EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle
Pith reviewed 2026-05-21 20:46 UTC · model grok-4.3
The pith
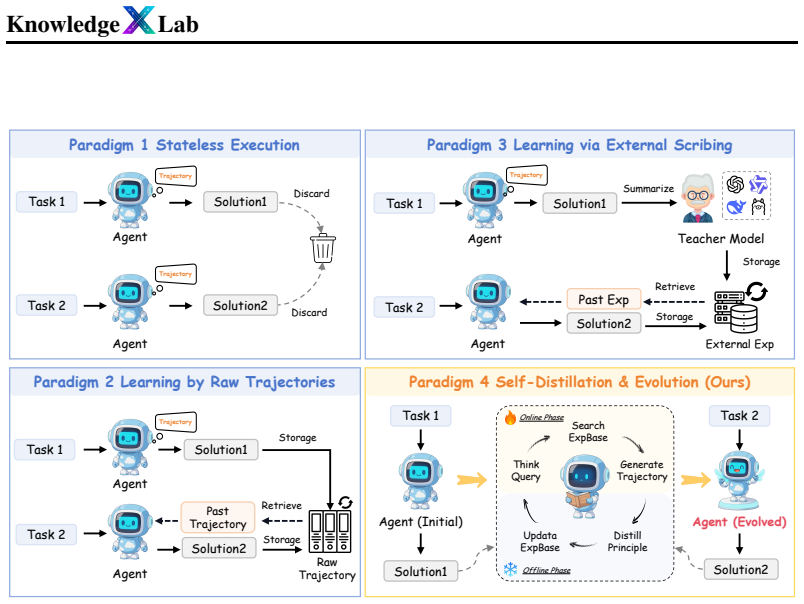
LLM agents self-evolve by distilling their own interaction trajectories into reusable strategic principles that guide later decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EvolveR creates a complete experience-driven lifecycle in which offline self-distillation converts interaction trajectories into a structured repository of abstract, reusable strategic principles; online interaction then retrieves those principles to direct decision-making while accumulating new behavioral trajectories; and a policy reinforcement mechanism iteratively updates the agent from its own performance outcomes.
What carries the argument
The two-stage closed-loop lifecycle of offline self-distillation to build a principle repository and online retrieval with trajectory accumulation plus policy reinforcement.
Load-bearing premise
That interaction trajectories can be reliably turned into abstract principles which, when retrieved, produce measurably better decisions on new tasks.
What would settle it
A direct comparison on the same multi-hop QA benchmarks showing that agents equipped with the retrieved principles achieve no gain or lower accuracy than identical agents without retrieval would falsify the central improvement claim.
Figures




read the original abstract
Current Large Language Model (LLM) agents show strong performance in tool use, but lack the crucial capability to systematically learn from their own experiences. While existing frameworks mainly focus on mitigating external knowledge gaps, they fail to address a more fundamental limitation: the inability to iteratively refine problem-solving strategies. In this work, we introduce EvolveR, a framework designed to enable agent to self-improve through a complete, closed-loop experience lifecycle. This lifecycle comprises two key stages: (1) Offline Self-Distillation, where the agent's interaction trajectories are synthesized into a structured repository of abstract, reusable strategic principles; (2) Online Interaction, where the agent interacts with tasks and actively retrieves distilled principles to guide its decision-making, accumulating a diverse set of behavioral trajectories. This loop employs a policy reinforcement mechanism to iteratively update the agent based on its performance. We demonstrate the effectiveness of EvolveR on complex multi-hop question-answering benchmarks, where it achieves superior performance over strong agentic baselines. Our work presents a comprehensive blueprint for agents that learn not only from external data but also from the consequences of their own actions, paving the way for more autonomous and continuously improving systems. Code is available at https://github.com/Edaizi/EvolveR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EvolveR, a framework for LLM agents to self-improve via a closed-loop experience lifecycle. This consists of (1) an offline self-distillation stage that synthesizes interaction trajectories into a structured repository of abstract, reusable strategic principles and (2) an online interaction stage in which the agent retrieves these principles to guide decisions while accumulating new trajectories, closed by a policy reinforcement update mechanism. The central claim is that this yields superior performance on complex multi-hop question-answering benchmarks relative to strong agentic baselines.
