Holistic Evaluation of Language Models
Pith reviewed 2026-05-24 10:04 UTC · model grok-4.3
The pith
Language models are now densely benchmarked on the same 42 scenarios and 7 metrics under standardized conditions for all 30 models evaluated.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
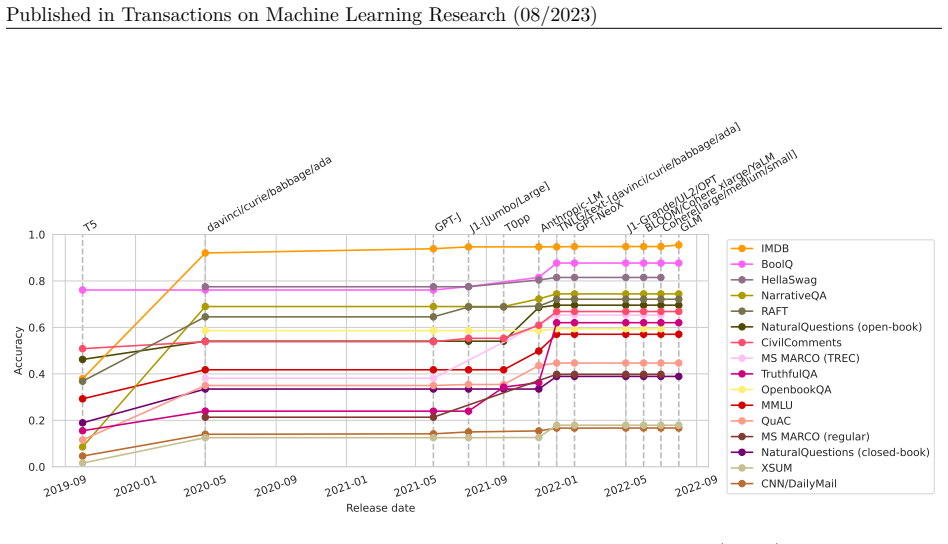
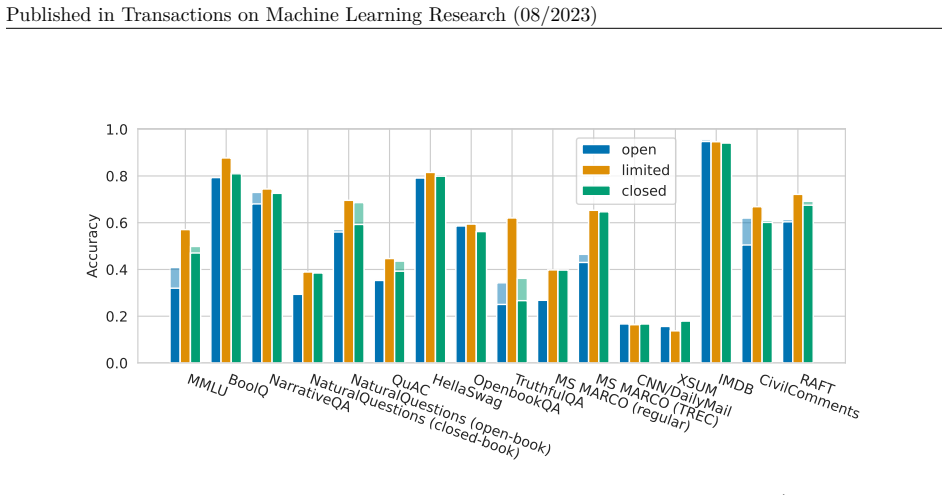
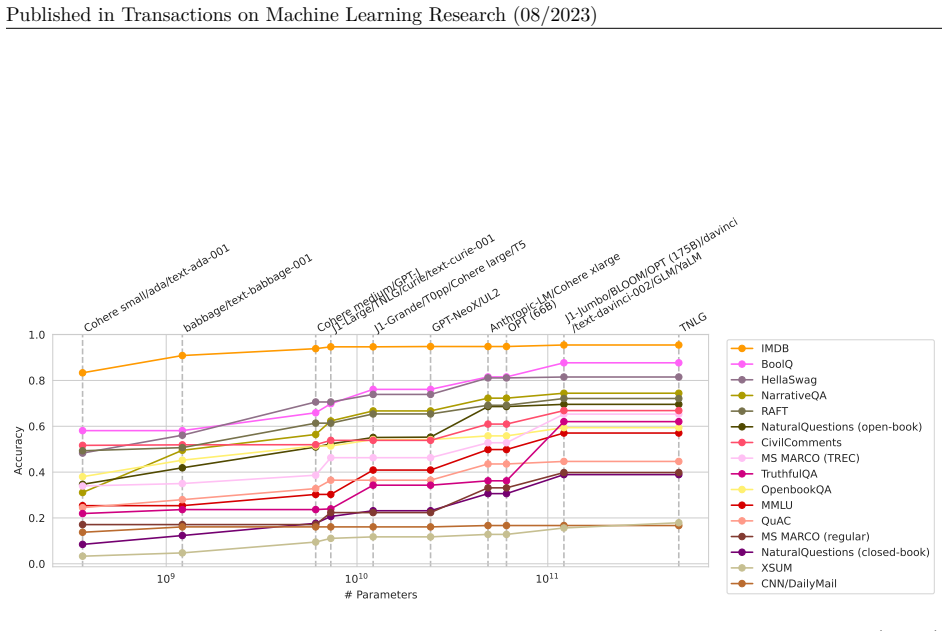
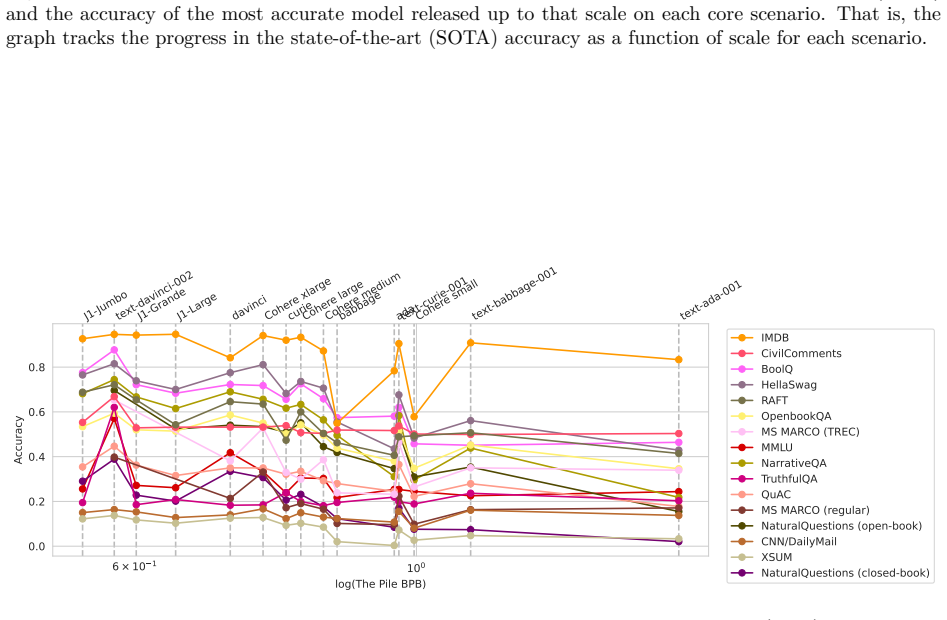
HELM taxonomizes the vast space of scenarios and metrics for language models, selects a broad subset based on coverage and feasibility while noting missing areas, adopts a multi-metric approach measuring seven metrics on sixteen core scenarios when possible, performs seven targeted evaluations, and conducts a large-scale evaluation of thirty prominent language models on all forty-two scenarios, improving coverage to 96 percent and surfacing twenty-five top-level findings, with full release of raw data and a modular toolkit.
