An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Pith reviewed 2026-05-24 14:20 UTC · model grok-4.3
The pith
A pure transformer applied directly to sequences of image patches performs very well on image classification tasks after large-scale pre-training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
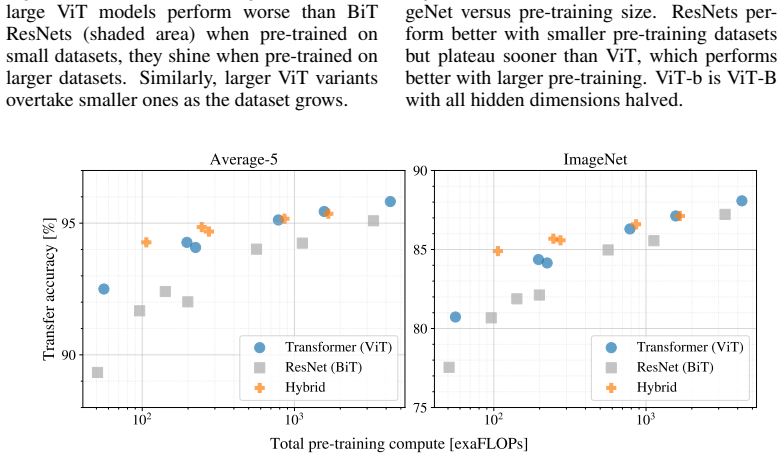
The Vision Transformer processes an image by dividing it into a grid of 16x16 patches, linearly projecting each patch into an embedding, adding learnable position embeddings, and passing the resulting sequence through a standard transformer encoder. After pre-training on large datasets the model is fine-tuned on target tasks and attains excellent accuracy on ImageNet, CIFAR-100, VTAB and similar benchmarks while requiring substantially fewer computational resources than state-of-the-art convolutional networks.
What carries the argument
Vision Transformer (ViT): a standard transformer encoder applied to a sequence of linearly embedded image patches rather than to convolutional feature maps.
If this is right
- ViT reaches or exceeds the accuracy of leading convolutional networks on ImageNet, CIFAR-100 and VTAB after the same pre-training.
- The model trains with substantially lower computational cost than state-of-the-art CNNs while achieving comparable or better transfer performance.
- Convolutional inductive biases are shown to be unnecessary once pre-training scale is large enough.
- The same patch-sequence architecture transfers successfully to multiple mid-sized and small recognition benchmarks.
Where Pith is reading between the lines
- The same patch-to-sequence reduction could be tested on dense prediction tasks such as segmentation or detection to check whether the performance pattern holds beyond classification.
- If the scaling behavior observed in language models also appears here, further increases in data and model size would be expected to widen the efficiency advantage over CNNs.
- Alternative patch sizes or hierarchical token merging could be explored to reduce the quadratic cost of self-attention on high-resolution inputs.
Load-bearing premise
Large amounts of pre-training data and model capacity can fully compensate for the absence of convolutional inductive biases such as locality and translation equivariance.
What would settle it
A controlled experiment in which a Vision Transformer, trained and transferred under the same large-scale regime, consistently underperforms matched convolutional networks across the reported mid-sized and small image-classification benchmarks.
Figures











read the original abstract
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to replace certain components of convolutional networks while keeping their overall structure in place. We show that this reliance on CNNs is not necessary and a pure transformer applied directly to sequences of image patches can perform very well on image classification tasks. When pre-trained on large amounts of data and transferred to multiple mid-sized or small image recognition benchmarks (ImageNet, CIFAR-100, VTAB, etc.), Vision Transformer (ViT) attains excellent results compared to state-of-the-art convolutional networks while requiring substantially fewer computational resources to train.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Vision Transformer (ViT), a pure transformer model that tokenizes images into fixed-size patches (typically 16x16), linearly embeds them, and processes the sequence with standard transformer layers. When pre-trained on large-scale datasets such as JFT-300M and fine-tuned on ImageNet, CIFAR-100, VTAB and other benchmarks, ViT variants (Base, Large, Huge) match or exceed the accuracy of state-of-the-art CNNs while using substantially less training compute.
