aided Language Models
PAL improves few-shot reasoning accuracy by having LLMs generate executable programs rather than text-based chains of thought, outperforming much larger models on math and logic benchmarks.
-
Code as Policies: Language Model Programs for Embodied Control
Language models generate robot policy code from natural language commands via few-shot prompting, enabling spatial-geometric reasoning, generalization, and precise control on real robots.
-
Fora: From Weight-Space to Function-Space Protection in Capability-Preserving Fine-Tuning
FORA improves capability preservation in LLM fine-tuning by using function-space projections from activation covariances instead of weight-space singular vectors.
-
Indi-RomCoM: Code-Mixed Benchmark for Evaluating LLMs on Romanized Indic-English Instructions
Introduces Indi-RomCoM benchmark for evaluating LLMs on Romanized code-mixed Indic-English instructions across seven tasks, four languages, and three mixing levels.
-
Predictable GRPO: A Closed-Form Model of Training Dynamics
A closed-form inertial model of GRPO dynamics that subsumes single-exponential saturation as its overdamped limit and predicts group-size invariance, stability thresholds, and overdamped-to-oscillatory transitions.
-
When Does Online Imitation Learning Help in LLM Post-Training? The Role of (Non-)Realizability Beyond Horizon
Online IL overcomes an information-theoretic bottleneck that offline IL faces in non-realizable settings even at horizon 1, under a new structural characterization of reward-relative misspecification.
-
Why Struggle with Continuous Latents? Interpretable Discrete Latent Reasoning via Rendered Compression
DLR creates discrete latent tokens from rendered CoT images via clustering, enabling up to 20x compression and interpretable trajectories that outperform continuous latent baselines on reasoning tasks.
-
CRAFT: Counterfactual Credit Assignment from Free Sibling Rollouts for Self-Distilled Agentic Reinforcement Learning
CRAFT is a three-pillar credit assignment scheme that uses counterfactual token importance from GRPO sibling rollouts to provide signed per-token distillation signals in self-distilled agentic RL.
-
The Complexity Ceiling Benchmark: A Multi-Domain Evaluation of Sequential Reasoning Under Depth Scaling
The Complexity Ceiling Benchmark demonstrates geometric per-step decay in LLM sequential reasoning with domain-specific performance ceilings and introduces a trace metric showing incorrect intermediate steps in some c...
-
Minority Sentinel: When to Overturn Majority Voting in Multi-Agent LLM Debates
Minority Sentinel uses a LightGBM model on debate fingerprints to overturn majority votes in LLM debates with 81.2% flip precision and positive net gain on six benchmarks.
-
Flow Reasoning Models: Scaling Reasoning Through Iterative Self-Refinement
Flow models reach 99.2% Sudoku accuracy in 7 passes and 96.1% on out-of-distribution Sudoku-Extreme by selecting dynamically stable candidates and training with self-conditioning plus DPO to avoid failed outputs.
-
Agentic Abstention: Do Agents Know When to Stop Instead of Act?
LLM agents often fail to abstain at the right time in uncertain multi-turn tasks, and the CONVOLVE context engineering method raises timely abstention rates on WebShop from 26.7 to 57.4 without parameter updates.
-
VGB for Masked Diffusion Model: Efficient Test-time Scaling for Reward Satisfaction and Sample Editing
MDM-VGB augments masked diffusion with backtracking-style reward-guided remasking to achieve quadratic-complexity high-reward generation and sample editing, with proofs of noise robustness.
-
Masked Language Flow Models
MLFMs combine masking with continuous flows to scale flow-based language models to reasoning and instruction-following tasks on GSM8K and MT-Bench.
-
GeMoE: Gating Entropy is All You Need for Uncertainty-aware Adaptive Routing in MoE-based Large Vision-Language Models
GeMoE adaptively sets the number of experts per token via gating entropy, retaining 99.5% of static-routing performance while raising average sparsity by 36.5%.
-
Cliff Tokens: Identifying Single-Token Failure Triggers in LLM Mathematical Reasoning
Cliff tokens are single-token failure triggers in LLM mathematical reasoning identified via adaptive statistical threshold; intervening at them recovers performance to 1.0 in resampling and yields up to +6.6 accuracy ...
-
Cliff Tokens: Identifying Single-Token Failure Triggers in LLM Mathematical Reasoning
Cliff tokens are single tokens triggering LLM math reasoning failures, identified via adaptive z-test threshold on token potential; a taxonomy and Cliff-DPO optimization yield up to +6.6 accuracy gains.
-
Transition-Aware best-of-N sampling for Longitudinal Chest X-ray Reports
Transition-aware best-of-N sampling embeds report sentences as sets, computes directional transition vectors via set-to-set distances, and scores candidates by proximity to ground-truth training transitions.
-
What Does It Mean to Break a Distillation Defense?
The paper introduces a three-dimensional threat model framework for distillation defenses and shows via case study that defense effectiveness depends on the assumed attacker capabilities.
-
A Verifiable Search Is Not a Learnable Chain-of-Thought
Verifiable search procedures cannot be learned as forward chain-of-thought by language models; they instead learn memorization, verification, or require precomputed catalogs.
-
Denoising Iterative Self-Correction: Structured Verification Loops for Reliable LLM Reasoning
DISC is a new iterative verify-judge-correct procedure for LLMs that improves accuracy on reasoning benchmarks by modeling verification as denoising signals and using a gate to control correction precision.
-
From Efficiency to Leakage -- Privacy Backdoor in Federated Language Model Fine-Tuning
NeuroImprint attack assigns isolated memorization neurons to training samples in PEFT adapters, enabling closed-form reconstruction of 59-79% of samples across BERT, GPT-2, Qwen2, and Llama3.2 on multiple datasets.