What carries the argument
The HELM taxonomy of scenarios (use cases) and metrics (desiderata) combined with a multi-metric measurement protocol that applies accuracy plus six additional metrics to each core scenario.
If this is right
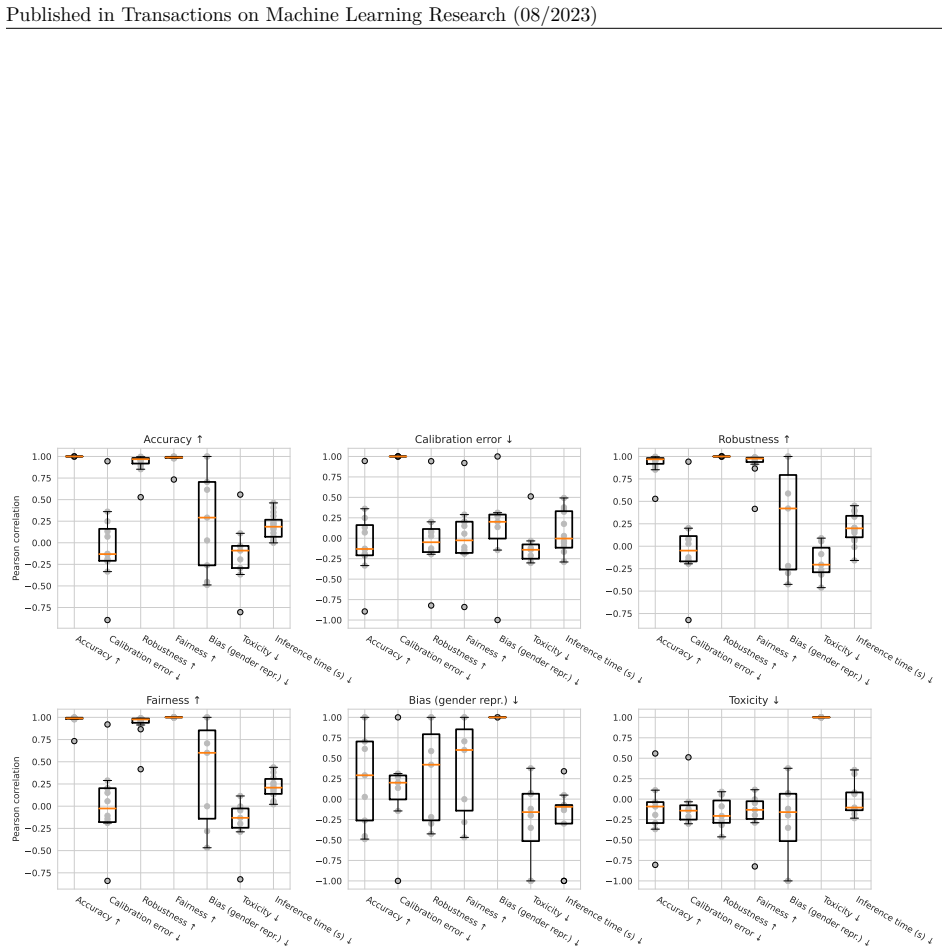
- Trade-offs across the seven metrics become visible for every model rather than accuracy alone determining perceived quality.
- All thirty models can be compared directly because they share the same core scenarios and metrics under identical conditions.
- Twenty-one previously unused scenarios enter mainstream evaluation, expanding the range of tested capabilities.
- The released raw prompts and completions enable independent further analysis by the community.
- A modular toolkit supports continuous addition of new scenarios, metrics, and models as a living benchmark.