Significance. If the empirical results hold and the distilled principles prove abstract and transferable, the work would supply a concrete blueprint for agents that improve from the consequences of their own actions rather than external data alone. The public code release is a clear strength that aids reproducibility.
major comments (2)
- [§3.1] §3.1 (Offline Self-Distillation): the synthesis step is described at a high level as producing 'abstract, reusable strategic principles,' yet no concrete examples, similarity metrics, or transfer tests are supplied to show that the output is genuinely abstract rather than surface-level rephrasings of the input trajectories. This distinction is load-bearing for the claim that retrieval improves decision-making beyond standard RAG.
- [§4] §4 (Experiments): the reported superiority on multi-hop QA benchmarks is not accompanied by ablations that isolate the contribution of the distilled-principles repository versus raw-trajectory retrieval or the reinforcement update alone. Without such controls, it is impossible to attribute gains to the self-evolution mechanism rather than additional context.
minor comments (2)
- [Abstract] Abstract: the phrase 'agent to self-improve' contains a grammatical inconsistency (singular/plural).
- [Figure 1] Figure 1 (lifecycle diagram): the arrow from online accumulation back to offline distillation is not labeled with the reinforcement update, making the closed-loop flow harder to follow.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We provide point-by-point responses to the major comments and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Offline Self-Distillation): the synthesis step is described at a high level as producing 'abstract, reusable strategic principles,' yet no concrete examples, similarity metrics, or transfer tests are supplied to show that the output is genuinely abstract rather than surface-level rephrasings of the input trajectories. This distinction is load-bearing for the claim that retrieval improves decision-making beyond standard RAG.
Authors: We agree that the current description would benefit from more concrete illustrations to substantiate the abstraction claim. In the revised manuscript, we will add specific examples of trajectories and the distilled principles, specify the similarity metrics used (semantic similarity via embeddings), and include a transferability analysis showing generalization to unseen tasks. This will address the concern about distinguishing from surface-level rephrasings and support the advantage over standard RAG. revision: yes
-
Referee: [§4] §4 (Experiments): the reported superiority on multi-hop QA benchmarks is not accompanied by ablations that isolate the contribution of the distilled-principles repository versus raw-trajectory retrieval or the reinforcement update alone. Without such controls, it is impossible to attribute gains to the self-evolution mechanism rather than additional context.
Authors: We concur that additional ablations would strengthen the attribution of results to the self-evolution components. Although the main results compare against baselines without the full lifecycle, we will include new ablation experiments in the revised Section 4: one replacing the distilled principles with raw trajectories, and another removing the policy reinforcement step. These controls will help isolate the contributions of each element in the closed-loop mechanism. revision: yes
Circularity Check
No circularity: empirical framework with no derivations or fitted predictions
full rationale
The paper describes an agent framework consisting of an offline self-distillation stage that synthesizes trajectories into principles and an online stage that retrieves them for decision-making, followed by a policy reinforcement loop. Superior performance is asserted solely as an empirical outcome on multi-hop QA benchmarks. No equations, first-principles derivations, parameter fits, or predictions appear that could reduce by construction to the same inputs. The central claims rest on experimental results rather than analytical self-reference, rendering the reported chain self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM interaction trajectories contain extractable abstract strategic principles that transfer to new tasks
Forward citations
Cited by 36 Pith papers
-
Library Drift: Diagnosing and Fixing a Silent Failure Mode in Self-Evolving LLM Skill Libraries
Identifies library drift as a failure mode in self-evolving LLM skill libraries and shows a governance recipe improves pass@1 from 0.258 to 0.584 on MBPP+ hard-100.
