Matrix-game 2.0: An open-source real-time and streaming interactive world model
Pith reviewed 2026-05-18 22:32 UTC · model grok-4.3
The pith
Matrix-Game 2.0 generates high-quality minute-long interactive videos at 25 frames per second using few-step auto-regressive diffusion.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
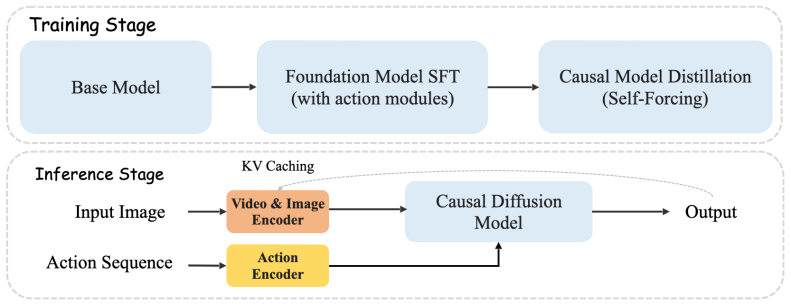
Matrix Game 2.0 is an interactive world model that generates long videos on-the-fly via few-step auto-regressive diffusion. The framework consists of a scalable data production pipeline that yields about 1200 hours of video with interaction annotations from Unreal Engine and GTA5 environments, an action injection module that accepts frame-level mouse and keyboard inputs as conditions, and few-step distillation based on the causal architecture to enable real-time and streaming video generation. The result is high-quality minute-level videos across diverse scenes at an ultra-fast speed of 25 FPS.
What carries the argument
Few-step distillation on the causal architecture that supports real-time streaming generation conditioned on live mouse and keyboard inputs.
If this is right
- Real-world dynamics can be simulated with outcomes that update instantaneously based on historical context and current actions.
- High-quality video generation becomes feasible at speeds that support live interactive applications.
- Open release of weights and code enables community extensions for new interactive scenarios.
Where Pith is reading between the lines
- The streaming design could support continuous multi-agent environments where multiple users or AI controllers act simultaneously.
- If the input conditioning generalizes, similar distillation might apply to real-time control of physical systems such as robots.
- Minute-scale coherence at real-time speeds opens the possibility of using these models as persistent backdrops for reinforcement learning experiments.
Load-bearing premise
Training on interaction-annotated video from simulated game environments plus few-step distillation will keep both visual quality and accurate low-latency responses to live inputs without artifacts or lag.
What would settle it
A live session in which rapid mouse movements and key presses are fed to the model and the output video is examined for exact action correspondence, absence of lag, and lack of visual artifacts over a continuous minute-long sequence.
Figures
















read the original abstract
Recent advances in interactive video generations have demonstrated diffusion model's potential as world models by capturing complex physical dynamics and interactive behaviors. However, existing interactive world models depend on bidirectional attention and lengthy inference steps, severely limiting real-time performance. Consequently, they are hard to simulate real-world dynamics, where outcomes must update instantaneously based on historical context and current actions. To address this, we present Matrix-Game 2.0, an interactive world model generates long videos on-the-fly via few-step auto-regressive diffusion. Our framework consists of three key components: (1) A scalable data production pipeline for Unreal Engine and GTA5 environments to effectively produce massive amounts (about 1200 hours) of video data with diverse interaction annotations; (2) An action injection module that enables frame-level mouse and keyboard inputs as interactive conditions; (3) A few-step distillation based on the casual architecture for real-time and streaming video generation. Matrix Game 2.0 can generate high-quality minute-level videos across diverse scenes at an ultra-fast speed of 25 FPS. We open-source our model weights and codebase to advance research in interactive world modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Matrix-Game 2.0, an interactive world model that generates long (minute-scale) videos on-the-fly via few-step auto-regressive diffusion. The framework comprises three components: a scalable data pipeline producing ~1200 hours of interaction-annotated video from Unreal Engine and GTA5, an action-injection module that conditions generation on frame-level mouse/keyboard inputs, and few-step distillation of a causal architecture to achieve real-time streaming at 25 FPS. The work is open-sourced.
