HunyuanVideo: A Systematic Framework For Large Video Generative Models
Pith reviewed 2026-05-23 07:39 UTC · model grok-4.3
The pith
HunyuanVideo is an open-source video generation model with over 13 billion parameters that performs on par with or better than leading closed-source models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We trained a video generative model with over 13 billion parameters using a systematic framework that includes data curation, advanced architectural design, progressive model scaling and training, and efficient infrastructure, resulting in performance that matches or exceeds that of leading closed-source models according to professional evaluations.
What carries the argument
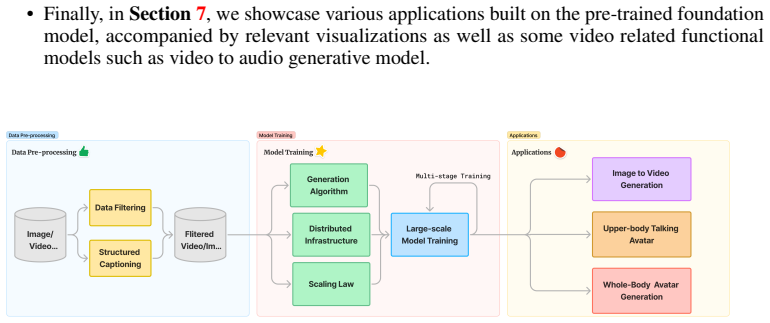
The comprehensive framework integrating data curation, advanced architectural design, progressive model scaling and training, and efficient infrastructure for large-scale model training and inference.
If this is right
- Open access to a high-performing video model allows researchers and developers to experiment and innovate without proprietary restrictions.
- The release enables community-driven improvements and applications in areas like content creation and simulation.
- It establishes a baseline for future open-source video models to build upon in terms of scale and quality.
- Bridging the performance gap encourages more collaborative development in the video generation field.
Where Pith is reading between the lines
- If the model generalizes well, it could accelerate adoption of video AI in smaller organizations and individual creators.
- Extensions might involve combining this with other AI tools for end-to-end video production pipelines.
- Testing on more diverse and challenging prompts could reveal specific strengths and limitations not covered in the initial evaluations.
Load-bearing premise
The professional evaluations used consistent, unbiased protocols with comparable generation settings across all compared models.
What would settle it
A controlled experiment with identical prompts and inference parameters where independent raters find no performance advantage for HunyuanVideo over the compared models.
Figures
























read the original abstract
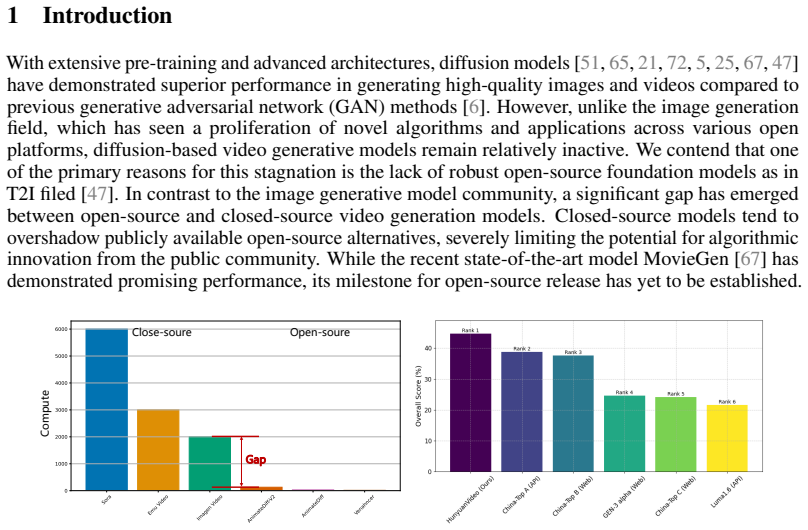
Recent advancements in video generation have significantly impacted daily life for both individuals and industries. However, the leading video generation models remain closed-source, resulting in a notable performance gap between industry capabilities and those available to the public. In this report, we introduce HunyuanVideo, an innovative open-source video foundation model that demonstrates performance in video generation comparable to, or even surpassing, that of leading closed-source models. HunyuanVideo encompasses a comprehensive framework that integrates several key elements, including data curation, advanced architectural design, progressive model scaling and training, and an efficient infrastructure tailored for large-scale model training and inference. As a result, we successfully trained a video generative model with over 13 billion parameters, making it the largest among all open-source models. We conducted extensive experiments and implemented a series of targeted designs to ensure high visual quality, motion dynamics, text-video alignment, and advanced filming techniques. According to evaluations by professionals, HunyuanVideo outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models. By releasing the code for the foundation model and its applications, we aim to bridge the gap between closed-source and open-source communities. This initiative will empower individuals within the community to experiment with their ideas, fostering a more dynamic and vibrant video generation ecosystem. The code is publicly available at https://github.com/Tencent/HunyuanVideo.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HunyuanVideo, an open-source video generative foundation model exceeding 13 billion parameters. It describes a systematic framework encompassing data curation, architectural design, progressive scaling and training, and large-scale infrastructure. The central claim is that the model achieves visual quality, motion dynamics, text-video alignment, and filming techniques comparable to or surpassing closed-source SOTA systems (Runway Gen-3, Luma 1.6, and three leading Chinese models) according to professional evaluations, with code released publicly to narrow the open/closed-source gap.