Where Pith is reading between the lines
- Developers might shift focus from maximizing accuracy to balancing multiple metrics when the standardized results show consistent trade-offs.
- The public data release could support targeted studies on specific failure modes that the top-level findings only flag.
- The approach of noting explicit gaps in the taxonomy could encourage parallel efforts to fill areas like trustworthiness metrics.
- Similar taxonomy-plus-multi-metric structures might apply to evaluating other foundation models beyond language.
Load-bearing premise
The chosen subset of scenarios and metrics is broad enough to give a holistic view of model capabilities, limitations, and risks even with acknowledged gaps in coverage.
What would settle it
Repeating the full set of evaluations on the same thirty models but with an alternate selection of scenarios that still meets the coverage criteria produces substantially different top-level findings or model rankings.
Figures




















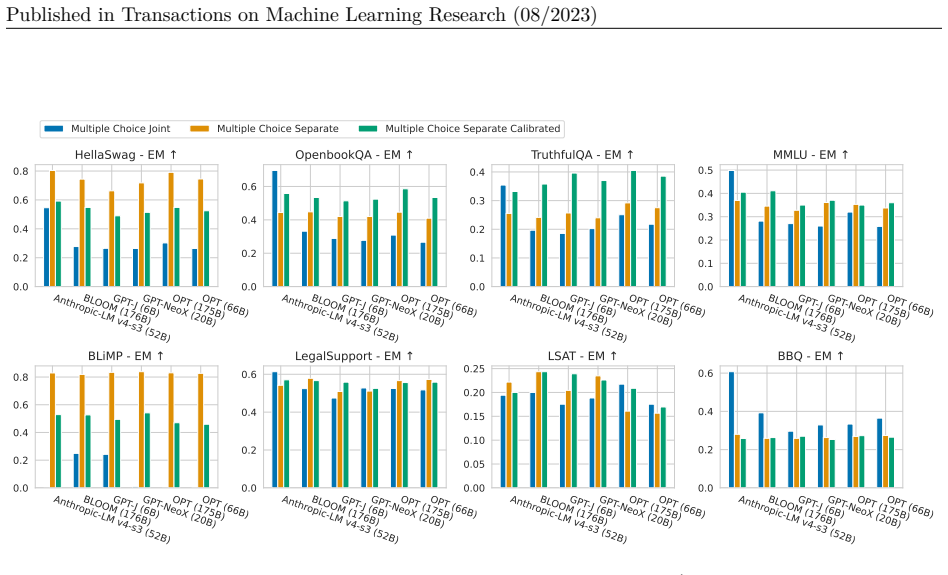



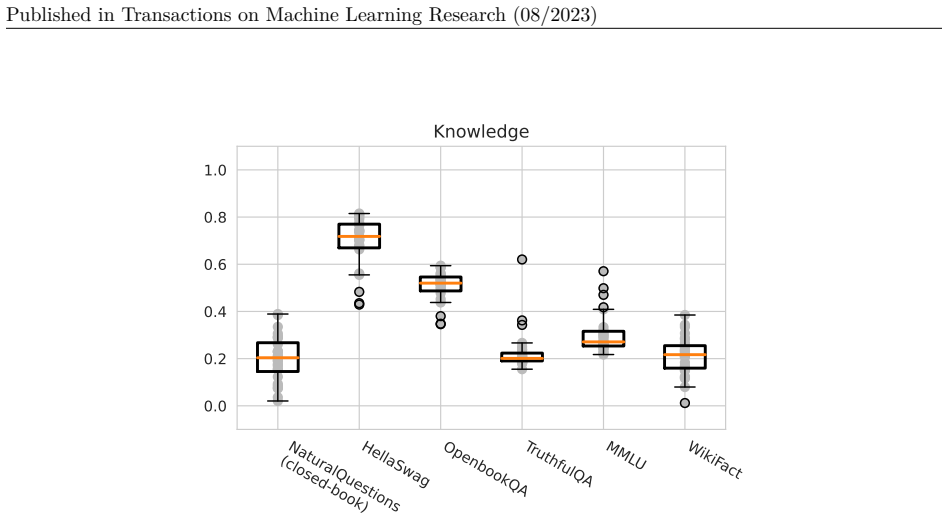


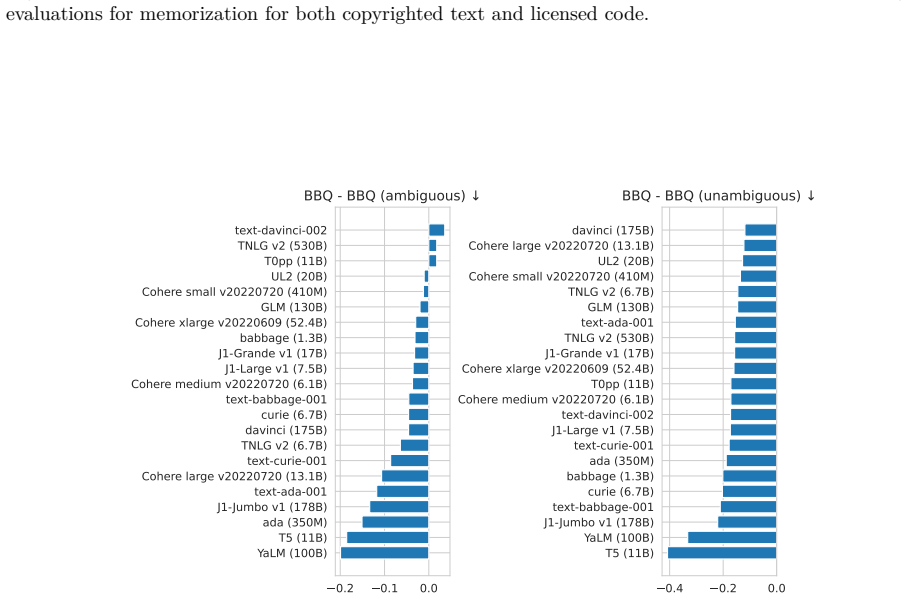
read the original abstract
Language models (LMs) are becoming the foundation for almost all major language technologies, but their capabilities, limitations, and risks are not well understood. We present Holistic Evaluation of Language Models (HELM) to improve the transparency of language models. First, we taxonomize the vast space of potential scenarios (i.e. use cases) and metrics (i.e. desiderata) that are of interest for LMs. Then we select a broad subset based on coverage and feasibility, noting what's missing or underrepresented (e.g. question answering for neglected English dialects, metrics for trustworthiness). Second, we adopt a multi-metric approach: We measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency) for each of 16 core scenarios when possible (87.5% of the time). This ensures metrics beyond accuracy don't fall to the wayside, and that trade-offs are clearly exposed. We also perform 7 targeted evaluations, based on 26 targeted scenarios, to analyze specific aspects (e.g. reasoning, disinformation). Third, we conduct a large-scale evaluation of 30 prominent language models (spanning open, limited-access, and closed models) on all 42 scenarios, 21 of which were not previously used in mainstream LM evaluation. Prior to HELM, models on average were evaluated on just 17.9% of the core HELM scenarios, with some prominent models not sharing a single scenario in common. We improve this to 96.0%: now all 30 models have been densely benchmarked on the same core scenarios and metrics under standardized conditions. Our evaluation surfaces 25 top-level findings. For full transparency, we release all raw model prompts and completions publicly for further analysis, as well as a general modular toolkit. We intend for HELM to be a living benchmark for the community, continuously updated with new scenarios, metrics, and models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HELM, a framework for holistic evaluation of language models. It first taxonomizes the space of scenarios (use cases) and metrics (desiderata), then selects a feasible subset of 16 core scenarios and 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, efficiency) for multi-metric evaluation (achieved 87.5% of the time). It evaluates 30 models (open, limited-access, closed) on these plus 26 targeted scenarios, achieving 96% dense coverage on the core set (up from prior average of 17.9%), surfaces 25 top-level findings, and releases all raw prompts, completions, and a modular toolkit.
Significance. If the results hold, this provides a substantial advance in standardized, multi-metric LM evaluation that exposes trade-offs and improves transparency over prior fragmented benchmarks. Explicit credit is due for the public release of raw model outputs and the modular toolkit, which directly support reproducibility and community extensions. The documented gaps (e.g., QA for neglected dialects, trustworthiness metrics) and the 96% coverage claim are presented as concrete improvements rather than exhaustive holism.