-
EXG: Self-Evolving Agents with Experience Graphs
EXG is an experience graph framework for self-evolving LLM agents that supports online real-time growth and offline reuse to enhance solution quality and efficiency on code generation and reasoning benchmarks.
-
Test-Time Learning with an Evolving Library
EvoLib enables LLMs to accumulate, reuse, and evolve knowledge abstractions from inference trajectories at test time, yielding substantial gains on math reasoning, code generation, and agentic benchmarks without param...
-
ClawForge: Generating Executable Interactive Benchmarks for Command-Line Agents
ClawForge is a generator framework that creates reproducible executable benchmarks for command-line agents under state conflict, with ClawForge-Bench showing frontier models reach at most 45.3% strict accuracy and tha...
-
ClawForge: Generating Executable Interactive Benchmarks for Command-Line Agents
ClawForge supplies a generator that turns scenario templates into reproducible command-line tasks testing state conflict handling, where the strongest frontier model scores only 45.3 percent strict accuracy.
-
EvolveMem:Self-Evolving Memory Architecture via AutoResearch for LLM Agents
EvolveMem enables autonomous self-evolution of LLM memory retrieval configurations via LLM diagnosis and safeguards, delivering 25.7% gains over strong baselines on LoCoMo and 18.9% on MemBench with positive cross-ben...
-
Evolving-RL: End-to-End Optimization of Experience-Driven Self-Evolving Capability within Agents
Evolving-RL jointly optimizes experience extraction and utilization in LLM agents via RL with separate evaluation signals, delivering up to 98.7% relative gains on out-of-distribution tasks in ALFWorld and Mind2Web.
-
MAGE: Multi-Agent Self-Evolution with Co-Evolutionary Knowledge Graphs
MAGE uses a four-subgraph co-evolutionary knowledge graph plus dual bandits to externalize and retrieve experience for stable self-evolution of frozen language-model agents, showing gains on nine diverse benchmarks.
-
RewardHarness: Self-Evolving Agentic Post-Training
RewardHarness self-evolves a tool-and-skill library from 100 preference examples to reach 47.4% accuracy on image-edit evaluation, beating GPT-5, and yields stronger RL-tuned models.
-
Generate, Filter, Control, Replay: A Comprehensive Survey of Rollout Strategies for LLM Reinforcement Learning
This survey introduces the Generate-Filter-Control-Replay (GFCR) taxonomy to structure rollout pipelines for RL-based post-training of reasoning LLMs.
-
SPIRAL: Self-Evolving Action-Conditioned Video Generation via Reflective Planning Agents
SPIRAL is a closed-loop think-act-reflect framework using PlanAgent, VideoGenerator, and CriticAgent plus GRPO self-evolution to improve long-horizon action-conditioned video generation, with new dataset and benchmark...
-
From Raw Experience to Skill Consumption: A Systematic Study of Model-Generated Agent Skills
A systematic study across five domains finds model-generated skills yield average gains but non-uniform negative transfer, with a meta-skill improving extraction quality.
-
Ratchet: A Minimal Hygiene Recipe for Self-Evolving LLM Agents
Ratchet provides a minimal hygiene recipe for self-managing skill libraries in frozen LLM agents, delivering +0.328 rolling-mean pass@1 gain on MBPP+ hard-100 and +0.22 peak lift on SWE-bench Verified.
-
Mem-$\pi$: Adaptive Memory through Learning When and What to Generate
Mem-π is a framework using a dedicated model and decision-content decoupled RL to generate context-specific guidance on demand for LLM agents, outperforming retrieval baselines by over 30% on web navigation.
-
AutoResearchClaw: Self-Reinforcing Autonomous Research with Human-AI Collaboration
AutoResearchClaw presents a multi-agent autonomous research pipeline with debate, self-healing execution, verifiable reporting, human-in-the-loop modes, and cross-run evolution that outperforms AI Scientist v2 by 54.7...