Significance. If the outperformance claim holds under reproducible conditions, the work would be significant as the largest open-source video generation model released to date, accompanied by code at https://github.com/Tencent/HunyuanVideo. This release constitutes a concrete contribution that could enable community experimentation and reduce the performance disparity with closed-source systems. The emphasis on a full training and inference pipeline for billion-parameter video models is a strength worth documenting.
major comments (2)
- [Abstract] Abstract: The assertion that HunyuanVideo 'outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models' according to professional evaluations is the load-bearing claim of the manuscript, yet no details are supplied on rater count, selection criteria, scoring rubric, inter-rater reliability, prompt sampling method, inference compute parity across models, or statistical testing. Without these elements the comparison cannot be evaluated for bias or reproducibility.
- [Abstract] Abstract: The statement that 'extensive experiments and a series of targeted designs' were used to achieve high visual quality, motion dynamics, text-video alignment, and advanced filming techniques is unsupported by any quantitative metrics, ablation tables, baseline comparisons, or error analysis in the manuscript. This omission prevents assessment of whether the described framework components are responsible for the claimed improvements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation claims. We address each major comment below and will revise the manuscript accordingly to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that HunyuanVideo 'outperforms previous state-of-the-art models, including Runway Gen-3, Luma 1.6, and three top-performing Chinese video generative models' according to professional evaluations is the load-bearing claim of the manuscript, yet no details are supplied on rater count, selection criteria, scoring rubric, inter-rater reliability, prompt sampling method, inference compute parity across models, or statistical testing. Without these elements the comparison cannot be evaluated for bias or reproducibility.
Authors: We agree that the professional evaluation details are essential for assessing reproducibility and potential biases. In the revised manuscript, we will add a new subsection under Experiments detailing the evaluation protocol. This will include the number of professional raters, their selection criteria and expertise, the scoring rubric, inter-rater reliability statistics (e.g., Cohen's kappa or similar), prompt sampling strategy, measures taken to align inference compute across models where feasible given closed-source constraints, and results of any statistical significance testing. revision: yes
-
Referee: [Abstract] Abstract: The statement that 'extensive experiments and a series of targeted designs' were used to achieve high visual quality, motion dynamics, text-video alignment, and advanced filming techniques is unsupported by any quantitative metrics, ablation tables, baseline comparisons, or error analysis in the manuscript. This omission prevents assessment of whether the described framework components are responsible for the claimed improvements.
Authors: We acknowledge that the current manuscript lacks quantitative metrics, ablation studies, and baseline comparisons to directly link specific design choices to the reported improvements. While the paper emphasizes the overall systematic framework, we will revise by adding an Experiments section with quantitative results, ablation tables for key components (e.g., data curation and architectural elements), baseline comparisons against prior models, and error analysis to better substantiate the contributions of the targeted designs. revision: yes
Circularity Check
No circularity: empirical model release with no derivation chain
full rationale
The manuscript reports training a 13B-parameter video model and claims outperformance via professional evaluations. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the provided text. The central claim rests on external human ratings rather than any internal reduction to inputs. Absence of evaluation protocol details is a transparency concern but does not constitute circularity under the defined patterns.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 60 Pith papers
-
AnyFlow: Any-Step Video Diffusion Model with On-Policy Flow Map Distillation
AnyFlow enables any-step video diffusion by distilling flow-map transitions over arbitrary time intervals with on-policy backward simulation.
-
TrackCraft3R: Repurposing Video Diffusion Transformers for Dense 3D Tracking
TrackCraft3R is the first method to repurpose a video diffusion transformer as a feed-forward dense 3D tracker via dual-latent representations and temporal RoPE alignment, achieving SOTA performance with lower compute.
-
Flow-GRPO: Training Flow Matching Models via Online RL
Flow-GRPO is the first online RL method for flow matching models, raising GenEval accuracy from 63% to 95% and text-rendering accuracy from 59% to 92% with little reward hacking.
-
Geo-Align: Video Generation Alignment via Metric Geometry Reward
Geo-Align applies RL with a perceptual reward derived from 3D camera trajectory estimation to improve controllability and fidelity in video generation without paired training data.
-
CRONOS: Benchmarking Counterfactual Physical Consistency in Video Models
CRONOS benchmark shows recent open-source video generators fail to preserve physical consistency under controlled changes to viewpoint, scene, object category, and appearance.
-
EM-Vid: Training-Free Entity-Centric Memory for Efficient and Consistent Multi-Shot Video Generation
EM-Vid introduces an entity-centric latent patch memory bank with sparse token conditioning and budgeted updates for training-free consistent multi-shot video generation.
-
DFSAttn: Dynamic Fine-grained Sparse Attention for Efficient Video Generation
DFSAttn is a training-free framework for dynamic fine-grained sparse attention in video DiTs that achieves up to 2.1x speedup while preserving generation quality via Hilbert reordering, hierarchical scoring, and adapt...
-
VDE: Training-Free Accelerating Rectified Flow Model via Velocity Decomposition and Estimation
VDE accelerates rectified flow models like Flux by 3.22x with LPIPS of 0.069 via velocity decomposition into parallel/orthogonal components plus periodic full-pass anchoring.
-
CoMoGen: COntrollable MOtion Dynamics and Interactions with Mask-Guided Video GENeration
CoMoGen generates controllable interactive video from mask sequences and images by encoding masks into MMDiT via MaskAdapter and LoRA on motion layers, claiming SOTA motion fidelity.