Significance. If the central performance claims hold, the result would be a meaningful engineering advance for real-time interactive world models, directly addressing the inference-speed bottleneck of prior bidirectional diffusion approaches. The combination of large-scale annotated simulation data, explicit action conditioning, and distillation for causal rollouts, together with the release of weights and code, would supply a reproducible baseline that could accelerate research on streaming, action-responsive video generation.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): The headline claim of “high-quality minute-level videos … at an ultra-fast speed of 25 FPS” is presented without any quantitative metrics (e.g., PSNR/SSIM/FVD over 1500-frame rollouts, action-fidelity scores, or latency measurements), ablation tables, or direct comparisons to teacher models or prior interactive baselines. Without these data the central real-time usability assertion cannot be evaluated.
- [§3.3] §3.3 (Few-step distillation): The manuscript asserts that few-step distillation on the causal architecture preserves both visual quality and precise frame-level responsiveness to live inputs across minute-scale sequences. No long-horizon consistency metrics, error-accumulation analysis, or ablation on distillation step count are reported; this is load-bearing for the 25 FPS streaming claim because distillation is known to collapse denoising trajectories and can amplify drift in auto-regressive conditioning.
minor comments (2)
- [§2] §2 (Related work): The discussion of bidirectional versus causal attention would benefit from a concise complexity table (FLOPs per frame) to quantify the claimed efficiency gain.
- [Figure captions and §4] Figure captions and §4: Several result figures lack axis labels or error bars; add these for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below. Where the comments correctly identify gaps in quantitative support, we have revised the manuscript to include the requested evaluations.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The headline claim of “high-quality minute-level videos … at an ultra-fast speed of 25 FPS” is presented without any quantitative metrics (e.g., PSNR/SSIM/FVD over 1500-frame rollouts, action-fidelity scores, or latency measurements), ablation tables, or direct comparisons to teacher models or prior interactive baselines. Without these data the central real-time usability assertion cannot be evaluated.
Authors: We agree that the original manuscript would benefit from explicit quantitative backing for the real-time claims. In the revised version we have expanded §4 with FVD and perceptual metrics computed over 1500-frame auto-regressive rollouts, frame-level action-fidelity scores that quantify adherence to live mouse/keyboard inputs, and wall-clock latency measurements confirming sustained 25 FPS generation. We also added ablation tables isolating the contributions of the data pipeline, action-injection module, and distillation, plus direct numerical comparisons against the teacher model and representative prior interactive video baselines. revision: yes
-
Referee: [§3.3] §3.3 (Few-step distillation): The manuscript asserts that few-step distillation on the causal architecture preserves both visual quality and precise frame-level responsiveness to live inputs across minute-scale sequences. No long-horizon consistency metrics, error-accumulation analysis, or ablation on distillation step count are reported; this is load-bearing for the 25 FPS streaming claim because distillation is known to collapse denoising trajectories and can amplify drift in auto-regressive conditioning.
Authors: We concur that long-horizon stability after distillation is critical and was under-supported. The revised §3.3 now reports long-horizon consistency metrics (frame-wise PSNR and LPIPS over minute-scale sequences), an explicit error-accumulation study tracking drift in both visual quality and action responsiveness, and an ablation varying the distillation step count (1-step, 2-step, 4-step) that demonstrates preservation of interactivity with negligible additional drift relative to the teacher. revision: yes
Circularity Check
No significant circularity in claimed results
full rationale
The paper describes an engineering system with three components: a data production pipeline yielding 1200 hours of annotated video from Unreal Engine and GTA5, an action injection module for mouse/keyboard inputs, and few-step distillation on a causal architecture. No equations, fitted parameters, or first-principles derivations are presented that would make the reported 25 FPS minute-scale generation reduce to a self-defined metric or input by construction. Performance claims are empirical outcomes of the implemented pipeline rather than predictions forced by prior fits or self-citations. The derivation chain is self-contained against external benchmarks such as generated video quality and real-time responsiveness.