Significance. If the reported transfer results hold, the work is significant because it provides direct empirical evidence that convolutional inductive biases are not required for competitive image classification once sufficient pre-training data and model capacity are available. The systematic scaling experiments across model sizes and the comparison against BiT/ResNet baselines on public benchmarks constitute a clear falsifiable demonstration that patch-based tokenization plus self-attention can substitute for CNNs at scale.
minor comments (3)
- [§3.1] §3.1: the linear patch embedding is described only in prose; an explicit matrix equation showing the projection from flattened patch to D-dimensional token would improve reproducibility.
- [Figure 3, Table 2] Figure 3 and Table 2: the pre-training compute axis is reported in TPUv3-days; adding a second panel or column with FLOPs per image would make the efficiency claim easier to compare across hardware.
- [§4.2] §4.2: the statement that ViT requires 'substantially fewer computational resources' is supported by the JFT-300M numbers but would be strengthened by an explicit wall-clock or energy comparison on the same hardware as the BiT baselines.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the Vision Transformer manuscript and the recommendation to accept.
Circularity Check
No circularity: empirical results on public benchmarks
full rationale
The paper's central claim is an empirical demonstration that a pure transformer on image patches, pre-trained at scale, matches CNN performance on standard classification tasks after transfer. This is validated directly via experiments (ViT variants pre-trained on JFT-300M, fine-tuned on ImageNet/CIFAR-100/VTAB) with ablations and baselines; no derivation chain, equations, or fitted parameters reduce to the evaluation data by construction. The premise that CNN inductive biases are unnecessary is tested rather than smuggled in via self-definition or self-citation. The work is self-contained against external benchmarks with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
free parameters (2)
- patch size
- model scale (base/large/huge)
axioms (1)
- standard math Self-attention and positional encoding as defined in the original Transformer paper
invented entities (1)
-
Linear patch embedding
no independent evidence
Forward citations
Cited by 60 Pith papers
-
DyABD: The Abdominal Muscle Segmentation in Dynamic MRI Benchmark
DyABD is the first benchmark dataset for abdominal muscle segmentation in dynamic MRIs featuring exercise-induced anatomical changes and pre/post-surgery scans, where existing models achieve an average Dice score of 0.82.
-
Exposing Functional Fusion: A New Class of Strategic Backdoor in Dynamic Prompt Architectures
VIPER exposes Functional Fusion in dynamic prompt architectures, enabling a backdoor that resists pruning by tightly integrating attack and utility parameters in the same high-magnitude core.
-
iMiGUE-3K: A Large-Scale Benchmark for Micro-Gesture Analysis with Self-Supervised Learning
iMiGUE-3K is the largest in-the-wild micro-gesture video dataset with 3.4K clips and 37M frames from real interviews, supporting self-supervised foundation models and benchmarks that show micro-gestures improve emotio...
-
Privacy Auditing with Zero (0) Training Run
Zero-Run auditing supplies valid lower bounds on differential privacy parameters from fixed member and non-member datasets by modeling and correcting distribution-shift confounding via causal-inference techniques.
-
CheXTemporal: A Dataset for Temporally-Grounded Reasoning in Chest Radiography
CheXTemporal supplies paired chest X-rays with explicit temporal progression taxonomy and spatial grounding to benchmark and improve models on longitudinal reasoning tasks.
-
Dissecting Jet-Tagger Through Mechanistic Interpretability
A Particle Transformer jet tagger contains a sparse six-head circuit whose source-relay-readout structure recovers most performance and whose residual stream preferentially encodes 2-prong energy correlators.
-
Gradient-Based Program Synthesis with Neurally Interpreted Languages
NLI autonomously discovers a vocabulary of primitive operations and interprets variable-length programs via a neural executor, allowing end-to-end training and gradient-based test-time adaptation that outperforms prio...
-
S1-MMAlign: A Large-Scale, Multi-Disciplinary Dataset for Scientific Figure-Text Understanding
S1-MMAlign is a new large-scale dataset of 15.5 million semantically enhanced scientific image-text pairs created via an AI recaptioning pipeline to improve multimodal understanding.
-
A document is worth a structured record: Principled inductive bias design for document recognition
Introduces a method to design structure-specific relational inductive biases for a base transformer architecture, enabling end-to-end transcription of documents with intrinsic structures, demonstrated on sheet music, ...