-
ORBIS: Output-Guided Token Reduction with Distribution-Aware Matching for Video Diffusion Acceleration
ORBIS uses output-guided token reduction and DATM to achieve 2x higher token reduction than AsymRnR, with up to 4.5x speedup and 79.3% energy savings versus A100 GPU for video DiT models.
-
Q-ARVD: Quantizing Autoregressive Video Diffusion Models
Q-ARVD introduces final-quality-aware frame weighting and outlier-aware adaptive dual-scale quantization to enable accurate low-bit inference for autoregressive video diffusion models.
-
What Semantics Survive the Connector? Diagnosing VLM-to-DiT Alignment in Video Editing
VLM-to-DiT alignment in video editing models acts as a semantic bottleneck that degrades fine-grained structural semantics, demonstrated via a new diagnostic dataset and protocol on relation-based edits.
-
MSAVBench: Towards Comprehensive and Reliable Evaluation of Multi-Shot Audio-Video Generation
MSAVBench is the first comprehensive benchmark for multi-shot audio-video generation, spanning video, audio, shot, and reference dimensions with an adaptive evaluation framework that reaches 91.5% Spearman correlation...
-
Aero-World: Action-Conditioned Aerial Video Generation from Inertial Controls
Aero-World adapts a pretrained latent diffusion transformer for action-conditioned aerial video generation by injecting inertial action tokens and using a frozen latent-space Physics Probe for inertial consistency sup...
-
PRISM: A Benchmark for Programmatic Spatial-Temporal Reasoning
PRISM benchmark of over 10k pairs shows LLMs have a 41% average drop from code execution success to spatial correctness in programmatic video generation.
-
InstructAV2AV: Instruction-Guided Audio-Video Joint Editing
InstructAV2AV is an end-to-end instruction-guided audio-video joint editing model that adapts a pre-trained backbone with gated attention and two-stage training, outperforming prior methods on 11 metrics after buildin...
-
StreamingEffect: Real-Time Human-Centric Video Effect Generation
StreamingEffect enables real-time 720p human-centric video effect generation on one GPU via teacher-student distillation, keyframe control, and a new 130K video dataset.
-
Accelerating Rectified Flow Models via Trajectory-Aware Caching
TACache accelerates rectified flow sampling up to 4.14x for text-to-image and 2.11x for text-to-video via offline skip scheduling from cumulative variation thresholds and online velocity reconstruction using historica...
-
Echo-Forcing: A Scene Memory Framework for Interactive Long Video Generation
Echo-Forcing decouples stable anchors, compressed history, and recent dynamics in video diffusion KV caches using hierarchical memory, scene recall frames, and difference-aware decay to support interactive long video ...
-
HASTE: Training-Free Video Diffusion Acceleration via Head-Wise Adaptive Sparse Attention
HASTE delivers up to 1.93x speedup on Wan2.1 video DiTs via head-wise adaptive sparse attention using temporal mask reuse and error-guided per-head calibration while preserving video quality.
-
TeDiO: Temporal Diagonal Optimization for Training-Free Coherent Video Diffusion
TeDiO regularizes temporal diagonals in diffusion transformer attention maps to produce smoother video motion while keeping per-frame quality intact.
-
Asymmetric Flow Models
Asymmetric Flow Modeling restricts noise prediction to a low-rank subspace for high-dimensional flow generation, reaching 1.57 FID on ImageNet 256x256 and new state-of-the-art pixel text-to-image performance via finet...
-
OmniNFT: Modality-wise Omni Diffusion Reinforcement for Joint Audio-Video Generation
OmniNFT introduces modality-wise advantage routing, layer-wise gradient surgery, and region-wise loss reweighting in an online diffusion RL framework to improve audio-video quality, alignment, and synchronization.
-
MoCam: Unified Novel View Synthesis via Structured Denoising Dynamics
MoCam unifies static and dynamic novel view synthesis by temporally decoupling geometric alignment and appearance refinement within the diffusion denoising process.
-
MoCam: Unified Novel View Synthesis via Structured Denoising Dynamics
MoCam uses structured denoising dynamics in diffusion models to temporally decouple geometric alignment from appearance refinement, enabling unified novel view synthesis that outperforms prior methods on imperfect poi...
-
CaC: Advancing Video Reward Models via Hierarchical Spatiotemporal Concentrating
CaC is a hierarchical spatiotemporal concentrating reward model for video anomalies that reports 25.7% accuracy gains on fine-grained benchmarks and 11.7% anomaly reduction in generated videos via a new dataset and GR...
-
HorizonDrive: Self-Corrective Autoregressive World Model for Long-horizon Driving Simulation
HorizonDrive enables stable long-horizon autoregressive driving simulation via anti-drifting teacher training with scheduled rollout recovery and teacher rollout distillation.
-
Detecting Deception, Not Deepfakes: Why Media Forensics Needs Social Theories
Deepfake detection must shift from classifying media realism to detecting communicative deception by applying Speech Act Theory, Grice's Cooperative Principle, and Cialdini's influence principles.
-
From Articulated Kinematics to Routed Visual Control for Action-Conditioned Surgical Video Generation
A kinematic-to-visual lifting paradigm combined with hierarchically routed control generates action-conditioned surgical videos with better faithfulness, fidelity, and efficiency.
-
OphEdit: Training-Free Text-Guided Editing of Ophthalmic Surgical Videos
OphEdit enables text-guided editing of eye surgery videos without training by injecting preserved attention value tensors into the diffusion denoising process to maintain anatomical structure.