-
SIGMA: Skill-Incidence Graphs for Compositional Multi-Agent Design
SIGMA introduces skill-incidence graphs to compose agents from reusable skills, yielding higher average performance and robustness than topology-only baselines on reasoning and coding benchmarks.
-
Predicting Mergeability of Parameter-Efficient Fine-Tuning Updates
MergeProbe forecasts LoRA adapter mergeability from first-few-percent training signals and outperforms interference-aware baselines on retention while adding low overhead on a five-domain benchmark.
-
DreamReasoner-8B: Block-Size Curriculum Learning for Diffusion Reasoning Models
Block-size curriculum learning trains an 8B diffusion model to achieve competitive reasoning performance on math and code benchmarks by transitioning from small to large training block sizes.
-
Thermodynamic Signatures of Reasoning: Free-Energy and Spectral-Form-Factor Diagnostics for Hallucination Detection in Large Language Models
Introduces thermodynamic free-energy signatures and spectral form factors from attention Laplacians for hallucination detection, with stability proofs, expressiveness results, a PAC bound, and empirical AUROC gains ov...
-
Learning from Your Own Mistakes: Constructing Learnable Micro-Reflective Trajectories for Self-Distillation
TAPO constructs learnable micro-reflective trajectories from contrastive model rollouts during RL training to provide explicit error diagnoses and corrections, reporting consistent gains over GRPO on AIME and HMMT mat...
Reference graph
Works this paper leans on
-
[1]
MathQA: Towards Interpretable Math Word Problem Solving with Operation-Based Formalisms
A. Amini, S. Gabriel, P. Lin, R. Koncel-Kedziorski, Y. Choi, and H. Hajishirzi. Mathqa: Towards interpretable math word problem solving with operation- based formalisms. arXiv preprint arXiv:1905.13319 ,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[2]
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Nee- lakantan, P. Shyam, G. Sastry, A. Askell, et al. Language models are few-shot learners. arXiv preprint arXiv:2005.14165 ,
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[3]
Semantically-Aligned Equation Generation for Solving and Reasoning Math Word Problems
T.-R. Chiang and Y.-N. Chen. Semantically-aligned equation generation for solving and reasoning math word problems. arXiv preprint arXiv:1811.00720 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Measuring Mathematical Problem Solving With the MATH Dataset
D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361 ,
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[6]
B. Kim, K. S. Ki, D. Lee, and G. Gweon. Point to the expression: Solving algebraic word problems using the expression-pointer transformer model. In Proceedings of the 2020 Conference on Empirical Methods in Natural Lan- guage Processing (EMNLP) , pages 3768–3779,
work page 2020
-
[7]
Deep learning for symbolic mathematics.arXiv preprint arXiv:1912.01412, 2019
G. Lample and F. Charton. Deep learning for symbolic mathematics. arXiv preprint arXiv:1912.01412,
-
[8]
W. Ling, D. Yogatama, C. Dyer, and P. Blunsom. Program induction by ra- tionale generation: Learning to solve and explain algebraic word problems. arXiv preprint arXiv:1705.04146 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
S.-Y. Miao, C.-C. Liang, and K.-Y. Su. A diverse corpus for evaluat- ing and developing english math word problem solvers. arXiv preprint arXiv:2106.15772,
-
[10]
E. Nichols, L. Gao, and R. Gomez. Collaborative storytelling with large-scale neural language models. arXiv preprint arXiv:2011.10208 ,
- [11]
- [12]
-
[13]
URLhttps://aclanthology.org/D15-1202/
Associ- ation for Computational Linguistics. doi: 10.18653/v1/D15-1202. URL https://aclanthology.org/D15-1202. J. Shen, Y. Yin, L. Li, L. Shang, X. Jiang, M. Zhang, and Q. Liu. Generate & rank: A multi-task framework for math word problems. arXiv preprint arXiv:2109.03034, 2021a. J. T. Shen, M. Yamashita, E. Prihar, N. Heffernan, X. Wu, B. Graff, and D. Lee...
-
[14]
CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge
A. Talmor, J. Herzig, N. Lourie, and J. Berant. Commonsenseqa: A ques- tion answering challenge targeting commonsense knowledge. arXiv preprint arXiv:1811.00937,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
A. Wang, Y. Pruksachatkun, N. Nangia, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman. Superglue: A stickier benchmark for general-purpose language understanding systems. arXiv preprint arXiv:1905.00537 ,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[16]
Y. Wang, X. Liu, and S. Shi. Deep neural solver for math word problems. In Proceedings of the 2017 Conference on Empirical Methods in Natural Lan- guage Processing, pages 845–854, Copenhagen, Denmark, Sept
work page 2017
-
[17]
Asso- ciation for Computational Linguistics. doi: 10.18653/v1/D17-1088. URL https://aclanthology.org/D17-1088. Z. Xie and S. Sun. A goal-driven tree-structured neural model for math word problems. In IJCAI,
- [18]
-
[19]
Qi Sj the i-th question token the j-th solution token Q1 Language Modeling Objective Q2 ... Qn Q2 Q3 ... S1 S2 ... Sm-1 S2 S3 ... Sm Generator S1 Q1 Verifier Objective Q2 ... Qn Y1 Y2 ... S1 S2 ... Sm Yn+1 Yn+2 ... Yn+m Verifier Yn Yk the k-th value prediction masked out (does not contribute to loss) Figure 12: Visualization of the joint training objectiv...
work page 2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.