-
Promptbreeder: Self-Referential Self-Improvement Via Prompt Evolution
Promptbreeder evolves both task prompts and the mutation prompts that improve them using LLMs, outperforming Chain-of-Thought and Plan-and-Solve on arithmetic and commonsense reasoning benchmarks.
-
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion
Diffusion Policy models robot actions as a conditional diffusion process, outperforming prior state-of-the-art methods by 46.9% on average across 12 manipulation tasks from four benchmarks.
-
Efficiently Modeling Long Sequences with Structured State Spaces
S4 is an efficient state space sequence model that captures long-range dependencies via structured parameterization of the SSM, achieving state-of-the-art results on the Long Range Arena and other benchmarks while bei...
-
Decision Transformer: Reinforcement Learning via Sequence Modeling
Decision Transformer casts RL as autoregressive sequence modeling conditioned on desired returns, past states and actions, matching or exceeding offline RL baselines on Atari, Gym and Key-to-Door tasks.
-
Emerging Properties in Self-Supervised Vision Transformers
Self-supervised ViTs show emergent semantic segmentation and 78.3% k-NN accuracy on ImageNet; DINO reaches 80.1% linear evaluation with ViT-Base.
-
Event-Illumination Collaborative Low-light Image Enhancement with a High-resolution Real-world Dataset
EIC-LIE uses an event-illumination collaborative module and illumination-aware event filter plus a new real-world dataset to improve low-light image enhancement over prior methods.
-
AIGaitor: Privacy-preserving and cloud-free motion analysis for everyone, using edge computing
The paper presents AIGaitor, a privacy-preserving on-device monocular motion analysis system that performs end-to-end pose estimation and deep learning gait analysis on consumer smartphones.
-
FTerViT: Fully Ternary Vision Transformer
FTerViT introduces fully ternary Vision Transformers with TernaryBitConv2d and TernaryLayerNorm operators, achieving 82.43% ImageNet top-1 at 6.09 MB with 15x compression.
-
VSCD: Video-based Scene Change Detection in Unaligned Scenes
VSCD presents a query-centric multi-reference model for pixel-wise change detection in unaligned, unsynchronized indoor videos, backed by a 1.1-million-frame benchmark and real-robot validation for surveillance and in...
-
ShapeBench: A Scalable Benchmark and Diagnostic Suite for Standardized Evaluation in Aerodynamic Shape Optimization
ShapeBench is a new unified benchmark for aerodynamic shape optimization that shows optimizer performance varies substantially across different shape classes and problem setups.
-
MAPS: A Synthetic Dataset for Probing Vision Models in a Controlled 3D Scene Space
MAPS provides 2618 validated 3D meshes and a controllable rendering pipeline to attribute vision model recognition failures to specific scene parameters, finding camera distance and elevation as the dominant failure f...
-
Trust It or Not: Evidential Uncertainty for Feed-Forward 3D Reconstruction with Trust3R
Trust3R introduces a gated residual refinement plus Normal-Inverse-Wishart evidential head that produces closed-form multivariate Student-t uncertainty for per-point geometry in feed-forward 3D reconstruction and impr...
-
Targeted Downstream-Agnostic Attack
Introduces Targeted Downstream-Agnostic Attack (TDAA) that uses a threat image as feature anchor and example-specific perturbations to achieve targeted attacks on unknown downstream tasks from pre-trained encoders.
-
Randomized Advantage Transformation (RAT): Computing Natural Policy Gradients via Direct Backpropagation
RAT reformulates regularized natural policy gradients as vanilla gradients with a transformed advantage, computed efficiently via randomized block Kaczmarz iterations on on-policy data.
-
CineMatte: Background Matting for Virtual Production and Beyond
CineMatte uses a cross-attention design on a Siamese DINOv3 ViT plus a pretrained upsampler to produce robust mattes for virtual production, backed by a new non-synthetic 4K VP dataset that supports camera motion.
-
Prediction of Challenging Behaviors Associated with Profound Autism in a Classroom Setting Using Wearable Sensors
Wearable accelerometry, EDA, and skin temperature data from 9 students with profound autism in real classrooms enables prediction of challenging behavior episodes up to 10 minutes in advance with AUC-ROC of 0.78 using...