Axiom & Free-Parameter Ledger
free parameters (1)
- distillation step count
axioms (1)
- domain assumption Diffusion models trained on large amounts of annotated game video can capture interactive physical dynamics sufficiently for real-time simulation.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
few-step distillation based on the casual architecture for real-time and streaming video generation... Self-Forcing [18] based techniques... KV caching mechanism
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
action injection module that enables frame-level mouse and keyboard inputs
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 27 Pith papers
-
Incantation: Natural Language as the Action Interface for Multi-Entity Video World Models
Incantation is the first video world model to use per-frame natural language conditioning for simultaneous multi-entity control and concept-level cross-entity transfer in interactive video generation.
-
WorldMark: A Unified Benchmark Suite for Interactive Video World Models
WorldMark is the first public benchmark that standardizes scenes, trajectories, and control interfaces across heterogeneous interactive image-to-video world models.
-
Efficient Video Diffusion Models: Advancements and Challenges
A survey that groups efficient video diffusion methods into four paradigms—step distillation, efficient attention, model compression, and cache/trajectory optimization—and outlines open challenges for practical use.
-
MoRight: Motion Control Done Right
MoRight disentangles object and camera motion via canonical-view specification and temporal cross-view attention, while decomposing motion into active user-driven and passive consequence components to learn and apply ...
-
One-to-All Animation: Alignment-Free Character Animation and Image Pose Transfer
One-to-All Animation enables alignment-free character animation and image pose transfer via self-supervised outpainting reformulation, reference extraction, hybrid fusion attention, identity-robust pose control, and t...
-
Training Agents Inside of Scalable World Models
Dreamer 4 is the first agent to obtain diamonds in Minecraft from only offline data by reinforcement learning inside a scalable world model that accurately predicts game mechanics.
-
WorldKV: Efficient World Memory with World Retrieval and Compression
WorldKV enables persistent world memory in autoregressive video diffusion models by selectively retrieving and compressing KV-cache chunks, matching full-cache fidelity at roughly twice the throughput without training.
-
World-Ego Modeling for Long-Horizon Evolution in Hybrid Embodied Tasks
Proposes World-Ego Modeling with WEM using CP-MoE diffusion and a new HTEWorld benchmark, claiming SOTA on hybrid navigation-manipulation tasks.
-
Pyramid Forcing: Head-Aware Pyramid KV Cache Policy for High-Quality Long Video Generation
Pyramid Forcing classifies attention heads into Anchor, Wave, and Veil types and applies type-specific KV cache policies to improve long-horizon autoregressive video generation quality.
-
Divide and Conquer: Decoupled Representation Alignment for Multimodal World Models
M²-REPA decouples modality-specific features inside a diffusion model and aligns each to its matching expert foundation model via an alignment loss plus a decoupling regularizer, yielding better visual quality and lon...
-
Memorize When Needed: Decoupled Memory Control for Spatially Consistent Long-Horizon Video Generation
A decoupled memory branch with hybrid cues, cross-attention, and gating improves spatial consistency and data efficiency in long-horizon camera-trajectory video generation.
-
Lyra 2.0: Explorable Generative 3D Worlds
Lyra 2.0 produces persistent 3D-consistent video sequences for large explorable worlds by using per-frame geometry for information routing and self-augmented training to correct temporal drift.
-
INSPATIO-WORLD: A Real-Time 4D World Simulator via Spatiotemporal Autoregressive Modeling
INSPATIO-WORLD is a real-time framework for high-fidelity 4D scene generation and navigation from monocular videos via STAR architecture with implicit caching, explicit geometric constraints, and distribution-matching...
-
UNICA: A Unified Neural Framework for Controllable 3D Avatars
UNICA unifies motion planning, rigging, physical simulation, and rendering into a single skeleton-free neural framework that produces next-frame 3D avatar geometry from action inputs and renders it with Gaussian splatting.
-
Video Generation Models as World Models: Efficient Paradigms, Architectures and Algorithms
Video generation models can function as world simulators if efficiency gaps in spatiotemporal modeling are bridged via organized paradigms, architectures, and algorithms.
-
Quant VideoGen: Auto-Regressive Long Video Generation via 2-Bit KV-Cache Quantization
Quant VideoGen reduces KV cache memory by up to 7 times in autoregressive video diffusion models via semantic aware smoothing and progressive residual quantization, achieving better quality than baselines with under 4...