major comments (1)
- [evaluation section / abstract] The central coverage claim (96.0% on 16 core scenarios across all 30 models) is a direct measurement and load-bearing for the contribution, but the manuscript should clarify in the evaluation section how the prior 17.9% average was computed (e.g., which models and scenarios were included in the baseline calculation) to allow readers to assess the improvement magnitude.
minor comments (4)
- [abstract] Abstract: the 87.5% multi-metric figure is stated without noting it corresponds to 14 out of 16 scenarios; adding this parenthetical would improve immediate clarity.
- [abstract / introduction] The 25 top-level findings are referenced but not summarized or enumerated in the abstract or introduction; a concise bullet list or table reference would help readers locate the key outputs.
- [taxonomy section] Notation for scenarios and metrics is introduced in the taxonomy section but could benefit from a single consolidated table early in the paper to reduce cross-referencing.
- [targeted evaluations section] The targeted evaluations (7 evaluations on 26 scenarios) are described at a high level; a brief table mapping each targeted evaluation to its scenarios and metrics would aid navigation.
Simulated Author's Rebuttal
We thank the referee for their positive assessment and recommendation for minor revision. We address the major comment below.
read point-by-point responses
-
Referee: [evaluation section / abstract] The central coverage claim (96.0% on 16 core scenarios across all 30 models) is a direct measurement and load-bearing for the contribution, but the manuscript should clarify in the evaluation section how the prior 17.9% average was computed (e.g., which models and scenarios were included in the baseline calculation) to allow readers to assess the improvement magnitude.
Authors: We agree that providing more detail on the baseline would improve clarity. The 17.9% average was computed by surveying the published evaluations of the 30 models against the 16 core scenarios prior to HELM (i.e., counting how many of the 16 scenarios each model had been evaluated on in the literature, then averaging). In the revised manuscript we will add an explicit paragraph in the evaluation section describing this survey methodology, the sources consulted, and the per-model counts that underlie the average. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's central claims consist of (1) a taxonomy and feasibility-based selection of scenarios/metrics with explicit documentation of gaps, (2) direct empirical measurements of 7 metrics across 16 core scenarios for 30 models, and (3) descriptive coverage statistics (e.g., prior 17.9% to 96.0% dense benchmarking). These are factual outputs of running the evaluations under standardized conditions, not quantities derived from or fitted to the results themselves. No equations, parameter fitting, self-citation chains, or uniqueness theorems appear in the derivation; the 25 findings are reported measurements rather than premises. The selection process is presented as an improvement over prior fragmentation with acknowledged incompleteness, rendering the evaluation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- Choice of 16 core scenarios
- Choice of 7 metrics
axioms (1)
- domain assumption Standardized evaluation conditions produce comparable and meaningful metric values across open, limited-access, and closed models.
Forward citations
Cited by 60 Pith papers
-
Unsteady Metrics and Benchmarking Cultures of AI Model Builders
AI model builders mostly highlight unique benchmarks that act as flexible narrative tools for market positioning rather than standardized scientific measurements.