-
DCR: Counterfactual Attractor Guidance for Rare Compositional Generation
DCR uses a counterfactual attractor and projection-based repulsion to suppress default completion bias in diffusion models, improving fidelity for rare compositional prompts while preserving quality.
-
FreeSpec: Training-Free Long Video Generation via Singular-Spectrum Reconstruction
FreeSpec uses SVD-based spectral reconstruction to fuse global low-rank and local high-rank features, reducing content drift and preserving temporal dynamics in long video generation.
-
Stream-R1: Reliability-Perplexity Aware Reward Distillation for Streaming Video Generation
Stream-R1 improves distillation of autoregressive streaming video diffusion models by adaptively weighting supervision with a reward model at both rollout and per-pixel levels.
-
AniMatrix: An Anime Video Generation Model that Thinks in Art, Not Physics
AniMatrix generates anime videos using a structured taxonomy of artistic production variables, dual-channel conditioning, a style-motion curriculum, and deformation-aware optimization to prioritize art over physics.
-
AniMatrix: An Anime Video Generation Model that Thinks in Art, Not Physics
AniMatrix generates anime videos using a production knowledge taxonomy, dual-channel conditioning, style-motion curriculum, and deformation-aware preference optimization, outperforming baselines in animator evaluation...
-
AniMatrix: An Anime Video Generation Model that Thinks in Art, Not Physics
AniMatrix generates anime videos by structuring artistic production rules into a controllable taxonomy and training the model to prioritize those rules over physical realism, achieving top scores from professional ani...
-
WorldJen: An End-to-End Multi-Dimensional Benchmark for Generative Video Models
WorldJen is a new benchmark for generative video models that uses VLM-judged multi-dimensional Likert questionnaires validated against human preferences to achieve perfect tier agreement.
-
DirectEdit: Step-Level Accurate Inversion for Flow-Based Image Editing
DirectEdit achieves step-level accurate inversion for flow-based image editing by directly aligning forward paths, using attention feature injection and mask-guided noise blending to balance fidelity and editability w...
-
VAnim: Rendering-Aware Sparse State Modeling for Structure-Preserving Vector Animation
VAnim creates open-domain text-to-SVG animations via sparse state updates on a persistent DOM tree, identification-first planning, and rendering-aware RL with a new 134k-example benchmark.
-
AsymTalker: Identity-Consistent Long-Term Talking Head Generation via Asymmetric Distillation
AsymTalker maintains identity consistency in long-term diffusion talking-head videos by encoding temporal references from a static image and training a student model under inference-like conditions via asymmetric dist...
-
Cutscene Agent: An LLM Agent Framework for Automated 3D Cutscene Generation
Cutscene Agent uses a multi-agent LLM system and a new toolkit for game engine control to automate end-to-end 3D cutscene generation, evaluated on the introduced CutsceneBench.
-
MuSS: A Large-Scale Dataset and Cinematic Narrative Benchmark for Multi-Shot Subject-to-Video Generation
MuSS is a new movie-sourced dataset and benchmark that enables AI models to generate multi-shot videos with improved narrative coherence and subject identity preservation.
-
MuSS: A Large-Scale Dataset and Cinematic Narrative Benchmark for Multi-Shot Subject-to-Video Generation
MuSS is a movie-derived dataset and benchmark that enables AI models to generate multi-shot videos with coherent narratives and preserved subject identity across shots.
-
FlowAnchor: Stabilizing the Editing Signal for Inversion-Free Video Editing
FlowAnchor stabilizes editing signals in flow-based inversion-free video editing via spatial-aware attention refinement and adaptive magnitude modulation for improved faithfulness and temporal coherence.
-
WorldMark: A Unified Benchmark Suite for Interactive Video World Models
WorldMark is the first public benchmark that standardizes scenes, trajectories, and control interfaces across heterogeneous interactive image-to-video world models.
-
Sparse Forcing: Native Trainable Sparse Attention for Real-time Autoregressive Diffusion Video Generation
Sparse Forcing adds a native trainable sparsity mechanism and PBSA kernel to autoregressive diffusion video models, yielding higher VBench scores and 1.1-1.27x speedups on 5s to 1min generations.
-
AttentionBender: Manipulating Cross-Attention in Video Diffusion Transformers as a Creative Probe
AttentionBender applies 2D transforms to cross-attention maps in video diffusion transformers, producing distributed distortions and glitch aesthetics that reveal entangled attention mechanisms while serving as both a...
-
ReImagine: Rethinking Controllable High-Quality Human Video Generation via Image-First Synthesis
ReImagine decouples human appearance from temporal consistency via pretrained image backbones, SMPL-X motion guidance, and training-free video diffusion refinement to generate high-quality controllable videos.
-
MultiWorld: Scalable Multi-Agent Multi-View Video World Models
MultiWorld is a scalable framework for multi-agent multi-view video world models that improves controllability and consistency over single-agent baselines in game and robot tasks.
-
UniGeo: Unifying Geometric Guidance for Camera-Controllable Image Editing via Video Models
UniGeo unifies geometric guidance across three levels in video models to reduce geometric drift and improve consistency in camera-controllable image editing.
-
Efficient Video Diffusion Models: Advancements and Challenges
A survey that groups efficient video diffusion methods into four paradigms—step distillation, efficient attention, model compression, and cache/trajectory optimization—and outlines open challenges for practical use.