-
AstraNav-World: World Model for Foresight Control and Consistency
AstraNav-World unifies diffusion video generation and vision-language action planning in a single bidirectional model that improves trajectory accuracy, success rates, and zero-shot real-world adaptation in embodied n...
-
WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Modeling
WorldPlay uses dual action representation, reconstituted context memory, and context forcing distillation to produce consistent 720p streaming video at 24 FPS for interactive world modeling.
-
Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
Self-Forcing++ scales autoregressive video diffusion to over 4 minutes by using self-generated segments for guidance, reducing error accumulation and outperforming baselines in fidelity and consistency.
-
OrbiSim: World Models as Differentiable Physics Engines for Embodied Intelligence
OrbiSim builds a differentiable physics engine from world models to support gradient-based policy optimization and contact modeling in robotics.
-
Towards Generalist Game Players: An Investigation of Foundation Models in the Game Multiverse
The paper organizes research on generalist game AI into Dataset, Model, Harness, and Benchmark pillars and charts a five-level progression from single-game mastery to agents that create and live inside game multiverses.
-
Neural Computers
Neural Computers are introduced as a new machine form where computation, memory, and I/O are unified in a learned runtime state, with initial video-model experiments showing acquisition of basic interface primitives f...
-
Cloning Deterministic Worlds: The Critical Role of Latent Geometry in Long-Horizon World Models
GRWM uses temporal contrastive learning to geometrically regularize latent spaces in world models for high-fidelity cloning of deterministic 3D worlds.
-
Matrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory
Matrix-Game 3.0 delivers 720p real-time video generation at 40 FPS with minute-scale memory consistency by combining residual self-correction training, camera-aware memory injection, and DMD-based autoregressive disti...
-
OpenWorldLib: A Unified Codebase and Definition of Advanced World Models
OpenWorldLib offers a standardized codebase and definition for world models that combine perception, interaction, and memory to understand and predict the world.
-
Advancing Open-source World Models
LingBot-World is presented as an open-source world model that delivers high-fidelity simulation, minute-level contextual consistency, and real-time interactivity under one second latency.
-
Towards Generalist Game Players: An Investigation of Foundation Models in the Game Multiverse
This work traces four eras of generalist game players across dataset, model, harness, and benchmark pillars and charts a five-level roadmap ending in agents that create and evolve within game multiverses.
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos: world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Philip J. Ball, Jakob Bauer, Frank Belletti, Bethanie Brownfield, Ariel Ephrat, Shlomi Fruchter, Agrim Gupta, Kristian Holsheimer, Aleksander Holynski, Jiri Hron, Christos Kaplanis, Marjorie Limont, Matt McGill, Yanko Oliveira, Jack Parker-Holder, Frank Perbet, Guy Scully, Jeremy Shar, Stephen Spencer, Omer Tov, Ruben Villegas, Emma Wang, Jessica Yung, Ci...