-
EnergyAgentBench: Benchmarking LLM Agents on Live Energy Infrastructure Data
EnergyAgentBench is a new benchmark with 70 task variants that evaluates LLM agents on live energy data for datacenter siting, long-horizon optimization, and causal grid diagnosis.
-
A Benchmark for Strategic Auditee Gaming Under Continuous Compliance Monitoring
Continuous auditing creates an unavoidable cover regime in which static auditors cannot simultaneously eliminate coverage and granularity failures, shown via new policies, strategies, and a reproducible simulator.
-
MCP-Atlas: A Large-Scale Benchmark for Tool-Use Competency with Real MCP Servers
MCP-Atlas is a new benchmark with 1000 tasks on production MCP servers that uses claim-level scoring to evaluate LLM agents on realistic multi-step tool-use competency.
-
Robotics-Inspired Guardrails for Foundation Models in Socially Sensitive Domains
Introduces the Grounded Observer framework that applies robotics-inspired formal constructs for runtime constraint enforcement on foundation model interaction trajectories in socially sensitive domains.
-
GRASP: Deterministic argument ranking in interaction graphs
GRASP aggregates stable local LLM interaction judgments into global argument rankings via a convergent attack-defense propagation operator on interaction graphs, yielding higher reproducibility than holistic judging a...
-
SpikeProphecy: A Large-Scale Benchmark for Autoregressive Neural Population Forecasting
SpikeProphecy decomposes spike-count forecasting performance into temporal fidelity, spatial pattern accuracy, and magnitude-invariant alignment, revealing reproducible brain-region predictability rankings and a sub-P...
-
Causal Bias Detection in Generative Artificial Intelligence
Develops a causal framework unifying generative AI fairness with standard ML, with new decompositions, identification conditions, and estimators demonstrated on LLM race and gender bias.
-
HEBATRON: A Hebrew-Specialized Open-Weight Mixture-of-Experts Language Model
Hebatron is the first open-weight Hebrew MoE LLM adapted from Nemotron-3, reaching 73.8% on Hebrew reasoning benchmarks while activating only 3B parameters per pass and supporting 65k-token context.
-
Causal Stories from Sensor Traces: Auditing Epistemic Overreach in LLM-Generated Personal Sensing Explanations
LLMs routinely produce unsupported causal stories for personal sensing anomalies, and richer evidence or constrained prompts do not reliably eliminate this epistemic overreach.
-
CXR-ContraBench: Benchmarking Negated-Option Attraction in Medical VLMs
Medical VLMs frequently select negated options that contradict visible chest X-ray findings, achieving only ~30% accuracy on direct presence probes, but a post-hoc consistency verifier raises accuracy above 95%.
-
iTRIALSPACE: Programmable Virtual Lesion Trials for Controlled Evaluation of Lung CT Models
iTRIALSPACE generates realistic virtual lesion trials on lung CTs that isolate performance drivers and show strong transfer of model rankings to real clinical data (ρ=0.93).
-
LLMSpace: Carbon Footprint Modeling for Large Language Model Inference on LEO Satellites
LLMSpace is the first framework to jointly model operational and embodied carbon for LLM inference on LEO satellites, incorporating radiation-hardened hardware, peripheral systems, and workload patterns such as prefil...
-
LLMSpace: Carbon Footprint Modeling for Large Language Model Inference on LEO Satellites
LLMSpace is the first modeling framework that jointly calculates operational and embodied carbon emissions for LLM inference on LEO satellites, incorporating radiation-hardened hardware, peripheral systems, and LLM wo...
-
Coral: Cost-Efficient Multi-LLM Serving over Heterogeneous Cloud GPUs
Coral cuts multi-LLM serving costs by up to 2.79x and raises goodput by up to 2.39x on heterogeneous GPUs through adaptive joint optimization and a lossless two-stage decomposition that solves quickly.
-
The Partial Testimony of Logs: Evaluation of Language Model Generation under Confounded Model Choice
An identification theorem shows that a randomized experiment and simulator together recover causal model values from confounded logs, with logs used only afterward to reduce estimation error.
-
TRIP-Evaluate: An Open Multimodal Benchmark for Evaluating Large Models in Transportation
TRIP-Evaluate is a new open multimodal benchmark with 837 text, image, and point-cloud items organized by a role-task-knowledge taxonomy to evaluate large models on transportation workflows.
-
A Systematic Survey of Security Threats and Defenses in LLM-Based AI Agents: A Layered Attack Surface Framework
A new 7x4 taxonomy organizes agentic AI security threats by architectural layer and persistence timescale, revealing under-explored upper layers and missing defenses after surveying 116 papers.
-
SPASM: Stable Persona-driven Agent Simulation for Multi-turn Dialogue Generation
SPASM introduces a stability-first framework with Egocentric Context Projection to maintain consistent personas and eliminate echoing in multi-turn LLM agent dialogues.
-
An Agentic Evaluation Architecture for Historical Bias Detection in Educational Textbooks
An agentic architecture with multimodal screening, a five-agent jury, meta-synthesis, and source attribution protocol detects biases in Romanian history textbooks more accurately than zero-shot baselines, achieving 83...
-
MCP-Atlas: A Large-Scale Benchmark for Tool-Use Competency with Real MCP Servers
MCP-Atlas introduces a benchmark of 36 real MCP servers, 220 tools, and 1,000 natural-language tasks to measure LLM tool-use competency in multi-server workflows.
-
PlotChain: Deterministic Checkpointed Evaluation of Multimodal LLMs on Engineering Plot Reading
PlotChain benchmark reports top MLLMs reaching ~80% field-level accuracy on engineering plot reading under human-like tolerances, but with persistent failures on frequency-domain tasks like bandpass and FFT spectra.