-
UniEditBench: A Unified and Cost-Effective Benchmark for Image and Video Editing via Distilled MLLMs
UniEditBench unifies image and video editing evaluation with a nine-plus-eight operation taxonomy and cost-effective 4B/8B distilled MLLM evaluators that align with human judgments.
-
Flow of Truth: Proactive Temporal Forensics for Image-to-Video Generation
Flow of Truth is the first proactive temporal forensics framework for image-to-video generation that uses a learnable forensic template following pixel motion and a template-guided flow module to decouple motion from content.
-
Flow of Truth: Proactive Temporal Forensics for Image-to-Video Generation
Flow of Truth introduces a learnable forensic template and template-guided flow module that follows pixel motion to enable temporal tracing in image-to-video generation.
-
SOAR: Self-Correction for Optimal Alignment and Refinement in Diffusion Models
SOAR is a reward-free on-policy method that supplies dense per-timestep supervision to correct exposure bias in diffusion model denoising trajectories, raising GenEval from 0.70 to 0.78 and OCR from 0.64 to 0.67 over ...
-
LottieGPT: Tokenizing Vector Animation for Autoregressive Generation
LottieGPT tokenizes Lottie animations into compact sequences and fine-tunes Qwen-VL to autoregressively generate coherent vector animations from natural language or visual prompts, outperforming prior SVG models.
-
LayerCache: Exploiting Layer-wise Velocity Heterogeneity for Efficient Flow Matching Inference
LayerCache enables per-layer-group caching in flow matching models via adaptive JVP span selection and greedy 3D scheduling, delivering 1.37x speedup with PSNR 37.46 dB, SSIM 0.9834, and LPIPS 0.0178 on Qwen-Image.
-
Any 3D Scene is Worth 1K Tokens: 3D-Grounded Representation for Scene Generation at Scale
A 3D-grounded autoencoder and diffusion transformer allow direct generation of 3D scenes in an implicit latent space using a fixed 1K-token representation for arbitrary views and resolutions.
-
Immune2V: Image Immunization Against Dual-Stream Image-to-Video Generation
Immune2V immunizes images against dual-stream I2V generation by enforcing temporally balanced latent divergence and aligning generative features to a precomputed collapse trajectory, yielding stronger persistent degra...
-
Camera Artist: A Multi-Agent Framework for Cinematic Language Storytelling Video Generation
Camera Artist is a multi-agent framework introducing a Cinematography Shot Agent with recursive storyboard generation and cinematic language injection to improve narrative consistency and film quality in AI-generated ...
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023. 9
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Rohan Anil, Andrew M Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, et al. Palm 2 technical report. arXiv preprint arXiv:2305.10403, 2023. 9
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
All are worth words: A vit backbone for diffusion models
Fan Bao, Shen Nie, Kaiwen Xue, Yue Cao, Chongxuan Li, Hang Su, and Jun Zhu. All are worth words: A vit backbone for diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22669–22679, 2023. 9
work page 2023
-
[4]
Improving image generation with better captions
James Betker, Gabriel Goh, Li Jing, Tim Brooks, Jianfeng Wang, Linjie Li, Long Ouyang, Juntang Zhuang, Joyce Lee, Yufei Guo, et al. Improving image generation with better captions. Computer Science. https://cdn. openai. com/papers/dall-e-3. pdf, 2(3):8, 2023. 4
work page 2023
-
[5]
Stable video diffusion: Scaling latent video diffusion models to large datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint, 2023. 2, 27
work page 2023
-
[6]
Large Scale GAN Training for High Fidelity Natural Image Synthesis
Andrew Brock, Jeff Donahue, and Karen Simonyan. Large scale gan training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096, 2018. 2
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Homes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Wing Yin Ng, Ricky Wang, and Aditya Ramesh. Video generation models as world simulators. 2024. 4, 7, 27
work page 2024
-
[8]
Language Models are Few-Shot Learners
Tom B Brown. Language models are few-shot learners. arXiv preprint arXiv:2005.14165,
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[9]
ShareGPT4V: Improving Large Multi-Modal Models with Better Captions
Lin Chen, Jisong Li, Xiaoyi Dong, Pan Zhang, Conghui He, Jiaqi Wang, Feng Zhao, and Dahua Lin. Sharegpt4v: Improving large multi-modal models with better captions. arXiv preprint arXiv:2311.12793, 2023. 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Sharegpt4video: Improving video understanding and generation with better captions
Lin Chen, Xilin Wei, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Bin Lin, Zhenyu Tang, et al. Sharegpt4video: Improving video understanding and generation with better captions. arXiv preprint arXiv:2406.04325, 2024. 4
-
[11]
Od-vae: An omni-dimensional video compressor for improving latent video diffusion model
Liuhan Chen, Zongjian Li, Bin Lin, Bin Zhu, Qian Wang, Shenghai Yuan, Xing Zhou, Xinghua Cheng, and Li Yuan. Od-vae: An omni-dimensional video compressor for improving latent video diffusion model. arXiv preprint arXiv:2409.01199, 2024. 6
-
[12]
Follow-your-canvas: Higher-resolution video outpainting with extensive content generation
Qihua Chen, Yue Ma, Hongfa Wang, Junkun Yuan, Wenzhe Zhao, Qi Tian, Hongmei Wang, Shaobo Min, Qifeng Chen, and Wei Liu. Follow-your-canvas: Higher-resolution video outpainting with extensive content generation. arXiv preprint arXiv:2409.01055, 2024. 27
-
[13]
Neural ordinary differential equations
Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations. Advances in neural information processing systems, 31, 2018. 10
work page 2018
-
[14]
Panda-70m: Captioning 70m videos with multiple cross-modality teachers
Tsai-Shien Chen, Aliaksandr Siarohin, Willi Menapace, Ekaterina Deyneka, Hsiang-Wei Chao, Byung Eun Jeon, Yuwei Fang, Hsin-Ying Lee, Jian Ren, Ming-Hsuan Yang, and Sergey Tulyakov. Panda-70m: Captioning 70m videos with multiple cross-modality teachers. In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , page 13320–13331. IEEE, ...