work page 2025
-
[3]
V-jepa: Latent video prediction for visual representation learning
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mido Assran, and Nicolas Ballas. V-jepa: Latent video prediction for visual representation learning. 2023
work page 2023
-
[4]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. In International Conference on Machine Learning , 2024
work page 2024
-
[6]
Gamegen-x: Interactive open-world game video generation.arXiv preprint arXiv:2411.00769, 2024
Haoxuan Che, Xuanhua He, Quande Liu, Cheng Jin, and Hao Chen. Gamegen-x: Interactive open-world game video generation. arXiv preprint arXiv:2411.00769, 2024
-
[7]
Diffusion forcing: Next-token prediction meets full-sequence diffusion
Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion. Advances in Neural Information Processing Systems, 37:24081–24125, 2024
work page 2024
-
[8]
SkyReels-V2: Infinite-length Film Generative Model
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengcheng Ma, et al. Skyreels-v2: Infinite-length film generative model. arXiv preprint arXiv:2504.13074, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Deepverse: 4d autoregressive video generation as a world model.arXiv preprint arXiv:2506.01103, 2025
Junyi Chen, Haoyi Zhu, Xianglong He, Yifan Wang, Jianjun Zhou, Wenzheng Chang, Yang Zhou, Zizun Li, Zhoujie Fu, Jiangmiao Pang, et al. Deepverse: 4d autoregressive video generation as a world model. arXiv preprint arXiv:2506.01103, 2025
-
[10]
Seine: Short-to-long video diffusion model for generative transition and prediction
Xinyuan Chen, Yaohui Wang, Lingjun Zhang, Shaobin Zhuang, Xin Ma, Jiashuo Yu, Yali Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. Seine: Short-to-long video diffusion model for generative transition and prediction. In The Twelfth International Conference on Learning Representations , 2023
work page 2023
-
[11]
Playing with transformer at 30+ fps via next-frame diffusion.arXiv preprint arXiv:2506.01380, 2025
Xinle Cheng, Tianyu He, Jiayi Xu, Junliang Guo, Di He, and Jiang Bian. Playing with transformer at 30+ fps via next-frame diffusion. arXiv preprint arXiv:2506.01380, 2025
- [12]
-
[13]
Junliang Guo, Yang Ye, Tianyu He, Haoyu Wu, Yushu Jiang, Tim Pearce, and Jiang Bian. Mineworld: a real-time and open-source interactive world model on minecraft. arXiv preprint arXiv:2504.08388, 2025
-
[14]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, Poriya Panet, Sapir Weissbuch, Victor Kulikov, Yaki Bitterman, Zeev Melumian, and Ofir Bibi. Ltx-video: Realtime video latent diffusion. arXiv preprint arXiv:2501.00103, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
CameraCtrl: Enabling Camera Control for Text-to-Video Generation
Hao He, Yinghao Xu, Yuwei Guo, Gordon Wetzstein, Bo Dai, Hongsheng Li, and Ceyuan Yang. Cameractrl: Enabling camera control for text-to-video generation. arXiv preprint arXiv:2404.02101, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems, volume 33, pages 6840–6851, 2020
work page 2020
-
[17]
GAIA-1: A Generative World Model for Autonomous Driving
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. Gaia-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion. arXiv preprint arXiv:2506.08009, 2025. 16
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Pyramidal flow matching for efficient video generative modeling.arXiv preprint arXiv:2410.05954,
Yang Jin, Zhicheng Sun, Ningyuan Li, Kun Xu, Hao Jiang, Nan Zhuang, Quzhe Huang, Yang Song, Yadong Mu, and Zhouchen Lin. Pyramidal flow matching for efficient video generative modeling. arXiv preprint arXiv:2410.05954, 2024
-
[20]
Auto-encoding variational bayes, 2013
Diederik P Kingma, Max Welling, et al. Auto-encoding variational bayes, 2013
work page 2013
-
[21]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Hunyuanvideo: A systematic framework for large video generative models, 2025
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, Kathrina Wu, Qin Lin, Junkun Yuan, Yanxin Long, Aladdin Wang, Andong Wang, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Hongmei Wang, Jacob Song, Jiawang Bai, Jianbing Wu, Jinbao Xue, Joey Wang, Kai Wang, Mengyang Liu, Pengyu Li, Shuai Li, ...