-
GraphMAR: Geometry-Aware Graph Learning Framework for Spatially Adaptive CT Metal Artifact Reduction
GraphMAR introduces graph-based geometric modeling and a GraphMoE module to explicitly localize and spatially adaptively reduce metal artifacts in CT images using only image-domain inputs.
-
HEED: Density-Weighted Residual Alignment for Hybrid Vision-Language Model Distillation
HEED replaces uniform residual alignment with density-weighted alignment using patch self-dissimilarity to improve hybrid VLM distillation, gaining 8.7 points on OCRBench v2 and 5.13 on a 10-benchmark average.
-
SHED: Style-Homogenized Embedding Alignment for Domain Generalization
SHED improves domain generalization in CLIP by aligning style-homogenized embeddings instead of raw ones, achieving state-of-the-art results on five benchmarks including a 4% gain on DomainNet.
-
Observation-Aligned Mask Priors for Learning Physical Dynamics from Authentic Occlusions
A framework pretrained on authentic binary occlusion masks uses guided sampling and intersection-based partitioning to train diffusion models on incomplete physical observations without zero-query regions.
-
Characterizing Learning in Deep Neural Networks using Tractable Algorithmic Complexity Analysis
QuBD extends algorithmic complexity estimation to quantized DNN weights, revealing that complexity decreases during learning, increases with overfitting, follows grokking patterns, and correlates with generalization.
-
DIPA: Distilled Preconditioned Algorithms for Solving Imaging Inverse Problems
DIPA learns preconditioning operators via distillation from a teacher with a better sensing matrix to improve reconstruction quality for the student's physically constrained matrix in imaging inverse problems.
-
CoralLite: {\mu}CT Reconstruction of Coral Colonies from Individual Corallites
CoralLite dataset and V-Trans-UNet baseline enable segmentation of individual corallites from μCT scans of Porites coral colonies with reported Dice scores of 0.77 on same-colony slices and 0.63 on unrelated specimens.
-
DiffPhD: A Unified Differentiable Solver for Projective Heterogeneous Materials in Elastodynamics with Contact-Rich GPU-Acceleration
DiffPhD delivers a unified differentiable projective dynamics solver for heterogeneous hyperelastic elastodynamics with contact that achieves up to 10x speedup and stable convergence on 100x stiffness contrasts while ...
-
Convergence of difference inclusions via a diameter criterion
A diameter criterion tied to a potential function certifies convergence of difference inclusions, enabling discrete proofs for first-order optimization methods with diminishing steps.
-
Evolving Layer-Specific Scalar Functions for Hardware-Aware Transformer Adaptation
Genetic programming evolves heterogeneous layer-specific scalar functions to approximate layer normalization in pre-trained ViTs, capturing 91.6% variance versus 70.2% for uniform baselines and recovering 84.25% Image...
-
Unlocking Patch-Level Features for CLIP-Based Class-Incremental Learning
SPA unlocks patch-level features in CLIP for class-incremental learning via semantic-guided selection and optimal transport alignment with class descriptions, plus projectors and pseudo-feature replay to reduce forgetting.
-
QLAM: A Quantum Long-Attention Memory Approach to Long-Sequence Token Modeling
QLAM extends state-space models with quantum superposition in the hidden state for linear-time long-sequence modeling and reports consistent gains over RNN and transformer baselines on sequential image tasks.
-
MedCore: Boundary-Preserving Medical Core Pruning for MedSAM
MedCore achieves 60% parameter and 58.4% FLOP reduction on MedSAM with Dice 0.9549 and preserved boundary metrics via dual-intervention pruning and a new boundary leverage principle.
-
Sensing-Assisted LoS/NLoS Identification in Dynamic UAV Positioning Systems
A new dual-input feature fusion network using RGB images and channel impulse responses identifies LoS/NLoS conditions for UAVs with up to 97.69% accuracy and reduces trilateration positioning error by about 70%.
-
RotVLA: Rotational Latent Action for Vision-Language-Action Model
RotVLA models latent actions as continuous SO(n) rotations with triplet-frame supervision and flow-matching to reach 98.2% success on LIBERO and 89.6%/88.5% on RoboTwin2.0 using a 1.7B-parameter model.