-
Results-Actionability Gap: Understanding How Practitioners Evaluate LLM Products in the Wild
Qualitative study of 19 practitioners reveals ten LLM product evaluation practices and introduces the results-actionability gap as a key barrier to turning findings into improvements.
-
Automatic Replication of LLM Mistakes in Medical Conversations
MedMistake automatically generates 3,390 single-shot QA pairs capturing LLM mistakes in medical conversations, with expert validation on a 211-question subset showing performance differences among 12 frontier models.
-
Classification Trees with Valid Inference via the Exponential Mechanism
Classification trees built with the exponential mechanism generate asymptotically valid inference pivots from sampling probabilities without major accuracy loss.
-
Rethinking Predictive Modeling for LLM Routing: When Simple kNN Beats Complex Learned Routers
A well-tuned kNN router matches or exceeds state-of-the-art learned routers on new standardized benchmarks spanning instruction, QA, reasoning, and the first multi-modal visual routing dataset, due to locality of mode...
-
PRIMETIME : Limits of LLMs in Temporal Primitives
PRIMETIME generator reveals that LLM datetime parsing and arithmetic primitives are individually unreliable but fully learnable via fine-tuning, enabling frontier-level accuracy on event planning with small LoRA models.
-
GAIA: a benchmark for General AI Assistants
GAIA benchmark shows humans at 92% accuracy on simple real-world questions far outperform current AI systems at 15%, proposing this gap as a key milestone for general AI.
-
QLoRA: Efficient Finetuning of Quantized LLMs
QLoRA finetunes 4-bit quantized LLMs via LoRA adapters to match full-precision performance while using far less memory, enabling 65B-scale training on single GPUs and producing Guanaco models near ChatGPT level.
-
Language Models Don't Always Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting
Chain-of-thought explanations in LLMs are frequently unfaithful: models systematically omit mention of biasing prompt features that change their answers and instead produce rationalizations for those biased outputs.
-
Contractual Skills: A GovernSpec Design Framework for Enterprise AI Agents
The paper introduces contractual skills as a GovernSpec-inspired framework for AI agent SKILL.md files and evaluates it in text-generation and tool-calling experiments showing gains in checkability over baselines.
-
Mem-$\pi$: Adaptive Memory through Learning When and What to Generate
Mem-π is a framework using a dedicated model and decision-content decoupled RL to generate context-specific guidance on demand for LLM agents, outperforming retrieval baselines by over 30% on web navigation.
-
Causal Bias Detection in Generative Artificial Intelligence
A causal framework unifies fairness analysis across generative AI and standard ML by deriving decompositions that separate biases along causal pathways and differences between real-world and model mechanisms.
-
Continuous Discovery of Vulnerabilities in LLM Serving Systems with Fuzzing
GRIEF fuzzer finds 15 vulnerabilities including 2 CVEs in vLLM and SGLang by testing concurrent workloads for KV-cache isolation failures and cross-request interference.
-
Navigating the Sea of LLM Evaluation: Investigating Bias in Toxicity Benchmarks
Toxicity benchmarks for LLMs produce inconsistent results when task type, input domain, or model changes, revealing intrinsic evaluation biases.
-
OPT-BENCH: Evaluating the Iterative Self-Optimization of LLM Agents in Large-Scale Search Spaces
OPT-BENCH and OPT-Agent evaluate LLM self-optimization in large search spaces, showing stronger models improve via feedback but stay constrained by base capacity and below human performance.
-
Towards Apples to Apples for AI Evaluations: From Real-World Use Cases to Evaluation Scenarios
A repeatable worksheet and human-reviewed expansion process turns expert-elicited AI use cases into 107 grounded scenarios to support consistent human-centered evaluations.
-
Query-efficient model evaluation using cached responses
DKPS-based methods leverage cached model responses to achieve equivalent benchmark prediction accuracy with substantially fewer queries than standard evaluation.
-
ModelLens: Finding the Best for Your Task from Myriads of Models
ModelLens learns a performance-aware latent space from 1.62M leaderboard records to rank unseen models on unseen datasets without forward passes on the target.
-
When Stress Becomes Signal: Detecting Antifragility-Compatible Regimes in Multi-Agent LLM Systems
CAFE finds positive distributional Jensen Gaps across five multi-agent LLM architectures under semantic stress, showing that quality drops can coexist with detectable stress geometry compatible with antifragile learning.
-
When Stress Becomes Signal: Detecting Antifragility-Compatible Regimes in Multi-Agent LLM Systems
CAFE detects positive distributional Jensen Gaps across five multi-agent LLM architectures on a banking-risk benchmark, showing that quality drops under semantic stress can coexist with statistically detectable antifr...
-
A Meta Reinforcement Learning Approach to Goals-Based Wealth Management
MetaRL pre-trained on GBWM problems delivers near-optimal dynamic strategies in 0.01s achieving 97.8% of DP optimal utility and handles larger problems where DP fails.
-
What Single-Prompt Accuracy Misses: A Multi-Variant Reliability Audit of Language Models
Multi-variant testing reveals that prompt design and evaluator choices can change apparent model reliability by large margins, with verbal confidence often overstated and robustness uncorrelated with size.
-
Evaluating Agentic AI in the Wild: Failure Modes, Drift Patterns, and a Production Evaluation Framework
The paper presents a taxonomy of seven production-specific failure modes for agentic AI, demonstrates that existing metrics fail to detect four of them entirely, and proposes the PAEF five-dimension framework for cont...
-
Compared to What? Baselines and Metrics for Counterfactual Prompting
Counterfactual prompting effects on LLMs are often indistinguishable from those caused by meaning-preserving paraphrases, causing most previously reported demographic sensitivities to disappear under proper statistica...