work page 2024
-
[15]
Seine: Short-to-long video diffusion model for generative transition and prediction
Xinyuan Chen, Yaohui Wang, Lingjun Zhang, Shaobin Zhuang, Xin Ma, Jiashuo Yu, Yali Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. Seine: Short-to-long video diffusion model for generative transition and prediction. arXiv preprint, 2023. 27
work page 2023
-
[16]
EchoMimic: Lifelike Audio-Driven Portrait Animations through Editable Landmark Condi- tions,
Zhiyuan Chen, Jiajiong Cao, Zhiquan Chen, Yuming Li, and Chenguang Ma. Echomimic: Lifelike audio-driven portrait animations through editable landmark conditions. arXiv preprint arXiv:2407.08136, 2024. 23 29
-
[17]
Xtuner: A toolkit for efficiently fine-tuning llm
XTuner Contributors. Xtuner: A toolkit for efficiently fine-tuning llm. https://github. com/InternLM/xtuner, 2023. 8
work page 2023
-
[18]
OpenCV Developers. Opencv. https://opencv.org/. 3
- [19]
-
[20]
Lp-musiccaps: Llm-based pseudo music captioning
SeungHeon Doh, Keunwoo Choi, Jongpil Lee, and Juhan Nam. Lp-musiccaps: Llm-based pseudo music captioning. arXiv preprint arXiv:2307.16372, 2023. 19
-
[21]
Scaling rectified flow transform- ers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transform- ers for high-resolution image synthesis. In Forty-first International Conference on Machine Learning, 2024. 2, 8, 9, 10
work page 2024
-
[22]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021. 6
work page 2021
-
[23]
Peng Gao, Le Zhuo, Ziyi Lin, Chris Liu, Junsong Chen, Ruoyi Du, Enze Xie, Xu Luo, Longtian Qiu, Yuhang Zhang, et al. Lumina-t2x: Transforming text into any modality, resolution, and duration via flow-based large diffusion transformers. arXiv preprint arXiv:2405.05945, 2024. 9
-
[24]
YOLOX: Exceeding YOLO Series in 2021
Z Ge. Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430, 2021. 3
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[25]
Emu video: Factorizing text-to-video generation by explicit image conditioning
Rohit Girdhar, Mannat Singh, Andrew Brown, Quentin Duval, Samaneh Azadi, Sai Saketh Rambhatla, Akbar Shah, Xi Yin, Devi Parikh, and Ishan Misra. Emu video: Factorizing text-to-video generation by explicit image conditioning. arXiv preprint arXiv:2311.10709,
-
[26]
Chatglm: A family of large language models from glm-130b to glm-4 all tools, 2024
Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chenhui Zhang, Da Yin, Diego Rojas, Guanyu Feng, Hanlin Zhao, Hanyu Lai, Hao Yu, Hongning Wang, Jiadai Sun, Jiajie Zhang, Jiale Cheng, Jiayi Gui, Jie Tang, Jing Zhang, Juanzi Li, Lei Zhao, Lindong Wu, Lucen Zhong, Mingdao Liu, Minlie Huang, Peng Zhang, Qinkai Zheng, Rui Lu, Shuaiqi Duan, Shudan Zhang, Shulin Cao, ...
work page 2024
-
[27]
Sparsectrl: Adding sparse controls to text-to-video diffusion models
Yuwei Guo, Ceyuan Yang, Anyi Rao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Sparsectrl: Adding sparse controls to text-to-video diffusion models. arXiv preprint, 2023. 27
work page 2023
-
[28]
Animatediff: Animate your personalized text-to-image diffusion models without specific tuning
Yuwei Guo, Ceyuan Yang, Anyi Rao, Zhengyang Liang, Yaohui Wang, Yu Qiao, Maneesh Agrawala, Dahua Lin, and Bo Dai. Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. ICLR, 2024. 27
work page 2024
-
[29]
Taming data and transformers for audio generation
Moayed Haji-Ali, Willi Menapace, Aliaksandr Siarohin, Guha Balakrishnan, Sergey Tulyakov, and Vicente Ordonez. Taming data and transformers for audio generation. arXiv preprint arXiv:2406.19388, 2024. 19
-
[30]
Ring Attention with Blockwise Transformers for Near-Infinite Context
Pieter Abbeel Hao Liu, Matei Zaharia. Ring attention with blockwise transformers for near- infinite context. arXiv preprint arXiv:2310.01889, 2023. 14
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Animate-a-story: Storytelling with retrieval-augmented video generation
Yingqing He, Menghan Xia, Haoxin Chen, Xiaodong Cun, Yuan Gong, Jinbo Xing, Yong Zhang, Xintao Wang, Chao Weng, Ying Shan, et al. Animate-a-story: Storytelling with retrieval-augmented video generation. arXiv preprint, 2023. 27
work page 2023
-
[32]
J Ho, T Salimans, A Gritsenko, W Chan, M Norouzi, and DJ Fleet. Video diffusion models. arxiv 2022. arXiv preprint, 2022. 27