-
OEP: Poisoning Self-Evolving LLM Agents via Locally Correct but Non-Transferable Experiences
OEP poisons self-evolving LLM agents by constructing clean edge-case experiences that appear locally valid yet cause harmful over-generalization during reflection, achieving over 50% attack success rate on GPT-4o agen...
-
Is One Score Enough? Rethinking the Evaluation of Sequentially Evolving LLM Memory
SeqMem-Eval reveals that high final accuracy in sequential LLM memory tasks often coexists with substantial forgetting and negative transfer, exposing stability-adaptability trade-offs hidden by standard aggregate metrics.
-
SkillGraph: Skill-Augmented Reinforcement Learning for Agents via Evolving Skill Graphs
SkillGraph represents skills as nodes in an evolving directed graph with typed dependency edges and updates the graph from RL trajectories to boost compositional task performance.
-
Dynamic Skill Lifecycle Management for Agentic Reinforcement Learning
SLIM dynamically optimizes active external skills in agentic RL via leave-one-skill-out marginal contribution estimates and three lifecycle operations, outperforming baselines by 7.1% on ALFWorld and SearchQA while sh...
-
SkillMaster: Toward Autonomous Skill Mastery in LLM Agents
SkillMaster enables LLM agents to autonomously develop skills via trajectory review, counterfactual evaluation, and DualAdv-GRPO training, boosting success rates by 8.8% on ALFWorld and 9.3% on WebShop.
-
SkillMaster: Toward Autonomous Skill Mastery in LLM Agents
SkillMaster is a training framework that lets LLM agents autonomously propose, update, and apply skills, yielding 8.8% and 9.3% higher success rates on ALFWorld and WebShop than prior methods.
-
Learning Agent Routing From Early Experience
BoundaryRouter routes queries to LLM or agent using early experience memory from a seed set, cutting inference time 60.6% versus always using agents and raising performance 28.6% versus always using direct LLM inference.
-
Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning
Skill1 trains one policy to jointly evolve skill query generation, re-ranking, task solving, and distillation from a single task-success signal, with low-frequency trends crediting selection and high-frequency variati...
-
GenericAgent: A Token-Efficient Self-Evolving LLM Agent via Contextual Information Density Maximization (V1.0)
GenericAgent outperforms other LLM agents on long-horizon tasks by maximizing context information density with fewer tokens via minimal tools, on-demand memory, trajectory-to-SOP evolution, and compression.
-
Experience Compression Spectrum: Unifying Memory, Skills, and Rules in LLM Agents
The Experience Compression Spectrum unifies memory, skills, and rules in LLM agents along increasing compression levels and identifies the absence of adaptive cross-level compression as the missing diagonal.
-
Skill-SD: Skill-Conditioned Self-Distillation for Multi-turn LLM Agents
Skill-SD turns an agent's completed trajectories into dynamic natural-language skills that condition only the teacher in self-distillation, yielding 14-42% gains over RL and OPSD baselines on multi-turn agent benchmarks.
-
Agentic Learner with Grow-and-Refine Multimodal Semantic Memory
ViLoMem is a dual-stream grow-and-refine memory system that separates visual and logical error patterns in MLLMs to improve pass@1 accuracy and reduce repeated mistakes across six multimodal benchmarks.
-
SkillOpt: Executive Strategy for Self-Evolving Agent Skills
SkillOpt introduces a validation-gated text-space optimizer for agent skills that outperforms human, one-shot, and prior optimization baselines across 52 model-benchmark-harness combinations.
-
Robo-Cortex: A Self-Evolving Embodied Agent via Dual-Grain Cognitive Memory and Autonomous Knowledge Induction
Robo-Cortex proposes a self-evolving embodied navigation agent using dual-grain cognitive memory and autonomous knowledge induction from trajectories, reporting SPL gains on IGNav, AR, AEQA and preliminary real-robot tests.