-
KamonBench: A Grammar-Based Dataset for Evaluating Compositional Factor Recovery in Vision-Language Models
KamonBench is a grammar-based dataset of 20,000 synthetic Japanese crests with multi-format annotations that enables direct evaluation of factor recovery beyond caption accuracy in vision-language models.
-
KamonBench: A Grammar-Based Dataset for Evaluating Compositional Factor Recovery in Vision-Language Models
KamonBench is a grammar-generated synthetic dataset of compositional kamon crests with explicit factor annotations to evaluate factor recovery in vision-language models.
-
Backdoor Channels Hidden in Latent Space: Cryptographic Undetectability in Modern Neural Networks
Backdoors can be realized as statistically natural latent directions in modern neural networks, achieving high attack success with negligible clean accuracy loss and resisting existing defenses.
-
From Compression to Accountability: Harmless Copyright Protection for Dataset Distillation
SubPopMark embeds verifiable subpopulation biases into distilled datasets via CVM and USTM optimization stages, allowing provenance inference through comparison of model output signatures against a reference behavior bank.
-
From Compression to Accountability: Harmless Copyright Protection for Dataset Distillation
SubPopMark protects distilled datasets by injecting verifiable subpopulation biases that create distinguishable model behaviors for copyright tracing without using backdoors.
-
Runtime Monitoring of Perception-Based Autonomous Systems via Embedding Temporal Logic
Embedding Temporal Logic (ETL) performs runtime monitoring directly in learned embedding spaces using distance-based predicates composed with temporal operators, supported by conformal calibration for reliable predica...
-
Runtime Monitoring of Perception-Based Autonomous Systems via Embedding Temporal Logic
Embedding Temporal Logic enables runtime monitoring of temporally extended perceptual behaviors by defining predicates via distances between observed and reference embeddings in learned spaces, with conformal calibrat...
-
MindVLA-U1: VLA Beats VA with Unified Streaming Architecture for Autonomous Driving
MindVLA-U1 introduces a unified streaming VLA with shared backbone, framewise memory, and language-guided action diffusion that surpasses human drivers on WOD-E2E planning metrics.
-
From Imagined Futures to Executable Actions: Mixture of Latent Actions for Robot Manipulation
MoLA infers a mixture of latent actions from generated future videos via modality-aware inverse dynamics models to improve robot manipulation policies.
-
How Faithful Is Trajectory-Based Data Attribution? Error Sources, Remedies, and Practical Guidelines
The paper decomposes errors in trajectory-based data attribution into config, algorithm, and system levels, proposes AdamW-influence to fix optimizer mismatch, derives an error proxy for Taylor approximation, and unif...
-
Revisiting Shadow Detection from a Vision-Language Perspective
SVL uses language embeddings aligned with global image representations via shadow ratio regression and global-to-local coupling to improve shadow detection robustness in ambiguous cases.
-
Weather-Robust Cross-View Geo-Localization via Prototype-Based Semantic Part Discovery
SkyPart uses learnable prototypes for patch grouping, altitude modulation only in training, graph-attention readout, and Kendall-weighted loss to set new state-of-the-art single-pass performance on SUES-200, Universit...
-
SoK: Unlearnability and Unlearning for Model Dememorization
The first integrated taxonomy, empirical study of interplay and shallow dememorization, plus a theoretical guarantee on dememorization depth for certified unlearning.
-
TCP-SSM: Efficient Vision State Space Models with Token-Conditioned Poles
TCP-SSM conditions stable poles on visual tokens to explicitly control memory decay and oscillation in SSMs, cutting computation up to 44% while matching or exceeding accuracy on classification, segmentation, and detection.
-
Can Graphs Help Vision SSMs See Better?
GraphScan replaces geometric or coordinate-based scanning in Vision SSMs with learned local semantic graph routing, yielding SOTA results among such models on classification and segmentation tasks.
-
RelFlexformer: Efficient Attention 3D-Transformers for Integrable Relative Positional Encodings
RelFlexformers enable flexible integrable 3D RPE in attention via NU-FFT, generalizing prior methods to heterogeneous token positions with O(L log L) complexity.