-
Learning to Route Queries to Heads for Attention-based Re-ranking with Large Language Models
RouteHead trains a lightweight router to dynamically select optimal LLM attention heads per query for improved attention-based document re-ranking.
-
Programming with Data: Test-Driven Data Engineering for Self-Improving LLMs from Raw Corpora
Structured knowledge extracted from corpora enables test-driven data engineering for LLMs by mapping training data to source code, model training to compilation, benchmarking to unit testing, and failures to targeted ...
-
Are Large Language Models Economically Viable for Industry Deployment?
Small LLMs under 2B parameters achieve better economic break-even, energy efficiency, and hardware density than larger models on legacy GPUs for industrial tasks.
-
Beyond Static Snapshots: A Grounded Evaluation Framework for Language Models at the Agentic Frontier
ISOPro replaces learned reward models with deterministic verifiers in a continuous evaluation setup for LLMs, delivering larger average capability gains than GRPO-LoRA across small models in scheduling and MBPP domain...
-
Dataset-Level Metrics Attenuate Non-Determinism: A Fine-Grained Non-Determinism Evaluation in Diffusion Language Models
Dataset-level metrics in diffusion language models mask substantial sample-level non-determinism that varies with model and system factors, which a new Factor Variance Attribution metric can decompose.
-
The A-R Behavioral Space: Execution-Level Profiling of Tool-Using Language Model Agents in Organizational Deployment
Execution and refusal in tool-using LLM agents form separable behavioral dimensions whose joint distribution shifts systematically with normative regimes and autonomy scaffolding.
-
BERT-as-a-Judge: A Robust Alternative to Lexical Methods for Efficient Reference-Based LLM Evaluation
BERT-as-a-Judge fine-tunes a BERT encoder on synthetic question-candidate-reference triplets to judge answer correctness, outperforming lexical baselines and matching larger LLM judges across 36 models and 15 tasks.
-
AICA-Bench: Holistically Examining the Capabilities of VLMs in Affective Image Content Analysis
AICA-Bench evaluates 23 VLMs on affective image analysis, identifies weak intensity calibration and shallow descriptions as limitations, and proposes training-free Grounded Affective Tree Prompting to improve performance.
-
SysTradeBench: An Iterative Build-Test-Patch Benchmark for Strategy-to-Code Trading Systems with Drift-Aware Diagnostics
SysTradeBench evaluates 17 LLMs on 12 trading strategies, finding over 91.7% code validity but rapid convergence in iterative fixes and a continued need for human oversight on critical strategies.
-
Evaluating Artificial Intelligence Through a Christian Understanding of Human Flourishing
Frontier AI models default to procedural secularism and score 17 points lower on Christian human-flourishing criteria than on pluralistic ones, with a 31-point gap in faith and spirituality.
-
Measuring Representation Robustness in Large Language Models for Geometry
LLMs display accuracy gaps of up to 14 percentage points on the same geometry problems solely due to representation choice, with vector forms consistently weakest and a convert-then-solve prompt helping only high-capa...
-
Beyond Benchmark Islands: Toward Representative Trustworthiness Evaluation for Agentic AI
Defines agentic trustworthiness via five properties and proposes HAAF, a scenario-distribution framework with a Trustworthy Optimization Factory that transfers interventions across 13 models from seven families on a 1...
-
Preconditioned Test-Time Adaptation for Out-of-Distribution Debiasing in Narrative Generation
CAP-TTA triggers context-aware preconditioned LoRA updates on high bias-risk OOD prompts to reduce toxicity in LLM narrative generation while preserving fluency and avoiding catastrophic forgetting.
-
Evaluating Reliability Gaps in Large Language Model Safety via Repeated Prompt Sampling
Repeated sampling of the same safety prompts reveals substantial differences in LLM failure probabilities across temperatures that conventional single-evaluation benchmarks miss.
-
Where Relevance Emerges: A Layer-Wise Study of Internal Attention for Zero-Shot Re-Ranking
Internal attention in LLMs shows a bell-curve relevance distribution across layers, enabling Selective-ICR that cuts inference latency 30-50% and lets an 8B zero-shot model match 14B RL re-rankers on BRIGHT.
Reference graph
Works this paper leans on
-
[1]
Language Models are Few-Shot Learners
Association for Computational Linguistics. doi: 10.18653/v1/2021.naacl-main.385. URL https: //www.aclweb.org/anthology/2021.naacl-main.385. Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom He...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2021.naacl-main.385 2021
-
[2]
doi: 10.18653/v1/2021.acl-long.150
Association for Computational Linguistics. doi: 10.18653/v1/2021.acl-long.150. URL https: //aclanthology.org/2021.acl-long.150. Frieda Goldman-Eisler. Speech production and the predictability of words in context.Quarterly Journal of Experimental Psychology, 10(2):96–106, 1958. doi: 10.1080/17470215808416261. URLhttps://doi.org/ 10.1080/17470215808416261. ...
-
[3]
URLhttps://glottolog.org/accessed2021-08-08
doi: 10.5281/zenodo.4761960. URLhttps://glottolog.org/accessed2021-08-08. Yiding Hao, William Merrill, Dana Angluin, Robert Frank, Noah Amsel, Andrew Benz, and Simon Mendel- sohn. Context-free transductions with neural stacks.EMNLP 2018, pp. 306, 2018. Gilbert Harman. Rationality. John Wiley & Sons, Ltd, 2013. Junxian He, Chunting Zhou, Xuezhe Ma, Taylor ...