-
Dynamic Skill Lifecycle Management for Agentic Reinforcement Learning
SLIM dynamically optimizes the active external skill set in agentic RL via leave-one-skill-out marginal contribution estimates and lifecycle operations, delivering a 7.1% average gain over baselines on ALFWorld and Se...
-
Learning CLI Agents with Structured Action Credit under Selective Observation
CLI agents trained with RL benefit from selective observation via σ-Reveal and structured credit assignment via A³ that leverages AST action sub-chains and trajectory margins.
-
A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications
A survey that taxonomizes agent skills for LLM-based agents across representation, acquisition, retrieval, and evolution stages while reviewing methods, resources, and open challenges.
-
Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning
Skill1 trains a single RL policy to co-evolve skill selection, utilization, and distillation in language model agents from one task-outcome reward, using low-frequency trends to credit selection and high-frequency var...
-
Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning
Skill1 co-evolves skill selection, utilization, and distillation inside a single policy using only task-outcome reward, with low-frequency trends crediting selection and high-frequency variation crediting distillation...
-
Web2BigTable: A Bi-Level Multi-Agent LLM System for Internet-Scale Information Search and Extraction
Web2BigTable introduces a bi-level multi-agent system that achieves new state-of-the-art results on wide-coverage and deep web-to-table search benchmarks through orchestration, coordination, and closed-loop reflection.
-
A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications
The paper surveys agent skills for LLM agents, organizing the literature into a four-stage lifecycle of representation, acquisition, retrieval, and evolution while highlighting their role in system scalability.
Reference graph
Works this paper leans on
-
[1]
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face.Advances in Neural Information Processing Systems, 36:38154–38180, 2023
work page 2023
-
[2]
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
Junyu Luo, Weizhi Zhang, Ye Yuan, Yusheng Zhao, Junwei Yang, Yiyang Gu, Bohan Wu, Binqi Chen, Ziyue Qiao, Qingqing Long, Rongcheng Tu, Xiao Luo, Wei Ju, Zhiping Xiao, Yifan Wang, Meng Xiao, Chenwu Liu, Jingyang Yuan, Shichang Zhang, Yiqiao Jin, Fan Zhang, Xian Wu, Hanqing Zhao, Dacheng Tao, Philip S. Yu, and Ming Zhang. Large lan- guage model agent: A sur...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Huan ang Gao, Jiayi Geng, Wenyue Hua, Mengkang Hu, Xinzhe Juan, Hongzhang Liu, Shi- long Liu, Jiahao Qiu, Xuan Qi, Yiran Wu, Hongru Wang, Han Xiao, Yuhang Zhou, Shaokun Zhang, Jiayi Zhang, Jinyu Xiang, Yixiong Fang, Qiwen Zhao, Dongrui Liu, Qihan Ren, Cheng Qian, Zhenhailong Wang, Minda Hu, Huazheng Wang, Qingyun Wu, Heng Ji, and Mengdi Wang. A survey of ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models, 2023. URLhttps: //arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Timo Flesch, Jan Balaguer, Ronald Dekker, Hamed Nili, and Christopher Summerfield. Com- paring continual task learning in minds and machines.Proceedings of the National Academy of Sciences, 115(44):E10313–E10322, 2018
work page 2018
-
[6]
Problem solving and learning.American psychologist, 48(1):35, 1993
John R Anderson. Problem solving and learning.American psychologist, 48(1):35, 1993
work page 1993
-
[7]
Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Hinrich Sch ¨utze, V olker Tresp, and Yunpu Ma. Memory-r1: Enhancing large language model agents to manage and utilize memories via reinforcement learning.arXiv preprint arXiv:2508.19828, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Ex- pel: Llm agents are experiential learners, 2024
Andrew Zhao, Daniel Huang, Quentin Xu, Matthieu Lin, Yong-Jin Liu, and Gao Huang. Ex- pel: Llm agents are experiential learners, 2024. URLhttps://arxiv.org/abs/2308. 10144
work page 2024
-
[9]
Memento: Fine-tuning LLM Agents without Fine-tuning LLMs