-
Automated Detection of Abnormalities in Zebrafish Development
A new annotated dataset of zebrafish embryo image sequences enables a spatiotemporal transformer to classify fertility at 98% accuracy and detect compound-induced malformations at 92% accuracy.
-
The Benefits of Temporal Correlations: SGD Learns k-Juntas from Random Walks Efficiently
Temporal correlations from lazy random walks enable efficient SGD learning of k-juntas via temporal-difference loss on ReLU networks, achieving linear sample complexity in d.
-
Learning to Align Generative Appearance Priors for Fine-grained Image Retrieval
GAPan uses invertible normalizing flows to learn generative appearance priors from seen categories and aligns retrieval embeddings to these priors, improving performance on unseen categories in fine-grained image retrieval.
-
PromptDx: Differentiable Prompt Tuning for Multimodal In-Context Alzheimer's Diagnosis
PromptDx adds a differentiable adapter to align multimodal data with a pre-trained TabPFN-style ICL engine, achieving strong Alzheimer's diagnosis performance with only 1% context samples.
Reference graph
Works this paper leans on
-
[1]
Adaptive input representations for neural language modeling
9 Published as a conference paper at ICLR 2021 Alexei Baevski and Michael Auli. Adaptive input representations for neural language modeling. In ICLR,
work page 2021
-
[2]
Batch normalization: Accelerating deep network training by reducing internal covariate shift
10 Published as a conference paper at ICLR 2021 Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift
work page 2021
-
[3]
URL https://doi.org/10.1137/0330046
doi: 10.1137/0330046. URL https://doi.org/10.1137/0330046. Siyuan Qiao, Huiyu Wang, Chenxi Liu, Wei Shen, and Alan Yuille. Weight standardization. arXiv preprint arXiv:1903.10520,
-
[4]
Fixing the train-test resolution discrepancy
11 Published as a conference paper at ICLR 2021 Hugo Touvron, Andrea Vedaldi, Matthijs Douze, and Herve Jegou. Fixing the train-test resolution discrepancy. In NeurIPS
work page 2021
-
[5]
Fixing the train-test resolution discrepancy: Fixefficientnet
Hugo Touvron, Andrea Vedaldi, Matthijs Douze, and Herve Jegou. Fixing the train-test resolution discrepancy: Fixefficientnet. arXiv preprint arXiv:2003.08237,
-
[6]
Axial-deeplab: Stand-alone axial-attention for panoptic segmentation
Huiyu Wang, Yukun Zhu, Bradley Green, Hartwig Adam, Alan Yuille, and Liang-Chieh Chen. Axial-deeplab: Stand-alone axial-attention for panoptic segmentation. In ECCV, 2020a. Huiyu Wang, Yukun Zhu, Bradley Green, Hartwig Adam, Alan Yuille, and Liang-Chieh Chen. Axial-deeplab: Stand-alone axial-attention for panoptic segmentation. arXiv preprint arXiv:2003.0...
-
[7]
A Large-scale Study of Representation Learning with the Visual Task Adaptation Benchmark
Xiaohua Zhai, Avital Oliver, Alexander Kolesnikov, and Lucas Beyer. S4L: Self-Supervised Semi- Supervised Learning. In ICCV, 2019a. Xiaohua Zhai, Joan Puigcerver, Alexander Kolesnikov, Pierre Ruyssen, Carlos Riquelme, Mario Lucic, Josip Djolonga, Andre Susano Pinto, Maxim Neumann, Alexey Dosovitskiy, et al. A large-scale study of representation learning w...