work page 2025
-
[23]
Jiaqi Li, Junshu Tang, Zhiyong Xu, Longhuang Wu, Yuan Zhou, Shuai Shao, Tianbao Yu, Zhiguo Cao, and Qinglin Lu. Hunyuan-gamecraft: High-dynamic interactive game video generation with hybrid history condition. arXiv preprint arXiv:2506.17201, 2025
-
[24]
Sekai: A video dataset towards world exploration.arXiv preprint arXiv:2506.15675, 2025
Zhen Li, Chuanhao Li, Xiaofeng Mao, Shaoheng Lin, Ming Li, Shitian Zhao, Zhaopan Xu, Xinyue Li, Yukang Feng, Jianwen Sun, et al. Sekai: A video dataset towards world exploration. arXiv preprint arXiv:2506.15675, 2025
-
[25]
Open-Sora Plan: Open-Source Large Video Generation Model
Bin Lin, Yunyang Ge, Xinhua Cheng, Zongjian Li, Bin Zhu, Shaodong Wang, Xianyi He, Yang Ye, Shenghai Yuan, Liuhan Chen, et al. Open-sora plan: Open-source large video generation model. arXiv preprint arXiv:2412.00131, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Autoregressive adversarial post- training for real-time interactive video generation
Shanchuan Lin, Ceyuan Yang, Hao He, Jianwen Jiang, Yuxi Ren, Xin Xia, Yang Zhao, Xuefeng Xiao, and Lu Jiang. Autoregressive adversarial post-training for real-time interactive video generation. arXiv preprint arXiv:2506.09350, 2025
-
[27]
Yume: An interactive world generation model.arXiv preprint arXiv:2507.17744, 2025
Xiaofeng Mao, Shaoheng Lin, Zhen Li, Chuanhao Li, Wenshuo Peng, Tong He, Jiangmiao Pang, Mingmin Chi, Yu Qiao, and Kaipeng Zhang. Yume: An interactive world generation model. arXiv preprint arXiv:2507.17744, 2025
-
[28]
Sora: Video generation models as world simulators
OpenAI. Sora: Video generation models as world simulators. https://openai.com/index/ video-generation-models-as-world-simulators/ , 2024
work page 2024
-
[29]
Genie 2: A large-scale foundation world model
J Parker-Holder, P Ball, J Bruce, V Dasagi, K Holsheimer, C Kaplanis, A Moufarek, G Scully, J Shar, J Shi, et al. Genie 2: A large-scale foundation world model. URL: https://deepmind. google/discover/blog/genie- 2-a-large-scale-foundation-world-model, 2024
work page 2024
-
[30]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InInternational Conference on Computer Vision, pages 4195–4205, 2023
work page 2023
-
[31]
Long-context state-space video world models.ArXiv, abs/2505.20171, 2025
Ryan Po, Yotam Nitzan, Richard Zhang, Berlin Chen, Tri Dao, Eli Shechtman, Gordon Wetzstein, and Xun Huang. Long-context state-space video world models. arXiv preprint arXiv:2505.20171, 2025
-
[32]
Haonan Qiu, Menghan Xia, Yong Zhang, Yingqing He, Xintao Wang, Ying Shan, and Ziwei Liu. Freenoise: Tuning-free longer video diffusion via noise rescheduling. arXiv preprint arXiv:2310.15169, 2023
-
[33]
Learning transferable visual models from natural language supervision, 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021
work page 2021
-
[34]
Gen3c: 3d-informed world-consistent video generation with precise camera control
Xuanchi Ren, Tianchang Shen, Jiahui Huang, Huan Ling, Yifan Lu, Merlin Nimier-David, Thomas Müller, Alexander Keller, Sanja Fidler, and Jun Gao. Gen3c: 3d-informed world-consistent video generation with precise camera control. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
work page 2025
-
[35]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In International Conference on Machine Learning , pages 2256–2265. PMLR, 2015
work page 2015
-
[37]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. 2023
work page 2023
-
[38]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021. 17
work page 2021
-
[39]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Jianlin Su, Yu Lu, Shengfeng Pan, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding. CoRR, abs/2104.09864, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[40]
MAGI-1: Autoregressive Video Generation at Scale
Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, WQ Zhang, Weifeng Luo, et al. Magi-1: Autoregressive video generation at scale. arXiv preprint arXiv:2505.13211, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Linrui Tian, Qi Wang, Bang Zhang, and Liefeng Bo. Emo: Emote portrait alive generating expressive portrait videos with audio2video diffusion model under weak conditions. In European Conference on Computer Vision, pages 244–260. Springer, 2024
work page 2024
-
[42]