-
[4]
Measuring Coding Challenge Competence With APPS
URL https://openreview.net/forum?id=0RDcd5Axok. Pengcheng He, Xiaodong Liu, Jianfeng Gao, and Weizhu Chen. {DEBERTA}: {DECODING}-{enhanced} {bert} {with} {disentangled} {attention}. InInternational Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=XPZIaotutsD. 95 Published in Transactions on Machine Learning Research (08/20...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2021.eacl-main.225 2021
-
[5]
URL https://www.oxfordhandbooks.com/view/10.1093/oxfordhb/9780199286546.001.0001/ oxfordhb-9780199286546-e-6. Abigail Z. Jacobs and Hanna Wallach. Measurement and fairness. InProceedings of the 2021 Conference on Fairness, Accountability, and Transparency, FAccT ’21, New York, NY, USA, 2021. Association for Computing Machinery. URLhttps://arxiv.org/abs/19...
-
[6]
doi: https://doi.org/10.1016/j.cognition.2007.05.006. URL https://www.sciencedirect.com/ science/article/pii/S0010027707001436. Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and co...
-
[7]
The Natural Language Decathlon: Multitask Learning as Question Answering
doi: 10.2466/pr0.1957.3.3.635. URLhttps://doi.org/10.2466/pr0.1957.3.3.635. Floyd G. Lounsburg. Transitional probability, linguistic structure and systems of habitfamily hierarchies. Psycholinguistics: a survey of theory and research, 1954. Henry P. Luhn. The automatic creation of literature abstracts.IBM Journal of Research and Development, 2:159–165, 19...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.2466/pr0.1957.3.3.635 1957
-
[8]
Red Teaming Language Models with Language Models
ISSN 2474-7394. URL https://online.ucpress.edu/collabra/article/7/1/25293/117809/ A-Practical-Guide-to-Doing-Behavioral-Research-on . 25293. Ethan Perez, Douwe Kiela, and Kyunghyun Cho. True few-shot learning with language models. In M. Ran- zato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan (eds.),Advances in Neural Information Processi...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Measuring and Narrowing the Compositionality Gap in Language Models
Association for Computational Linguistics. URLhttps://www.aclweb.org/anthology/P19-1101. Geoff Pleiss, Manish Raghavan, Felix Wu, Jon Kleinberg, and Kilian Q. Weinberger. On fairness and calibration. In Advances in Neural Information Processing Systems (NeurIPS), pp. 5684–5693, 2017. Christopher Potts, Zhengxuan Wu, Atticus Geiger, and Douwe Kiela. DynaSe...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/s11229-022-03791-y 2017
-
[10]
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
doi: 10.48550/ARXIV.2211.05100. URLhttps://arxiv.org/abs/2211.05100. Anna Schmidt and Michael Wiegand. A survey on hate speech detection using natural language processing. In Proceedings of the Fifth International Workshop on Natural Language Processing for Social Media, pp. 1–10, Valencia, Spain, April 2017. Association for Computational Linguistics. doi...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2211.05100 2017
-
[11]
doi: 10.1145/2460276.2460278. URLhttp://doi.acm.org/10.1145/2460276.2460278. Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian Goodfellow, and Rob Fergus. Intriguing properties of neural networks. InInternational Conference on Learning Representations (ICLR), 2014. Benedikt Szmrecsanyi, Jason Grafmiller, and Laura Rosseel...
-
[12]
Dialect Perturbation: We currently support conversions between Standard American English (SAE) and African American English (AAE) using the mapping between lexical terms provided by Ziems et al. (2022)
work page 2022
-
[13]
Gender Pronoun Perturbation: We support conversions between the gender neutral and gendered pronouns from Lauscher et al. (2022)
work page 2022
-
[14]
Gender Term Perturbation: We convert gender terms of a source gender (e.g. “Grandfather”) to their counterparts in a target gender (e.g. “Grandmother”). We build our mapping by improving the union of the mappings from Garg et al. (2018) and Bolukbasi et al. (2016)
work page 2018
-
[15]
(2017), which derives its list form Greenwald et al
FirstNamePerturbation: Weconvertfirstnamesinasourceraceorgendertothoseinthetargetrace or gender, using the names from Caliskan et al. (2017), which derives its list form Greenwald et al. (1998). The associations between demographic category and name are derived from US Census statistics; we note that these statistical relationships may also not be invaria...
work page 2017
-
[16]
(2018), which derives its list form Chalabi & Flowers (2017)
Last Name Perturbation: We convert last names in a source race to those in the target race, using the last names from Garg et al. (2018), which derives its list form Chalabi & Flowers (2017). See the above discussion of the relationship between names and demographic information; we also note that the frequent instance of name change through marriage is po...
work page 2018
-
[17]
subset of the scenario looks like: “It came from down here.” “What were you thinking bringing a stranger here?” “... look out for herself.” “I wouldn’t be alive if it wasn’t for her.” “Yeah, well, I’m protecting you now.” The textual output of a language model should be the same with the input. The main metric for the scenario is bits per byte (BPB). Data...
work page 2020
-
[18]
markup for the text itself,
-
[19]
parenthetical annotations provided by the authors, and 143 Published in Transactions on Machine Learning Research (08/2023)
work page 2023
-
[20]
speaker tags for the spoken texts. Tags in the first category are removed with the enclosed text intact; tags in the second category are removed along with the enclosed text; and speaker tags are left as-is. The final preprocessed texts average 2046 tokens using the GPT-2 tokenizer. Data Resources. This dataset is not made available through our benchmark;...
work page 2046
-
[21]
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
B+-A, 144 Published in Transactions on Machine Learning Research (08/2023) Relation IDRelation Name PromptArtP136 genre The genre of [X] is a/anP1303 instrument The musical instrument [X] plays isP50 author The author of [X] isP170 creator The creator of [X] isP86 composer The composer of [X] isP57 director The director of [X] isLawP1001 applies to jurisd...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.