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[8]
All models are trained with a batch size of 4096 and learn- ing rate warmup of 10k steps
12 Published as a conference paper at ICLR 2021 Models Dataset Epochs Base LR LR decay Weight decay Dropout ViT-B/{16,32} JFT-300M 7 8· 10−4 linear 0.1 0.0 ViT-L/32 JFT-300M 7 6· 10−4 linear 0.1 0.0 ViT-L/16 JFT-300M 7/14 4· 10−4 linear 0.1 0.0 ViT-H/14 JFT-300M 14 3· 10−4 linear 0.1 0.0 R50x{1,2} JFT-300M 7 10−3 linear 0.1 0.0 R101x1 JFT-300M 7 8· 10−4 l...
work page 2021
-
[9]
(2017)) is a popular building block for neural archi- tectures
APPENDIX A M ULTIHEAD SELF -ATTENTION Standard qkv self-attention (SA, Vaswani et al. (2017)) is a popular building block for neural archi- tectures. For each element in an input sequence z∈ RN×D, we compute a weighted sum over all values v in the sequence. The attention weights Aij are based on the pairwise similarity between two elements of the sequence...
work page 2017
-
[10]
For final results we train on the entire training set and evaluate on the respective test data
To do so, we use small sub-splits from the training set (10% for Pets and Flowers, 2% for CIFAR, 1% ImageNet) as development set and train on the remaining data. For final results we train on the entire training set and evaluate on the respective test data. For fine-tuning ResNets and hybrid models we use the exact same setup, with the only exception of Ima...
work page 2021
-
[11]
(2020) and select the best results across this run and our sweep
for ResNets we also run the setup of Kolesnikov et al. (2020) and select the best results across this run and our sweep. Finally, if not mentioned otherwise, all fine-tuning experiments run at 384 resolution (running fine-tuning at different resolution than training is common practice (Kolesnikov et al., 2020)). When transferring ViT models to another datas...
work page 2020
-
[12]
for all tasks. B.1.2 S ELF -SUPERVISION We employ the masked patch prediction objective for preliminary self-supervision experiments. To do so we corrupt 50% of patch embeddings by either replacing their embeddings with a learnable [mask] embedding (80%), a random other patch embedding (10%) or just keeping them as is (10%). This setup is very similar to ...
work page 2019
-
[13]
We also experimented with 15% corruption rate as used by Devlin et al
because it has shown best few-shot performance. We also experimented with 15% corruption rate as used by Devlin et al. (2019) but results were also slightly worse on our few-shot metrics. Lastly, we would like to remark that our instantiation of masked patch prediction doesn’t require such an enormous amount of pretraining nor a large dataset such as JFT ...
work page 2019
-
[14]
These correspond to Figure 5 in the main paper
Epochs ImageNet ImageNet ReaL CIFAR-10 CIFAR-100 Pets Flowers exaFLOPs name ViT-B/32 7 80.73 86.27 98.61 90.49 93.40 99.27 55 ViT-B/16 7 84.15 88.85 99.00 91.87 95.80 99.56 224 ViT-L/32 7 84.37 88.28 99.19 92.52 95.83 99.45 196 ViT-L/16 7 86.30 89.43 99.38 93.46 96.81 99.66 783 ViT-L/16 14 87.12 89.99 99.38 94.04 97.11 99.56 1567 ViT-H/14 14 88.08 90.36 9...
work page 2021
-
[15]
This justifies the choice of Adam as the optimizer used to pre-train ResNets on JFT
Adam pre-training outperforms SGD pre-training on most datasets and on average. This justifies the choice of Adam as the optimizer used to pre-train ResNets on JFT. Note that the absolute numbers are lower than those reported by Kolesnikov et al. (2020), since we pre-train only for 7 epochs, not
work page 2020
-
[16]
Figure 8 shows 5-shot performance on ImageNet for different configurations
D.2 T RANSFORMER SHAPE We ran ablations on scaling different dimensions of the Transformer architecture to find out which are best suited for scaling to very large models. Figure 8 shows 5-shot performance on ImageNet for different configurations. All configurations are based on a ViT model with8 layers,D = 1024, DM LP = 2048 and a patch size of 32, the inte...
work page 2048
-
[17]
D.4 P OSITIONAL EMBEDDING We ran ablations on different ways of encoding spatial information using positional embedding. We tried the following cases: • Providing no positional information: Considering the inputs as a bag of patches. • 1-dimensional positional embedding: Considering the inputs as a sequence of patches in the raster order (default across a...
work page 2021
-
[18]
is a simple, yet effective technique to run self- attention on large inputs that are organized as multidimensional tensors. The general idea of axial attention is to perform multiple attention operations, each along a single axis of the input tensor, instead of applying 1-dimensional attention to the flattened version of the input. In axial attention, each...
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.