Huichi Zhou, Yihang Chen, Siyuan Guo, Xue Yan, Kin Hei Lee, Zihan Wang, Ka Yiu Lee, Guchun Zhang, Kun Shao, Linyi Yang, and Jun Wang. Memento: Fine-tuning llm agents without fine-tuning llms, 2025. URLhttps://arxiv.org/abs/2508.16153
-
[10]
Liting Chen, Lu Wang, Hang Dong, Yali Du, Jie Yan, Fangkai Yang, Shuang Li, Pu Zhao, Si Qin, Saravan Rajmohan, et al. Introspective tips: Large language model for in-context decision making.arXiv preprint arXiv:2305.11598, 2023
-
[11]
Con- tinual lifelong learning with neural networks: A review.Neural networks, 113:54–71, 2019
German I Parisi, Ronald Kemker, Jose L Part, Christopher Kanan, and Stefan Wermter. Con- tinual lifelong learning with neural networks: A review.Neural networks, 113:54–71, 2019
work page 2019
-
[12]
A comprehensive survey of continual learning: Theory, method and application,
Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of contin- ual learning: Theory, method and application, 2024. URLhttps://arxiv.org/abs/ 2302.00487
-
[13]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catas- trophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13):352...
-
[14]
Boosting large language models with continual learning for aspect-based sentiment analysis,
Xuanwen Ding, Jie Zhou, Liang Dou, Qin Chen, Yuanbin Wu, Chengcai Chen, and Liang He. Boosting large language models with continual learning for aspect-based sentiment analysis,
- [15]
-
[16]
Task-core memory management and consolidation for long-term continual learning, 2025
Tianyu Huai, Jie Zhou, Yuxuan Cai, Qin Chen, Wen Wu, Xingjiao Wu, Xipeng Qiu, and Liang He. Task-core memory management and consolidation for long-term continual learning, 2025. URLhttps://arxiv.org/abs/2505.09952
-
[17]
Tianyu Huai, Jie Zhou, Xingjiao Wu, Qin Chen, Qingchun Bai, Ze Zhou, and Liang He. Cl- moe: Enhancing multimodal large language model with dual momentum mixture-of-experts for continual visual question answering, 2025. URLhttps://arxiv.org/abs/2503. 00413
work page 2025
-
[18]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning, 2023. URL https://arxiv.org/abs/2303.11366
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[19]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[20]
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models.Ad- vances in neural information processing systems, 36:11809–11822, 2023
work page 2023
-
[21]
Graph of thoughts: Solving elaborate problems with large language models
Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gi- aninazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. Graph of thoughts: Solving elaborate problems with large language models. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 17682–17690, 2024
work page 2024
-
[22]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Za- mani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning, 2025. URLhttps://arxiv.org/abs/2503.09516
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
O 2- searcher: A searching-based agent model for open-domain open-ended question answering,
Jianbiao Mei, Tao Hu, Daocheng Fu, Licheng Wen, Xuemeng Yang, Rong Wu, Pinlong Cai, Xinyu Cai, Xing Gao, Yu Yang, Chengjun Xie, Botian Shi, Yong Liu, and Yu Qiao. O 2- searcher: A searching-based agent model for open-domain open-ended question answering,
- [24]
-
[25]
Search and refine during think: Autonomous retrieval-augmented reasoning of llms, 2025
Yaorui Shi, Sihang Li, Chang Wu, Zhiyuan Liu, Junfeng Fang, Hengxing Cai, An Zhang, and Xiang Wang. Search and refine during think: Autonomous retrieval-augmented reasoning of llms, 2025. URLhttps://arxiv.org/abs/2505.11277
-
[26]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory, 2025. URLhttps: //arxiv.org/abs/2504.19413
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
G- memory: Tracing hierarchical memory for multi-agent systems, 2025
Guibin Zhang, Muxin Fu, Guancheng Wan, Miao Yu, Kun Wang, and Shuicheng Yan. G-memory: Tracing hierarchical memory for multi-agent systems, 2025. URLhttps: //arxiv.org/abs/2506.07398
-