Diffusion Models Are Real-Time Game Engines
Dani Valevski, Yaniv Leviathan, Moab Arar, and Shlomi Fruchter. Diffusion models are real-time game engines. arXiv preprint arXiv:2408.14837, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Wan: Open and advanced large-scale video generative models, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
work page 2025
-
[44]
Wan: Open and Advanced Large-Scale Video Generative Models
Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, et al. Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Motionctrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A unified and flexible motion controller for video generation. In ACM SIGGRAPH, pages 1–11, 2024
work page 2024
- [46]
-
[47]
Learning Interactive Real-World Simulators
Mengjiao Yang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Dale Schuurmans, and Pieter Abbeel. Learning interactive real-world simulators. arXiv preprint arXiv:2310.06114, 1(2):6, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Learning interactive real-world simulators
Sherry Yang, Yilun Du, Seyed Kamyar Seyed Ghasemipour, Jonathan Tompson, Leslie Pack Kaelbling, Dale Schuurmans, and Pieter Abbeel. Learning interactive real-world simulators. In International Conference on Learning Representations, 2024
work page 2024
-
[49]
Direct-a-video: Customized video generation with user-directed camera movement and object motion
Shiyuan Yang, Liang Hou, Haibin Huang, Chongyang Ma, Pengfei Wan, Di Zhang, Xiaodong Chen, and Jing Liao. Direct-a-video: Customized video generation with user-directed camera movement and object motion. In ACM SIGGRAPH, pages 1–12, 2024
work page 2024
-
[50]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[51]
Shengming Yin, Chenfei Wu, Huan Yang, Jianfeng Wang, Xiaodong Wang, Minheng Ni, Zhengyuan Yang, Linjie Li, Shuguang Liu, Fan Yang, et al. Nuwa-xl: Diffusion over diffusion for extremely long video generation. arXiv preprint arXiv:2303.12346, 2023
-
[52]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 6613–6623, 2024
work page 2024
-
[53]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 22963–22974, 2025
work page 2025
-
[54]
Gamefactory: Creating new games with generative interactive videos
Jiwen Yu, Yiran Qin, Xintao Wang, Pengfei Wan, Di Zhang, and Xihui Liu. Gamefactory: Creating new games with generative interactive videos. In International Conference on Computer Vision, 2025
work page 2025
-
[55]
Language model beats diffusion–tokenizer is key to visual generation
Lijun Yu, José Lezama, Nitesh B Gundavarapu, Luca Versari, Kihyuk Sohn, David Minnen, Yong Cheng, Vighnesh Birodkar, Agrim Gupta, Xiuye Gu, et al. Language model beats diffusion–tokenizer is key to visual generation. In International Conference on Learning Representations , 2024
work page 2024
-
[56]
Hipa: enabling one-step text-to-image diffusion models via high-frequency- promoting adaptation
Yifan Zhang and Bryan Hooi. Hipa: enabling one-step text-to-image diffusion models via high-frequency- promoting adaptation. arXiv preprint arXiv:2311.18158, 2023
-
[57]
Matrix-game: Interactive world foundation model, 2025
Yifan Zhang, Chunli Peng, Boyang Wang, Puyi Wang, Qingcheng Zhu, Fei Kang, Biao Jiang, Zedong Gao, Eric Li, Yang Liu, and Yahui Zhou. Matrix-game: Interactive world foundation model. arXiv preprint arXiv:2506.18701, 2025. 18
-
[58]
Expanding small-scale datasets with guided imagination
Yifan Zhang, Daquan Zhou, Bryan Hooi, Kai Wang, and Jiashi Feng. Expanding small-scale datasets with guided imagination. In Advances in Neural Information Processing Systems , volume 36, pages 76558–76618, 2023
work page 2023
-
[59]
Yupeng Zhou, Daquan Zhou, Ming-Ming Cheng, Jiashi Feng, and Qibin Hou
Canyu Zhao, Mingyu Liu, Wen Wang, Weihua Chen, Fan Wang, Hao Chen, Bo Zhang, and Chun- hua Shen. Moviedreamer: Hierarchical generation for coherent long visual sequence. arXiv preprint arXiv:2407.16655, 2024
-
[60]
Memo: Memory-guided diffusion for expressive talking video generation
Longtao Zheng, Yifan Zhang, Hanzhong Guo, Jiachun Pan, Zhenxiong Tan, Jiahao Lu, Chuanxin Tang, Bo An, and Shuicheng Yan. Memo: Memory-guided diffusion for expressive talking video generation. arXiv preprint arXiv:2412.04448, 2024. 19
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.