work page 2022
-
[33]
Imagen video: High definition video generation with diffusion models
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion models. arXiv preprint, 2022. 27 30
work page 2022
-
[34]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In NeurIPS, 2020. 10, 27
work page 2020
-
[35]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv preprint, 2022. 13
work page 2022
-
[36]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022. 8, 9, 10
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
Animate anyone: Consistent and controllable image-to-video synthesis for character animation
Li Hu, Xin Gao, Peng Zhang, Ke Sun, Bang Zhang, and Liefeng Bo. Animate anyone: Consistent and controllable image-to-video synthesis for character animation. arXiv preprint,
-
[38]
A large tv dataset for speech and music activity detection
Yun-Ning Hung, Chih-Wei Wu, Iroro Orife, Aaron Hipple, William Wolcott, and Alexander Lerch. A large tv dataset for speech and music activity detection. EURASIP Journal on Audio, Speech, and Music Processing, 2022(1):21, 2022. 18
work page 2022
-
[39]
General data protection regulation (gdpr), n.d
Investopedia. General data protection regulation (gdpr), n.d. Accessed October 10, 2023. 3
work page 2023
-
[40]
Text2performer: Text-driven human video generation
Yuming Jiang, Shuai Yang, Tong Liang Koh, Wayne Wu, Chen Change Loy, and Ziwei Liu. Text2performer: Text-driven human video generation. arXiv preprint, 2023. 27
work page 2023
-
[41]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020. 8, 9
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[42]
Computational tradeoffs in image synthesis: Diffusion, masked-token, and next-token prediction
Maciej Kilian, Varun Japan, and Luke Zettlemoyer. Computational tradeoffs in image synthesis: Diffusion, masked-token, and next-token prediction. arXiv preprint arXiv:2405.13218, 2024. 9
-
[43]
Re-ex: Revising after explanation reduces the factual errors in llm responses, 2024
Juyeon Kim, Jeongeun Lee, Yoonho Chang, Chanyeol Choi, Junseong Kim, and Jy yong Sohn. Re-ex: Revising after explanation reduces the factual errors in llm responses, 2024. 12
work page 2024
-
[44]
Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis
Jungil Kong, Jaehyeon Kim, and Jaekyoung Bae. Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis. Advances in neural information processing systems, 33:17022–17033, 2020. 19
work page 2020
-
[45]
Reducing activation recomputation in large transformer models
Vijay Anand Korthikanti, Jared Casper, Sangkug Lym, Lawrence McAfee, Michael Andersch, Mohammad Shoeybi, and Bryan Catanzaro. Reducing activation recomputation in large transformer models. Proceedings of Machine Learning and Systems, 5:341–353, 2023. 13
work page 2023
-
[46]
PKU-Yuan Lab and Tuzhan AI etc. Open-sora-plan, April 2024. 27
work page 2024
- [47]
-
[48]
Tccl: Co-optimizing collective communication and traffic routing for gpu-centric clusters
Baojia Li, Xiaoliang Wang, Jingzhu Wang, Yifan Liu, Yuanyuan Gong, Hao Lu, Weizhen Dang, Weifeng Zhang, Xiaojie Huang, Mingzhuo Chen, et al. Tccl: Co-optimizing collective communication and traffic routing for gpu-centric clusters. In Proceedings of the 2024 SIGCOMM Workshop on Networks for AI Computing, pages 48–53, 2024. 13
work page 2024
-
[49]
On the scalability of diffusion- based text-to-image generation
Hao Li, Yang Zou, Ying Wang, Orchid Majumder, Yusheng Xie, R Manmatha, Ashwin Swaminathan, Zhuowen Tu, Stefano Ermon, and Stefano Soatto. On the scalability of diffusion- based text-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9400–9409, 2024. 9
work page 2024
-
[50]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language- image pre-training for unified vision-language understanding and generation. In International conference on machine learning, pages 12888–12900. PMLR, 2022. 4
work page 2022
-
[51]
Zhimin Li, Jianwei Zhang, Qin Lin, Jiangfeng Xiong, Yanxin Long, Xinchi Deng, Yingfang Zhang, Xingchao Liu, Minbin Huang, Zedong Xiao, Dayou Chen, Jiajun He, Jiahao Li, Wenyue Li, Chen Zhang, Rongwei Quan, Jianxiang Lu, Jiabin Huang, Xiaoyan Yuan, Xiaoxiao Zheng, Yixuan Li, Jihong Zhang, Chao Zhang, Meng Chen, Jie Liu, Zheng Fang, Weiyan Wang, 31 Jinbao X...