[28]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of math- ematical reasoning in open language models, 2024. URLhttps://arxiv.org/abs/ 2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. Natural questions: a benchmark for question answering research.Transactions of the Association for Computational Linguistics, 7:453–466, 2019
work page 2019
-
[30]
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W Cohen, Ruslan Salakhut- dinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering.arXiv preprint arXiv:1809.09600, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension.arXiv preprint arXiv:1705.03551, 2017. 12 Knowledge Lab
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[32]
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Ha- jishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories.arXiv preprint arXiv:2212.10511, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps
Xanh Ho, Anh-Khoa Duong Nguyen, Saku Sugawara, and Akiko Aizawa. Constructing a multi-hop qa dataset for comprehensive evaluation of reasoning steps.arXiv preprint arXiv:2011.01060, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[34]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
work page 2022
-
[35]
Measuring and Narrowing the Compositionality Gap in Language Models
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A Smith, and Mike Lewis. Measuring and narrowing the compositionality gap in language models.arXiv preprint arXiv:2210.03350, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Na- man Goyal, Heinrich K ¨uttler, Mike Lewis, Wen-tau Yih, Tim Rockt ¨aschel, et al. Retrieval- augmented generation for knowledge-intensive nlp tasks.Advances in neural information pro- cessing systems, 33:9459–9474, 2020
work page 2020
-
[37]
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions.arXiv preprint arXiv:2212.10509, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[38]
Search-o1: Agentic Search-Enhanced Large Reasoning Models
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. Search-o1: Agentic search-enhanced large reasoning models.arXiv preprint arXiv:2501.05366, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models.Journal of Machine Learning Research, 25(70):1–53, 2024
work page 2024
-
[40]
Large language models for mathematical reasoning: Progresses and challenges
Janice Ahn, Rishu Verma, Renze Lou, Di Liu, Rui Zhang, and Wenpeng Yin. Large language models for mathematical reasoning: Progresses and challenges.arXiv preprint arXiv:2402.00157, 2024
-
[41]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Knowledge-Centric Hallucination Detection
Yaowei Zheng, Richong Zhang, Junhao Zhang, YeYanhan YeYanhan, and Zheyan Luo. Lla- maFactory: Unified efficient fine-tuning of 100+ language models. In Yixin Cao, Yang Feng, and Deyi Xiong, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pages 400–410, Bangkok, Thailand, Au...
-
[43]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. Bge m3- embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self- knowledge distillation.arXiv preprint arXiv:2402.03216, 2024. 13 Knowledge Lab A APPENDIX A.1 EXPERIMENTALIMPLEMENTATIONDETAILS We provide a comprehensive list of hyperparameters...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
A concise, one-sentence natural language description. This is the core advice
-
[46]
A structured representation of the key steps or logic, as a list of simple (subject, predicate, object) triplets. [Trajectory Log]: {{trajectory log}} Final Outcome: SUCCESS Your Task: Based on the trajectory, generate the Guiding Principle. First, on a new line, write{DESCRIPTION PART SEPARATOR}. Then, write the one-sentence description of the pitfall. T...
-
[47]
A concise, one-sentence description of the key mistake to avoid and under what circumstances
-
[48]
A structured representation of the failure pattern, as a list of simple (subject, predicate, object) triplets. [Trajectory Log]: {{trajectory log}} Final Outcome: FAILURE Your Task: Based on the trajectory, generate the Cautionary Principle. First, on a new line, write{DESCRIPTION PART SEPARATOR}. Then, write the one-sentence description of the pitfall. T...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.