work page 2024
-
[52]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. arXiv preprint arXiv:2210.02747, 2022. 2, 10
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[53]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. Advances in neural information processing systems, 36, 2024. 8
work page 2024
-
[54]
Diff-foley: Synchronized video- to-audio synthesis with latent diffusion models
Simian Luo, Chuanhao Yan, Chenxu Hu, and Hang Zhao. Diff-foley: Synchronized video- to-audio synthesis with latent diffusion models. Advances in Neural Information Processing Systems, 36, 2024. 19
work page 2024
-
[55]
Exploring the role of large language models in prompt encoding for diffusion models
Bingqi Ma, Zhuofan Zong, Guanglu Song, Hongsheng Li, and Yu Liu. Exploring the role of large language models in prompt encoding for diffusion models. arXiv preprint arXiv:2406.11831, 2024. 8
-
[56]
Follow your pose: Pose-guided text-to-video generation using pose-free videos
Yue Ma, Yingqing He, Xiaodong Cun, Xintao Wang, Ying Shan, Xiu Li, and Qifeng Chen. Follow your pose: Pose-guided text-to-video generation using pose-free videos. arXiv preprint,
-
[57]
Follow-your-click: Open-domain regional image animation via short prompts
Yue Ma, Yingqing He, Hongfa Wang, Andong Wang, Chenyang Qi, Chengfei Cai, Xiu Li, Zhifeng Li, Heung-Yeung Shum, Wei Liu, et al. Follow-your-click: Open-domain regional image animation via short prompts. arXiv preprint arXiv:2403.08268, 2024. 27
-
[58]
Follow-your-emoji: Fine-controllable and expressive freestyle portrait animation
Yue Ma, Hongyu Liu, Hongfa Wang, Heng Pan, Yingqing He, Junkun Yuan, Ailing Zeng, Chengfei Cai, Heung-Yeung Shum, Wei Liu, et al. Follow-your-emoji: Fine-controllable and expressive freestyle portrait animation. arXiv preprint arXiv:2406.01900, 2024. 23, 27
-
[59]
Some methods for classification and analysis of multivariate observations
J MacQueen. Some methods for classification and analysis of multivariate observations. In Proceedings of 5-th Berkeley Symposium on Mathematical Statistics and Probability/University of California Press, 1967. 3
work page 1967
-
[60]
On distillation of guided diffusion models
Chenlin Meng, Robin Rombach, Ruiqi Gao, Diederik Kingma, Stefano Ermon, Jonathan Ho, and Tim Salimans. On distillation of guided diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14297–14306,
-
[61]
Conditional image-to-video generation with latent flow diffusion models
Haomiao Ni, Changhao Shi, Kai Li, Sharon X Huang, and Martin Renqiang Min. Conditional image-to-video generation with latent flow diffusion models. In CVPR, 2023. 27
work page 2023
-
[62]
Angel-ptm: A scalable and economical large-scale pre-training system in tencent
Xiaonan Nie, Yi Liu, Fangcheng Fu, Jinbao Xue, Dian Jiao, Xupeng Miao, Yangyu Tao, and Bin Cui. Angel-ptm: A scalable and economical large-scale pre-training system in tencent. arXiv preprint arXiv:2303.02868, 2023. 13
- [63]
- [64]
-
[65]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195–4205, 2023. 2, 9
work page 2023
-
[66]
Sdxl: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint, 2023. 8, 11
work page 2023
-
[67]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih-Yao Ma, Ching-Yao Chuang, et al. Movie gen: A cast of media foundation models. arXiv preprint arXiv:2410.13720, 2024. 2, 5, 6, 7, 13, 19, 27
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[68]
A lip sync expert is all you need for speech to lip generation in the wild
KR Prajwal, Rudrabha Mukhopadhyay, Vinay P Namboodiri, and CV Jawahar. A lip sync expert is all you need for speech to lip generation in the wild. In Proceedings of the 28th ACM international conference on multimedia, pages 484–492, 2020. 22 32
work page 2020
-
[69]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, 2021. 8
work page 2021
-
[70]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In ICML, pages 8748–8763. PMLR, 2021. 19
work page 2021
-
[71]
Exploring the limits of transfer learning with a unified text-to-text transformer
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research, 21(140):1–67, 2020. 8, 10, 19
work page 2020
-
[72]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In CVPR, 2022. 2, 27
work page 2022
-
[73]
Progressive Distillation for Fast Sampling of Diffusion Models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. arXiv preprint arXiv:2202.00512, 2022. 10
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[74]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053, 2019. 13
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[75]
Make-a-video: Text-to-video generation without text-video data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, et al. Make-a-video: Text-to-video generation without text-video data. arXiv preprint, 2022. 27
work page 2022
-
[76]
arXiv preprint arXiv:2008.04838 (2020)
Tomáš Souˇcek and Jakub Lokoˇc. Transnet v2: An effective deep network architecture for fast shot transition detection. arXiv preprint arXiv:2008.04838, 2020. 3
-
[77]
Roformer: Enhanced transformer with rotary position embedding, 2023
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding, 2023. 8
work page 2023
-
[78]
Hunyuan-large: An open-source moe model with 52 billion activated parameters by tencent, 2024
Xingwu Sun, Yanfeng Chen, Yiqing Huang, Ruobing Xie, Jiaqi Zhu, Kai Zhang, Shuaipeng Li, Zhen Yang, Jonny Han, Xiaobo Shu, Jiahao Bu, Zhongzhi Chen, Xuemeng Huang, Fengzong Lian, Saiyong Yang, Jianfeng Yan, Yuyuan Zeng, Xiaoqin Ren, Chao Yu, Lulu Wu, Yue Mao, Tao Yang, Suncong Zheng, Kan Wu, Dian Jiao, Jinbao Xue, Xipeng Zhang, Decheng Wu, Kai Liu, Dengpe...
work page 2024
-
[79]
Mochi 1: A new sota in open-source video generation
Genmo Team. Mochi 1: A new sota in open-source video generation. https://github. com/genmoai/models, 2024. 7, 27
work page 2024
-
[80]
Linrui Tian, Qi Wang, Bang Zhang, and Liefeng Bo. Emo: Emote portrait alive – generating expressive portrait videos with audio2video diffusion model under weak conditions, 2024. 22
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.